
## OpenLedger ($OPEN): Solving the Sovereign Data Crisis for Specialized AI
The AI narrative in Web3 is quickly moving away from superficial wrapper tokens toward foundational infrastructure. As general-purpose Large Language Models (LLMs) face diminishing returns due to data scraping bottlenecks, the next competitive frontier belongs to **specialized, domain-specific AI**.
This is exactly where **OpenLedger introduces a structural solution, acting as a purpose-built L1/L2 data layer that brings data attribution, validation, and execution directly on-chain.
the Architecture: Moving Beyond Black-Box AI
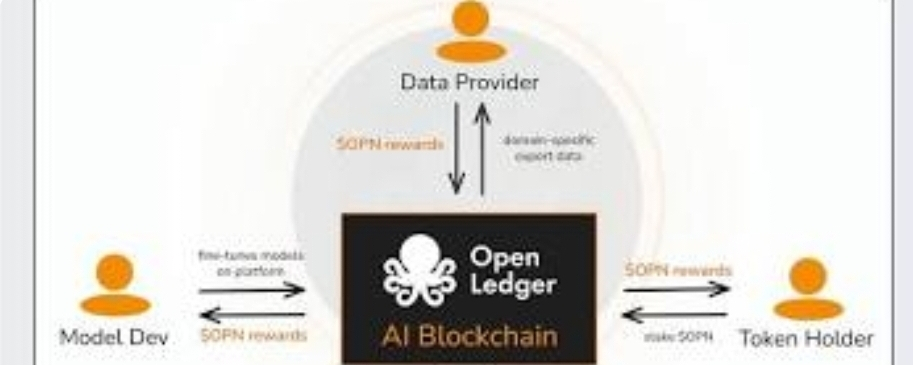
In the current Web2 landscape, data contributors and model fine-tuners rarely capture the economic value they generate. OpenLedger restructures this lifecycle through three core, decentralized pillars:
* **Datanets:** Community-driven networks designed to harvest, clean, and validate specialized datasets (e.g., medical diagnostics, smart contract risk patterns). Instead of a static database, Datanets act as active, composable training grounds.
* **ModelFactory:** A no-code execution layer allowing developers to plug Datanets into foundational LLMs to create tailored AI models with verifiable provenance.
* **OpenLoRA & Proof of Attribution:** A deployment engine optimizing hardware costs alongside a custom cryptographic mechanism. Every time a specialized model executes a task, the protocol traces the inference back to its exact data source, distributing programmatic rewards to the original data contributors.
comparative Analysis: Infrastructure Quality Matrix
| Feature Focus | OpenLedger Network | Legacy AI Data Protocols |
| **Data Provenance** | Immutable, On-Chain Traceability | Centralized, Opaque Repositories |
| **Monetization Track** | Granular Proof of Attribution | Bulk Licensing / All-or-Nothing Fees |
| **Hardware Overhead** | OpenLoRA (Multi-model GPU scaling) | Siloed, High-Cap Compute Requirements |
| **Ecosystem Flow** | Native Utility (Fees, Staking, Gov) | Web2 Fiat Subscriptions |
### Understanding the Macro Value Flow
The token economics of $OPEN are designed around network utilization rather than pure speculation. As specialized models become necessary tools for decentralized physical infrastructure networks (DePIN) and predictive decentralized finance (DeFi), the velocity of the $OPEN token relies on real economic loops:
[Data Contributors] ---> (Datanets Deployment) ---> [ModelFactory Optimization]
^ |
| v
[Programmatic Rewards] <--- (Proof of Attribution) <--- [Inference & API Calls]
> **Deep-Dive Perspective:** The structural moat for OpenLedger isn't just about decentralized compute; it’s about **verifiable data supply chains**. In an era plagued by data synthetic poisoning and deepfakes, the capacity to audit the lifecycle of an AI model from raw data package to end-user inference is no longer an option—it is a critical requirement for institutional adoption
**How do you see decentralized data layers competing with enterprise cloud monopolies over the next 12 to 24 months? Let’s map out the technical logic in the comments below.**