Most AI-chain talk still feels like someone taped a GPU sticker onto an old financial chain and called it infrastructure. Cute. Very industry. Very expensive PowerPoint behavior. But the real issue isn’t branding. It’s whether the chain can actually represent how AI is made, changed, reused, audited, and paid for without turning the whole system into a clogged sink.
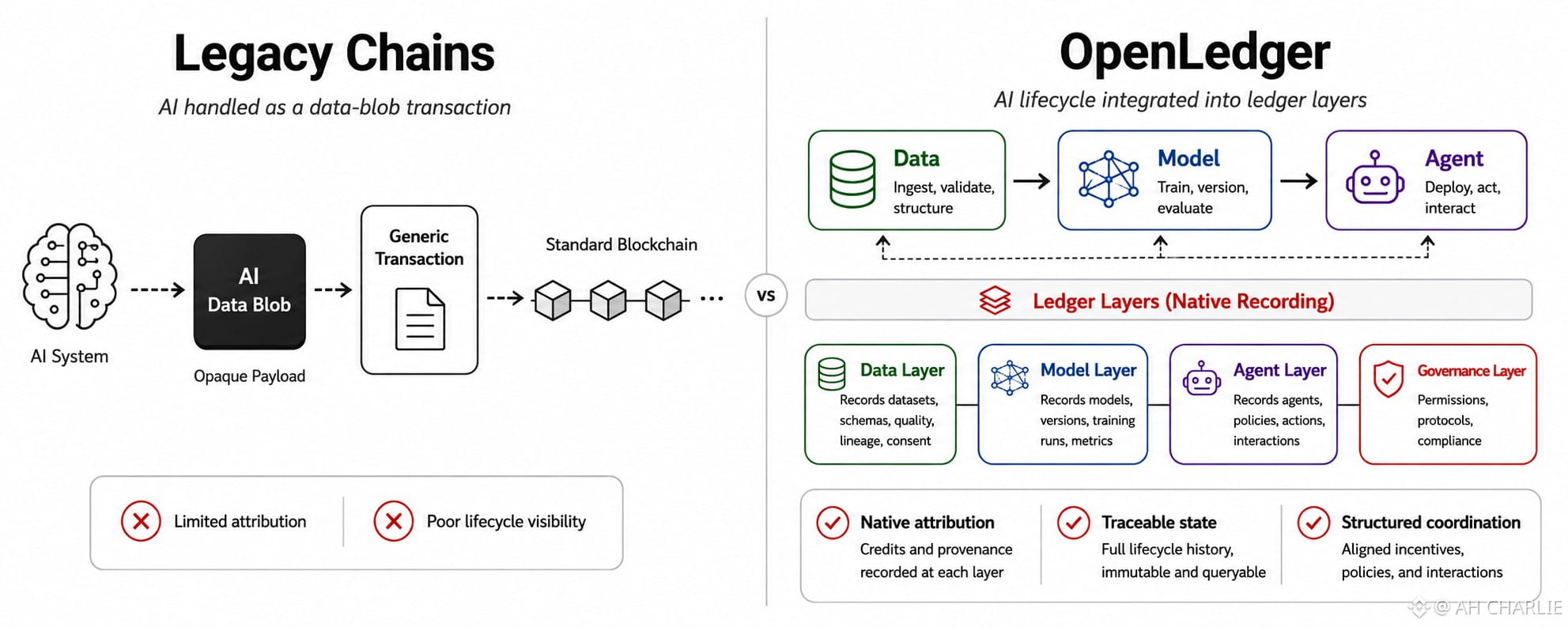
OpenLedger’s stronger claim is that AI doesn’t need another general-purpose execution layer with a themed landing page. It needs native attribution. That means the protocol doesn’t treat data, models, contributors, and version history like side notes living in smart contract event logs. It treats them as first-class state. Base-level objects. Things the chain itself understands.
That matters because AI production isn’t a clean financial transfer. It’s messy. A dataset gets cleaned. A model gets trained. A contributor adds domain input. Another layer filters bad output. A later version uses part of the old work.

Then someone needs to know who added what, when, and whether that contribution still matters.

Try forcing all of that through a chain designed mainly for token movement and DeFi logic. You can do it, sure, the same way you can use a kitchen knife as a screwdriver. Technically possible. Ugly after five minutes.
The retrofit model has one core weakness: it pushes AI-specific logic outside the base system.

Attribution becomes an app-layer patch. Coordination becomes a contract maze. Incentives become a spreadsheet wearing a blockchain costume. And governance? That turns into a trust exercise, which is funny, because the whole point was to reduce trust assumptions, not move them behind a curtain and hope nobody checks.
This is where the native-built argument gets sharper. If attribution is a protocol primitive, then model lineage can be tracked closer to the source.

Structured data flows can become recorded state transitions, not scattered breadcrumbs. Version control can stop being an off-chain promise and start becoming part of the settlement surface.
Like a factory where every part has a serial mark stamped into the metal, not scribbled on a sticky note by someone who may or may not still work there.
But I’m not going to pretend this is clean magic. It isn’t. Recording contribution trails at high resolution creates overhead. A lot of it. Every data change, model update, validation step, or usage path adds weight. If the system records too little, attribution becomes weak. If it records too much, throughput starts sweating through its shirt. That’s the core engineering tension.

The boring part is the important part, because Everyone keep trying to escape boring details and then act shocked when systems break. State management becomes the real battleground here. Compression, batching, proof design, indexing, and selective settlement matter more than the public narrative. A native AI chain that can’t manage state bloat becomes a museum of perfect records nobody can afford to use.
That’s why I see OpenLedger’s thesis less as “AI on-chain” and more as “AI lifecycle accountability.” Different animal. It’s not about slapping compute claims onto a chain. It’s about whether contributors, data assets, model versions, and incentive flows can be coordinated without creating a black box with prettier branding.
General-purpose chains weren’t built for that full lifecycle. They were built around financial state, asset movement, execution logic, and broad composability.

Strong tools, but not sacred tools. When the workload changes, the base assumptions matter. AI has attribution density. It has recursive reuse. It has unclear ownership surfaces. It has many small inputs that can matter later. That kind of system needs a ledger that can track provenance without drowning in its own honesty.
Still, native design doesn’t automatically mean superior design. That’s another lazy trap. A purpose-built chain can still fail if it over-records, under-indexes, or makes contributor rewards too hard to verify in practice. The market doesn’t need poetic architecture. It needs working coordination under load.
OpenLedger is aiming at the gap between AI production and blockchain settlement. If it can make attribution cheap, verifiable, and usable at scale, then the native-built thesis has teeth. If not, it becomes another elegant diagram sacrificed to throughput, latency, and operational cost. Blockchain history has a large graveyard for systems that sounded correct in theory and moved like furniture in practice.
So the question isn’t “Is OpenLedger an AI chain?” That’s too shallow.
Can it track contribution without choking state?
Can it reward inputs without creating fake incentive loops?
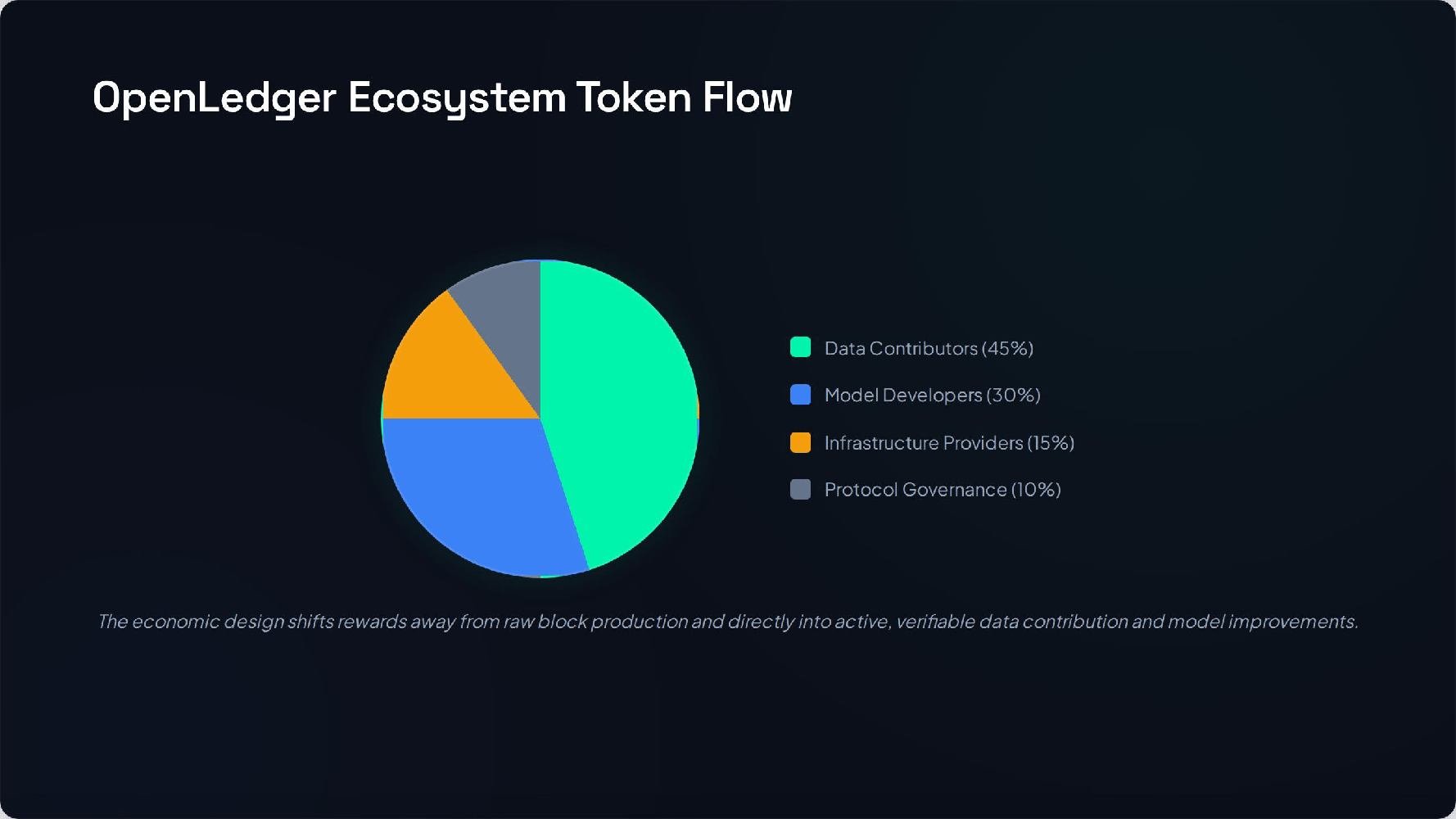
Can it make attribution useful for builders, not just pretty for governance decks?
That’s the line. Native attribution is the right problem to attack. The risk is whether the protocol can carry that weight when real AI workflows start behaving like real AI workflows: messy, recursive, expensive, and never as tidy as the pitch says.
Do your own research, because architecture claims only matter after the plumbing survives real users.
