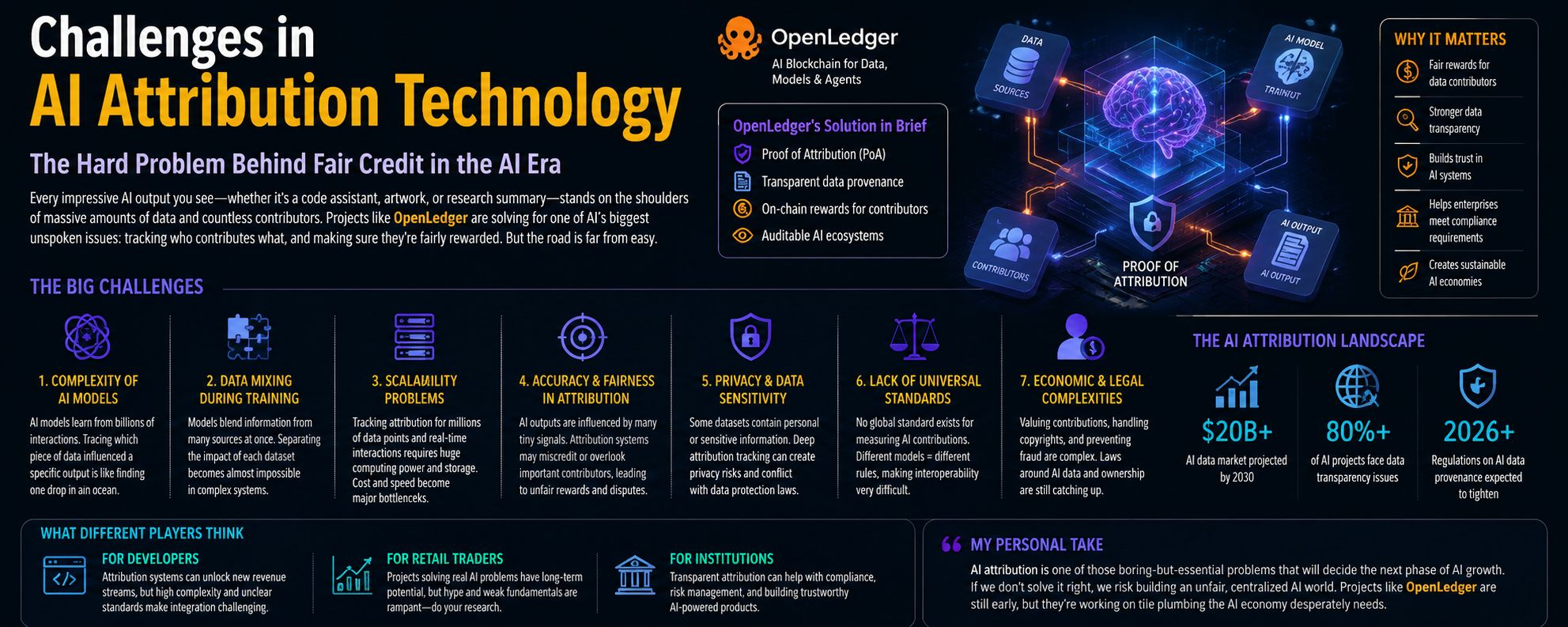
The AI industry is moving insanely fast right now. Every week there’s a new model, a new AI startup, or another billion-dollar funding round. But behind all the excitement, there’s one uncomfortable question that still has no clean answer:
Who actually deserves credit when an AI model creates something valuable?
It sounds simple at first. But the deeper you go into AI systems, the messier it gets.
Most people using AI today never think about where these models learned their intelligence from. They see polished outputs. Smart answers. Viral AI images. Automated agents. Clean interfaces. But underneath all that, there are millions of invisible contributors. Writers, researchers, coders, artists, annotators, communities, datasets, forums, public archives, and human behavior itself. AI feeds on all of it.
And honestly, this is where the real battle in AI may begin.
Projects like OpenLedger are trying to solve this through something called “Proof of Attribution.” The idea is ambitious. Track where intelligence comes from. Record who contributed data. Reward them when AI models use it. In theory, it could completely reshape the economics of AI.
But the challenge is much bigger than most people realize.
The first problem is that modern AI models do not think in straight lines. They absorb patterns from massive oceans of information at once. A single AI response may be influenced by thousands of tiny signals buried deep inside training data. Some came from books written ten years ago. Some from code repositories. Some from random conversations on the internet. The model blends everything together until the original source becomes blurry.
That’s why attribution in AI is not like citing sources in a school essay. It’s more like trying to figure out which single drop of water changed the direction of an entire river.
And this is exactly where many AI projects hit a wall.
OpenLedger’s infrastructure tries to approach this through cryptographic tracking and on-chain attribution systems. Their “Proof of Attribution” mechanism is designed to connect datasets directly to AI outputs while rewarding contributors through the OPEN token economy.
The concept is genuinely interesting because it attacks one of the deepest flaws in today’s AI market. Right now, the companies making the most money from AI are usually not the people producing the raw intelligence layer. The internet itself became the unpaid fuel source for trillion-dollar AI systems.
That imbalance is starting to bother developers too.
A lot of independent AI builders now worry about centralized AI ecosystems becoming closed economic machines. Developers contribute data, plugins, fine-tuned models, and testing feedback, yet most of the value flows upward into a handful of corporations. Quietly, this frustration is becoming one of the strongest narratives inside decentralized AI communities.
This is partly why AI-blockchain projects are getting attention again in 2026.
Still, there’s a brutal technical reality nobody can escape: attribution at scale is extremely hard.
Large language models are probabilistic systems. They don’t retrieve information like a normal database. They generate outputs through statistical relationships learned across billions of parameters. Because of this, tracing one exact output back to one exact contributor becomes incredibly complicated.
Even crypto communities themselves debate whether this can truly work at scale. Some developers argue that blockchain and AI naturally clash because blockchains need deterministic verification while AI outputs are probabilistic by nature.
And honestly, that criticism is fair.
This creates another issue nobody talks about enough: false attribution.
Imagine an attribution engine incorrectly rewarding low-quality data while ignoring the sources that genuinely shaped the model. Now the entire economic system becomes distorted. Good contributors lose motivation. Spam contributors flood the network. Data quality drops slowly over time. It becomes a silent collapse instead of a dramatic one.
That’s why OpenLedger’s system includes penalties for malicious or low-quality contributions. Their attribution pipeline attempts to score data quality and reduce rewards for manipulative datasets.
But even that introduces another challenge.
How do you objectively measure “valuable data”?
Sometimes a tiny dataset can completely improve a model in a niche area like medical reasoning or legal analysis. Meanwhile massive datasets may contribute very little useful intelligence. Size does not always equal value in AI. Relevance matters more. Precision matters more. Timing matters more.
This is where AI attribution starts looking less like computer science and more like economic philosophy.
Then comes the scalability problem. And this one is serious.
Tracking contributions across millions of AI interactions requires huge computational resources. Every inference, every dataset interaction, every retrieval layer creates more metadata. If attribution systems become too expensive or too slow, developers simply won’t use them.
Retail traders watching AI crypto projects often ignore this part. They focus on narratives and token price action. But institutional players look at infrastructure efficiency first. They care about whether systems can survive real enterprise-level usage.
And enterprises are becoming increasingly interested in verifiable AI systems.
Not because of crypto hype. Because regulation is coming.
Companies are already facing pressure around copyright issues, misinformation risks, AI transparency, and training data legality. In industries like healthcare, finance, and government systems, explainability is becoming extremely important. Institutions want to know where AI decisions came from. They want audit trails. They want accountability.
This trend quietly gives projects like OpenLedger a stronger long-term narrative than many people realize.
Their architecture around data provenance, RAG attribution, and verifiable AI outputs is aimed directly at this future. OpenLedger’s documentation even focuses heavily on transparent retrieval systems where users can trace which datasets influenced generated outputs.
And honestly, this may be where decentralized AI becomes more practical than speculative.
Not in replacing traditional AI companies overnight.
But in becoming the accountability layer underneath them.
There’s also a human side to this conversation that rarely gets discussed.
For years, the internet trained AI for free without realizing it. Human creativity became raw material. Artists felt it first. Writers noticed later. Developers eventually saw it too. Quietly, a strange feeling started spreading across the digital world — people were contributing intelligence but not participating in ownership.
That feeling is powerful. And markets built around powerful emotional realities tend to survive longer than markets built only on hype.
Still, none of this guarantees success.
The AI crypto sector is crowded now. Many projects use impressive language but struggle to deliver meaningful adoption. Some exist purely because AI is the hottest narrative in tech markets. Even crypto communities openly criticize projects that attach “AI” to branding without solving real problems.
This is why execution matters more than storytelling from this point forward.
OpenLedger already has a structured token economy around contributors, model developers, inference payments, validators, and ecosystem rewards. The project allocated a large portion of token supply toward ecosystem growth and attribution incentives.
That gives the project a stronger infrastructure identity compared to many surface-level AI tokens.
But the real test is adoption.
Can developers actually build useful AI systems on it?
Can enterprises trust attribution outputs?
Can decentralized AI economies scale without becoming inefficient?
Those questions still remain unanswered.
Personally, I think AI attribution is going to become one of the most important discussions in the entire AI industry over the next few years. Maybe not because people suddenly care about fairness. Markets rarely move on morality alone. But because transparency, ownership, and data accountability are slowly turning into economic necessities.
And if that shift really happens, projects like OpenLedger could end up being remembered as early infrastructure experiments that saw the problem before the rest of the market fully understood it.
Right now, OpenLedger still feels early. Risky too. But it also feels like one of the few AI blockchain projects trying to solve a problem that actually exists in the real world instead of inventing one for marketing. That difference matters more than people think.