

“AI行业真正的问题,不是模型不够强,而是谁在被剥削”
清风BNB:
最近几个月, 整个AI赛道明显开始进入第二阶段。
第一阶段, 大家卷的是:
模型参数
推理能力
编程能力
Agent效率
但现在越来越多人开始意识到:
AI行业真正的问题, 可能根本不在模型。
而在:
数据。
尤其最近Claude、Codex、Agent框架持续爆发之后, 市场开始出现一个越来越尖锐的问题:
这些模型, 到底是谁喂养出来的?
带着这个问题, 我最近和 OpenLedger 一位匿名资深开发产品设计成员聊了很久。
原本我以为, OpenLedger只是另一个:
“AI + 区块链”
项目。
但越聊越发现, 他们真正想解决的, 其实是整个AI行业最底层、 也最敏感的问题之一:
AI世界里的价值归属。
“现在整个AI行业,其实建立在一套非常不公平的体系上”
采访刚开始, 对方就直接抛出一句很尖锐的话:
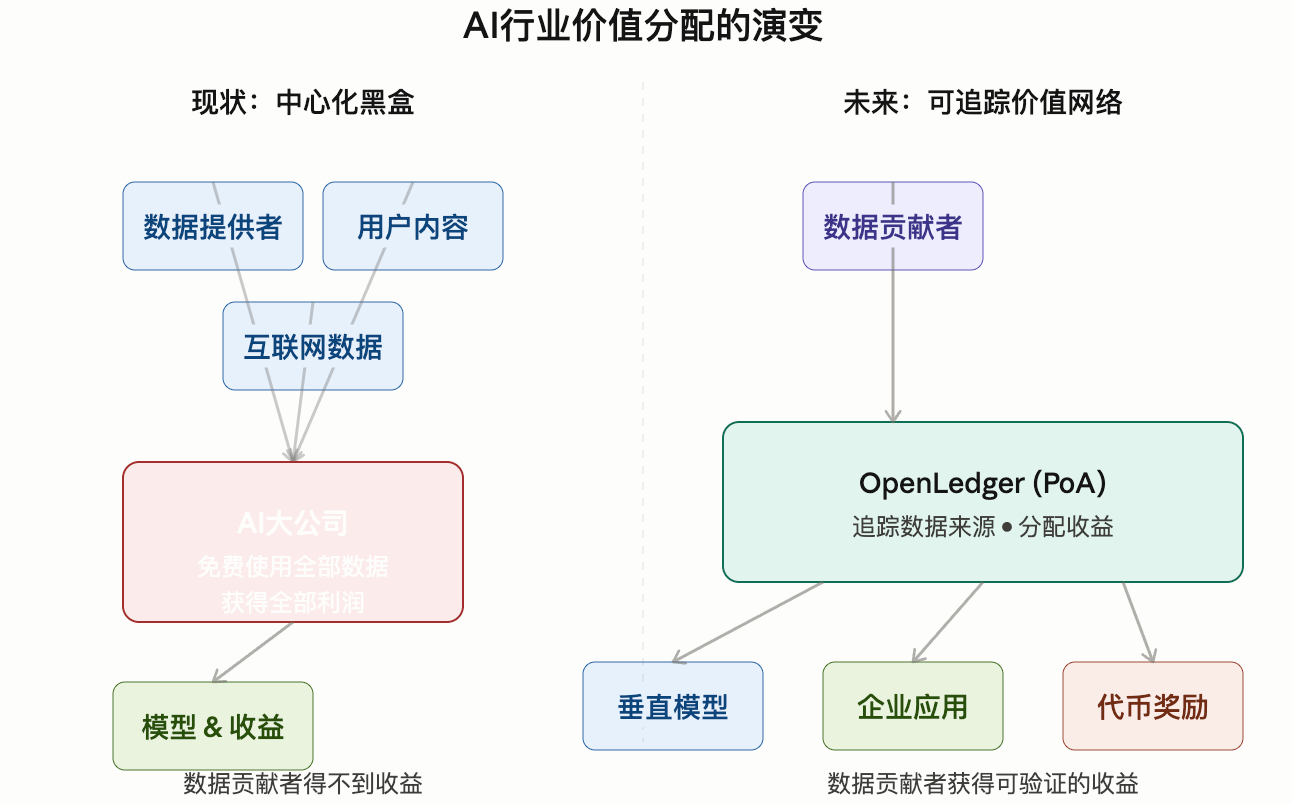
“现在大部分AI模型,本质上都在吃互联网的‘公共数据矿产’。”
他说, 现在很多AI公司其实都在默认一件事:
互联网数据可以被无限免费使用。
包括:
用户帖子
图片
视频
评论
代码
浏览行为
社交内容
这些东西, 每天都在被AI模型持续吞噬。
但问题是:
真正提供数据的人, 却几乎没有收益。
“AI公司越来越赚钱, 但贡献数据的人, 反而越来越像免费劳工。”
他说这句话的时候, 我其实挺震撼。
因为过去大部分人讨论AI, 都只关注:
模型强不强
AI会不会取代人类
Agent会不会爆发
但很少有人去讨论:
AI背后的数据价值, 到底属于谁。
而这, 恰恰是OpenLedger最核心的方向。
AI竞争从模型战争演进到数据战争。垂直专用模型(SLM)相比大模型(LLM)更容易商业化的原因——它们需要高质量、可追踪的数据,而这正是OpenLedger要解决的。
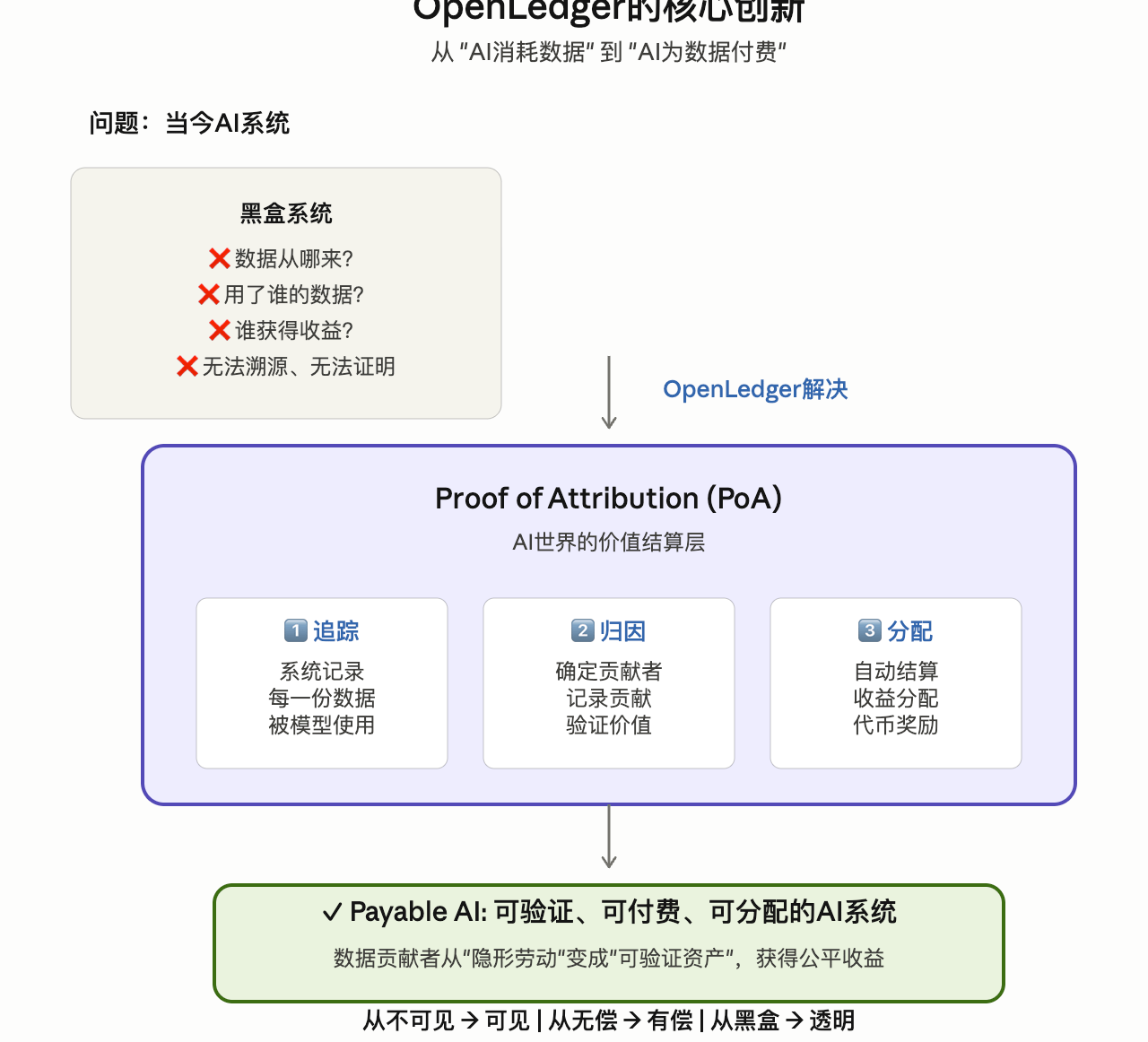
OpenLedger为什么一直强调“Payable AI”?
很多人第一次看到OpenLedger, 都会觉得这个词有点抽象:
Payable AI。
但采访过程中, 对方给了我一个很简单的解释:
“以前AI只会消耗数据,但未来AI应该为数据付费。”
这其实就是整个OpenLedger的核心逻辑。 (openledger.xyz)
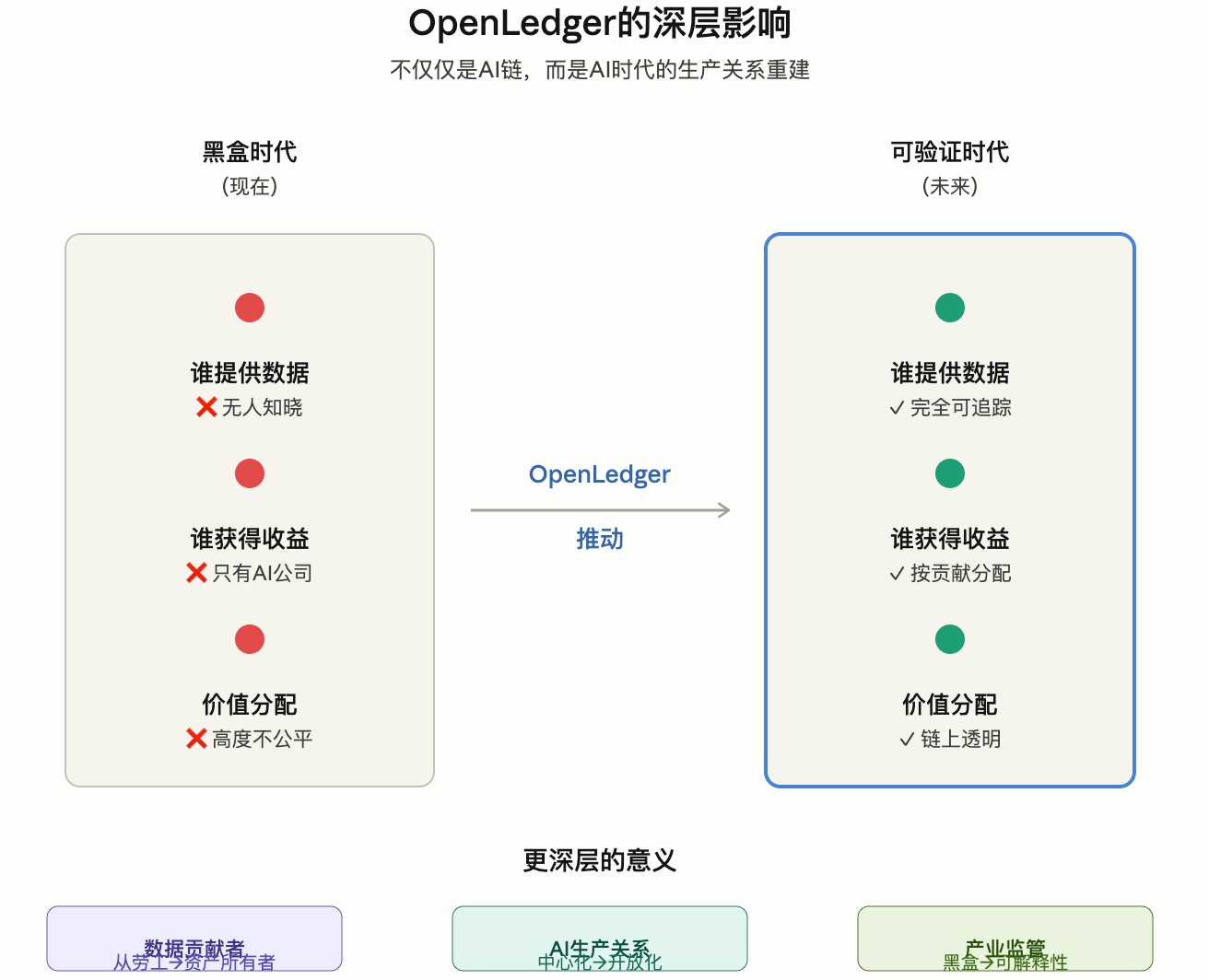
目前绝大多数AI系统, 本质上都像黑盒。
你不知道:
数据从哪里来
模型具体用了什么数据
谁贡献了价值
收益最终流向谁
而OpenLedger正在做的, 是让整个AI训练过程:
第一次拥有“归因能力”。
他们内部把这个机制叫:
Proof of Attribution(PoA)。
简单理解:
AI如果使用了你的数据, 系统能够追踪。 (openledgerfoundation.com)
然后: 自动记录贡献, 自动分配收益。
“这不是简单的数据上传平台。”
他说。
“我们真正想做的, 是AI世界里的价值结算层。”
“AI未来最大的战争,可能不是模型战争”
采访过程中, 有一个观点我印象特别深。
他说:
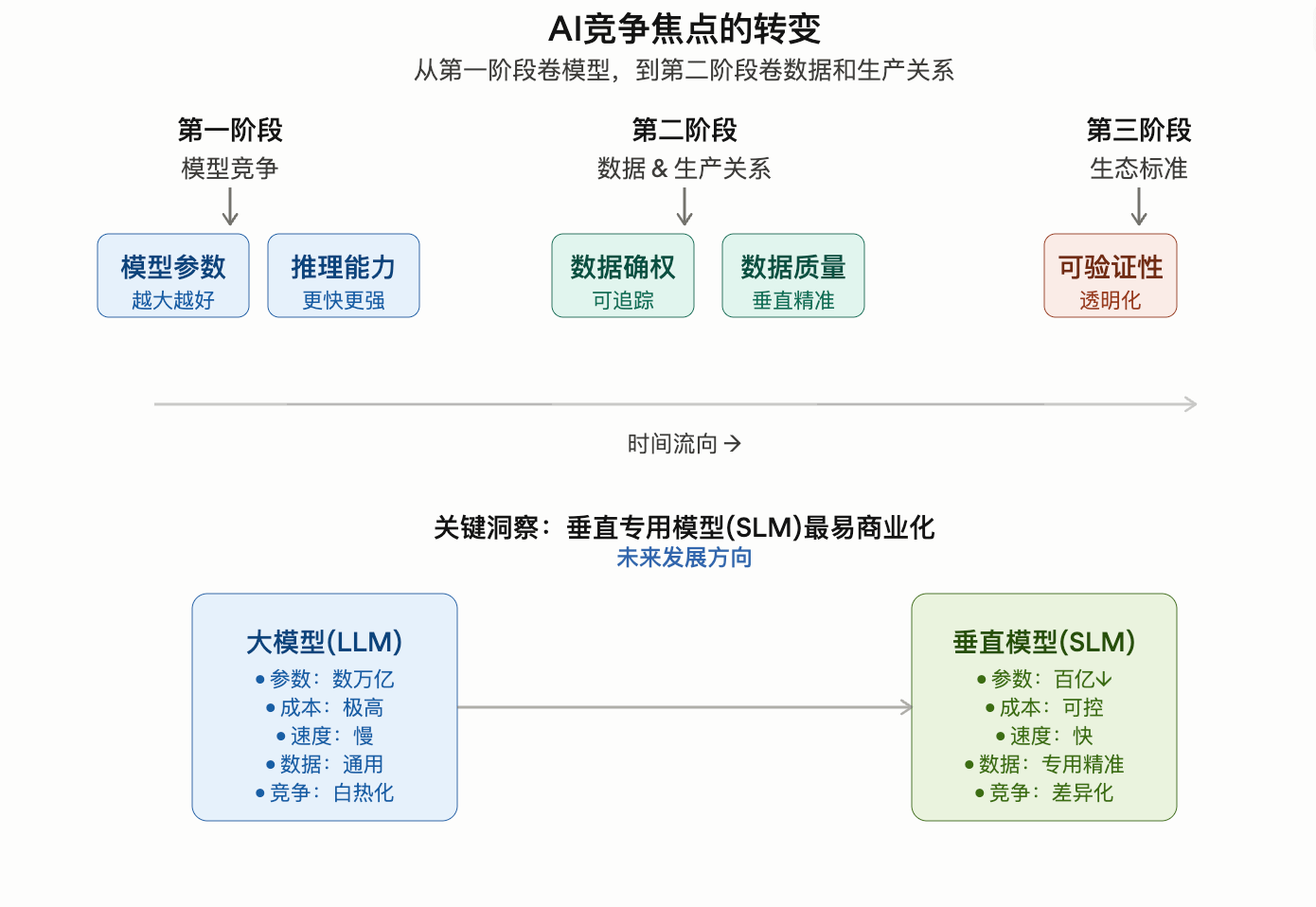
“很多人觉得未来AI竞争是大模型竞争,但我们认为,更重要的是数据产权竞争。”
他说现在市场有个误区:
所有人都在疯狂卷LLM。
但真正最容易商业化的, 其实可能是:
SLM。
也就是:
垂直专用模型。
比如:
医疗AI
法律AI
金融AI
游戏AI
企业AI
这些模型, 不一定需要几万亿参数。
但它们需要:
高质量、 可信、 可追踪的数据。
而这, 恰恰是当前AI行业最缺的东西。
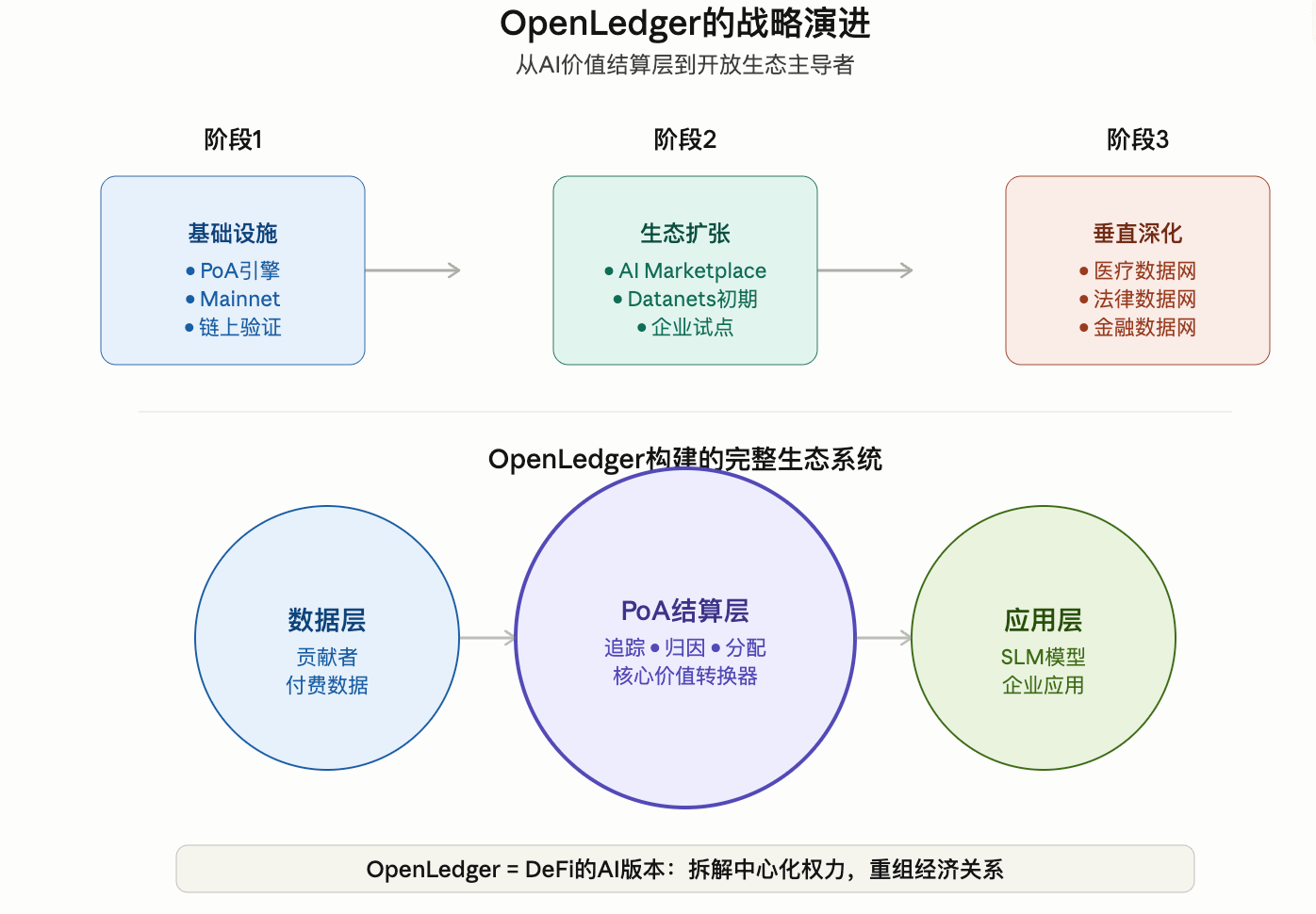
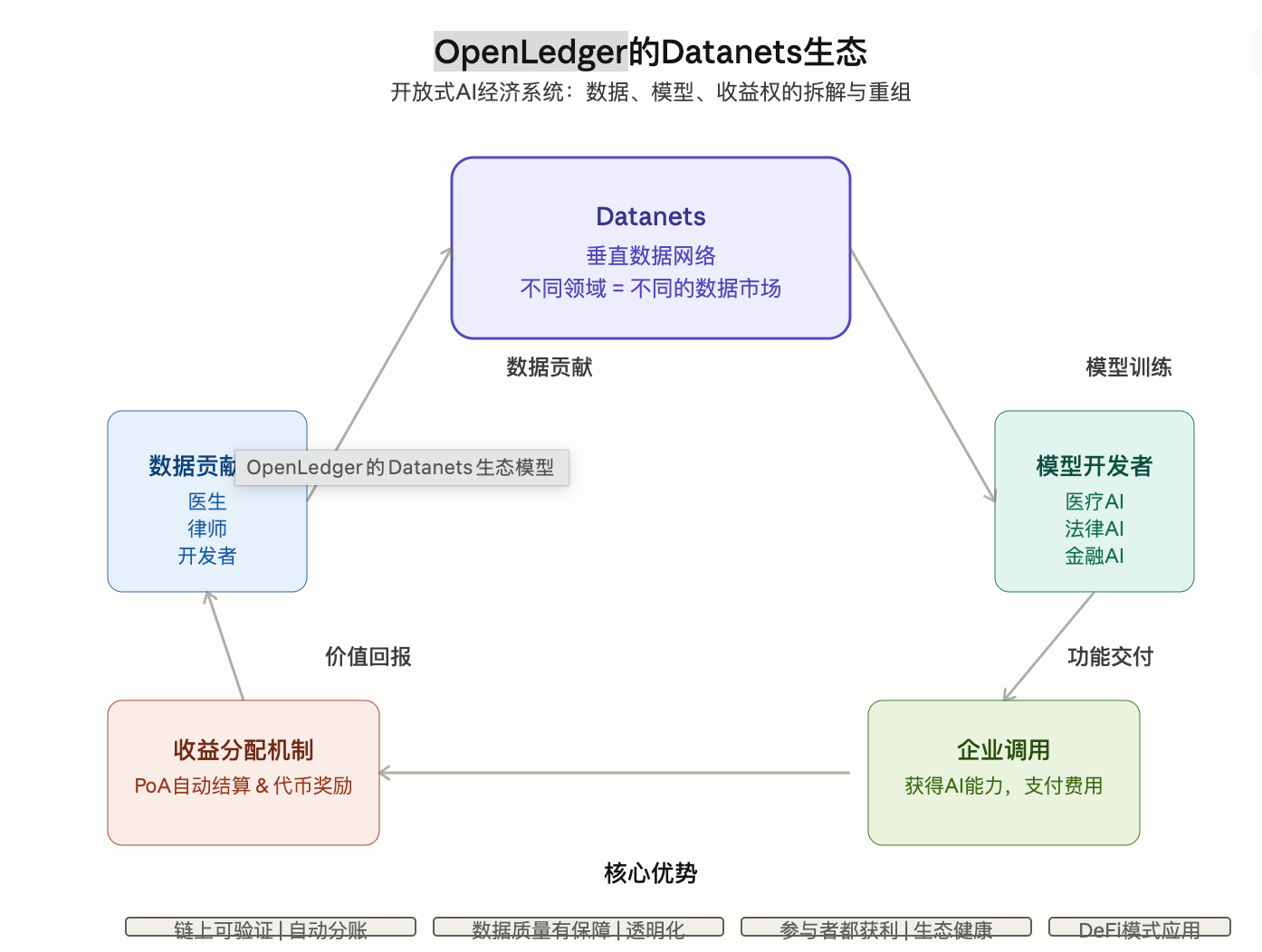
OpenLedger提出的 Datanets, 本质上就是:
垂直数据网络。 (CoinMarketCap)
不同领域的数据, 形成不同的数据市场。
模型开发者来这里训练模型。
企业调用AI能力。
数据贡献者获得收益。
整个过程链上可验证。
“过去的数据贡献, 是一种隐形劳动。”
他说。
“而未来的数据贡献, 应该变成一种资产。”
为什么OpenLedger最近开始加速推进AI Marketplace?
最近OpenLedger的动作其实非常密集。
包括:
Mainnet推进
Attribution Engine升级
AI Marketplace规划
Datanets扩张
企业级AI试点
LayerZero跨链整合 (CoinMarketCap)
尤其AI Marketplace, 其实是他们整个商业逻辑最关键的一环。
因为过去AI行业的问题在于:
数据、 模型、 收益,
全部掌握在中心化平台手里。
而OpenLedger想做的是:
把:
数据
模型
Agent
收益权
全部拆开。
重新组合成:
开放式AI经济系统。
这一点其实很像: 当年DeFi对传统金融做的事情。
只不过:
这次被重构的, 变成了AI产业。
“OpenLedger真正想做的,其实不是AI链”
采访最后, 我问了对方一个问题:
“你觉得外界现在对OpenLedger最大的误解是什么?”
他沉默了几秒, 然后说:
“很多人以为我们在做AI链,但其实我们在做AI时代的生产关系。”
说实话, 这句话我后来想了很久。
因为现在绝大多数AI项目, 还停留在:
Agent
Meme
套壳应用
流量叙事
但OpenLedger已经开始讨论:
AI世界里的:
数据确权
价值归因
收益分配
可解释性
经济结构
这些东西, 其实才是真正长期的问题。
尤其最近全球AI监管越来越严之后, 越来越多企业开始关注:
AI数据来源是否合法? 训练过程是否透明? 模型结果是否可追踪? (The Block)
而OpenLedger正在押注的, 恰恰是:
未来AI一定会从“黑盒时代”, 进入“可验证时代”。
当然, 这条路并不好走。
因为它挑战的, 其实是当前AI行业默认的利益结构。
但至少它让我第一次认真意识到:
未来AI世界真正值钱的, 可能未必只是模型本身。
而是:
谁拥有数据价值的解释权与分配权。
而OpenLedger, 正在尝试成为这个体系里的第一批规则制定者。
@OpenLedger #OpenLedger $OPEN $BTC

