
After recent updates from OpenLedger, what stands out to me is not just a single AI product, but the way the project is attempting to address the “attribution layer” across the entire AI ecosystem.
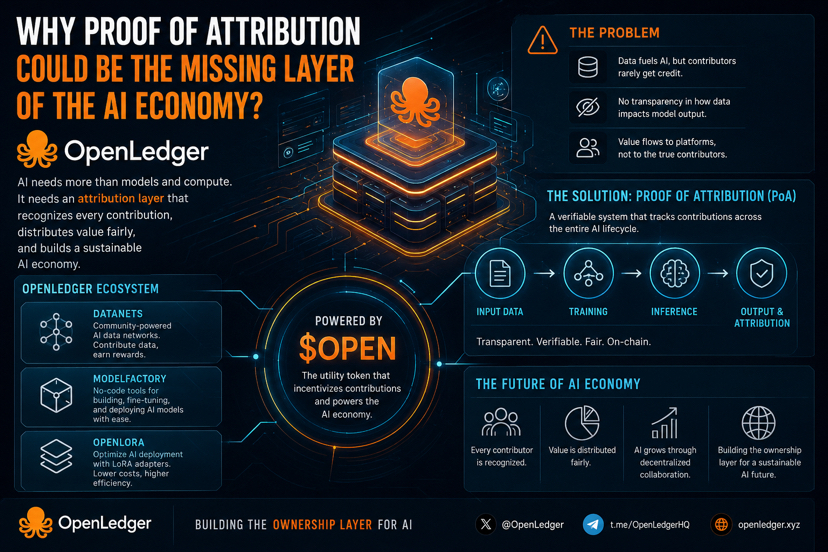 In traditional AI systems, data is used to train models, generate inference, or perform fine-tuning, yet there is almost no clear mechanism to precisely determine which data contributed to a final output. This creates a significant gap in value distribution — where data contributors often do not receive fair or proportional rewards for their input.
In traditional AI systems, data is used to train models, generate inference, or perform fine-tuning, yet there is almost no clear mechanism to precisely determine which data contributed to a final output. This creates a significant gap in value distribution — where data contributors often do not receive fair or proportional rewards for their input.
OpenLedger approaches this problem through Proof of Attribution (PoA). The core idea is to build a system capable of tracking contributions throughout the entire AI lifecycle: from input data, to training processes, and finally to inference outputs. Once attribution becomes transparent and verifiable, economic value can be distributed more fairly through the OPEN ecosystem.
Beyond PoA, OpenLedger’s ecosystem is gradually expanding with components such as Datanets, ModelFactory, and OpenLoRA. Datanets focus on building community-contributed AI data networks, ModelFactory simplifies model building and fine-tuning, while OpenLoRA aims to reduce AI deployment costs by efficiently leveraging GPU resources through adapter-based optimization.
What I find most important is that OpenLedger is not simply building an “AI application layer”, but rather moving into the infrastructure layer — the part that defines how AI operates, how value is distributed, and how systems scale in a decentralized environment.
If AI truly becomes the infrastructure of the future internet, then the attribution layer may become an essential component of the entire ecosystem 👀
