If you look closely at the Decentralized AI (DeAI) landscape, 90% of the projects look identical. They are racing to commoditize computing power—essentially building decentralized server farms to rent out GPUs. But OpenLedger ($OPEN) is quietly executing a fundamentally different playbook.
While it looks, breathes, and acts like a standard high-performance AI blockchain on the surface, its core economic engine isn't pricing computing cycles. It’s pricing AI data attribution.
Here is why this distinction matters for the future value of $OPEN.
The Compute Trap vs. The Data Bottleneck
Renting out GPUs (decentralized compute) is a race to the bottom. Big tech companies are building massive centralized data centers, and web3 compute protocols are constantly undercutting each other on price. Compute is a commodity.
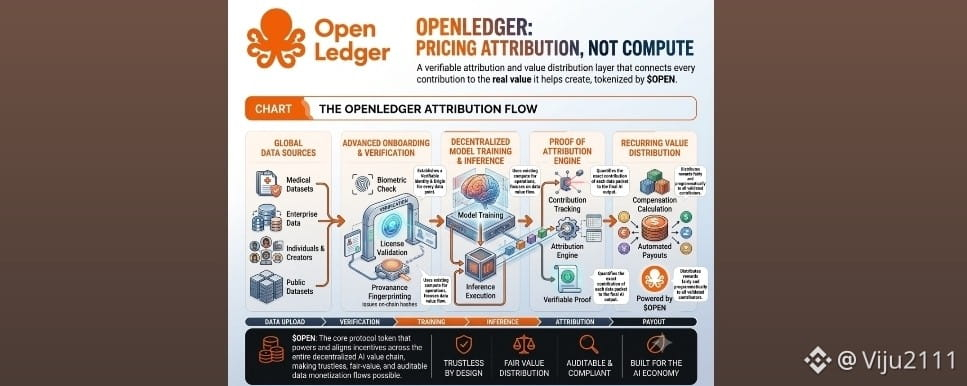
Data, however, is not. The biggest bottleneck in AI today isn’t finding a graphics card; it’s acquiring high-quality, specialized, verifiably clean data to train models. OpenLedger’s architecture—built as an EVM-compatible infrastructure—focuses entirely on this data pipeline. Through what they call Datanets, communities can co-create, host, and curate specialized datasets on-chain.
Enter Proof of Attribution (PoA)
This is where the $OPEN token physics get interesting. Instead of using a standard Proof of Work or Proof of Stake mechanism to merely secure transactions, OpenLedger implements Proof of Attribution (PoA) via its live mainnet infrastructure.
💡 Proof of Attribution is a protocol-level mechanism that tracks exactly how a specific dataset, LoRA, or base model influences a final AI agent's output.
When an AI model is deployed or an AI agent answers a query, OpenLedger traces the lineage of the data used back on-chain. If your contributed data helped fine-tune that model, the protocol verifies it and ensures you get credited.
Therefore, the $OPEN token isn't just gas to pay a validator for electricity; it acts as the primary settlement currency for intellectual property rights and monetization within the "Payable AI" ecosystem.
What to Watch: Supply Dynamics & Data Monetization
As OpenLedger moves deeper into its mainnet lifecycle, the investment thesis for $OPEN relies on real protocol adoption metrics:
Token Utility: $OPEN is used to launch Datanets, govern Model Factories, and distribute automated attribution rewards to data curators.
The Repurchase Catalyst: The OpenLedger infrastructure utilizes network fee revenue to execute automated token mechanics. If model usage scales, market buy pressure scales mechanically with it.
The Dilution Test: Keep a close eye on the macro horizon. With team and investor allocations subject to a linear unlock sequence after the initial cliffs, the network’s data volume must scale fast enough to absorb changing circulating supply.
The Bottom Line
If you are evaluating $OPEN as just another "decentralized AWS copycat," you are missing the forest for the trees. OpenLedger is trying to build the foundational ownership ledger for AI assets. If they succeed, $OPEN won't just be an AI token—it will be an index on the value of the underlying data powering the models.
Are you betting on DeAI infrastructure that scales raw compute, or protocols that own the data layer? Let’s talk in the comments! 👇
#OpenLedger #ArtificialIntelligence #Web3Tech h #CryptoAnalysis #DeAI