
The AI narrative has shifted completely. I remember early 2025; the focus was purely on "compute power." Last year, the only question that mattered was: Who had the most GPUs? But as we move deeper into 2026, the industry has pivoted. The bottleneck isn't just raw power anymore; it’s verifiable data quality. As I’ve been researching the @OpenLedger ($OPEN ) ecosystem, it has become clear to me that OpenLedger is solving the single biggest, most complex problem in decentralized AI: Attribution.

The Problem: The 'Black Box' of AI
Current Large Language Models (LLMs) are essentially black boxes. They ingest massive amounts of data from the public domain, but they don't reward the sources that provide the intelligence that makes them valuable. This creates a dangerous inefficiency in the digital economy: Ingestion Without Attribution.
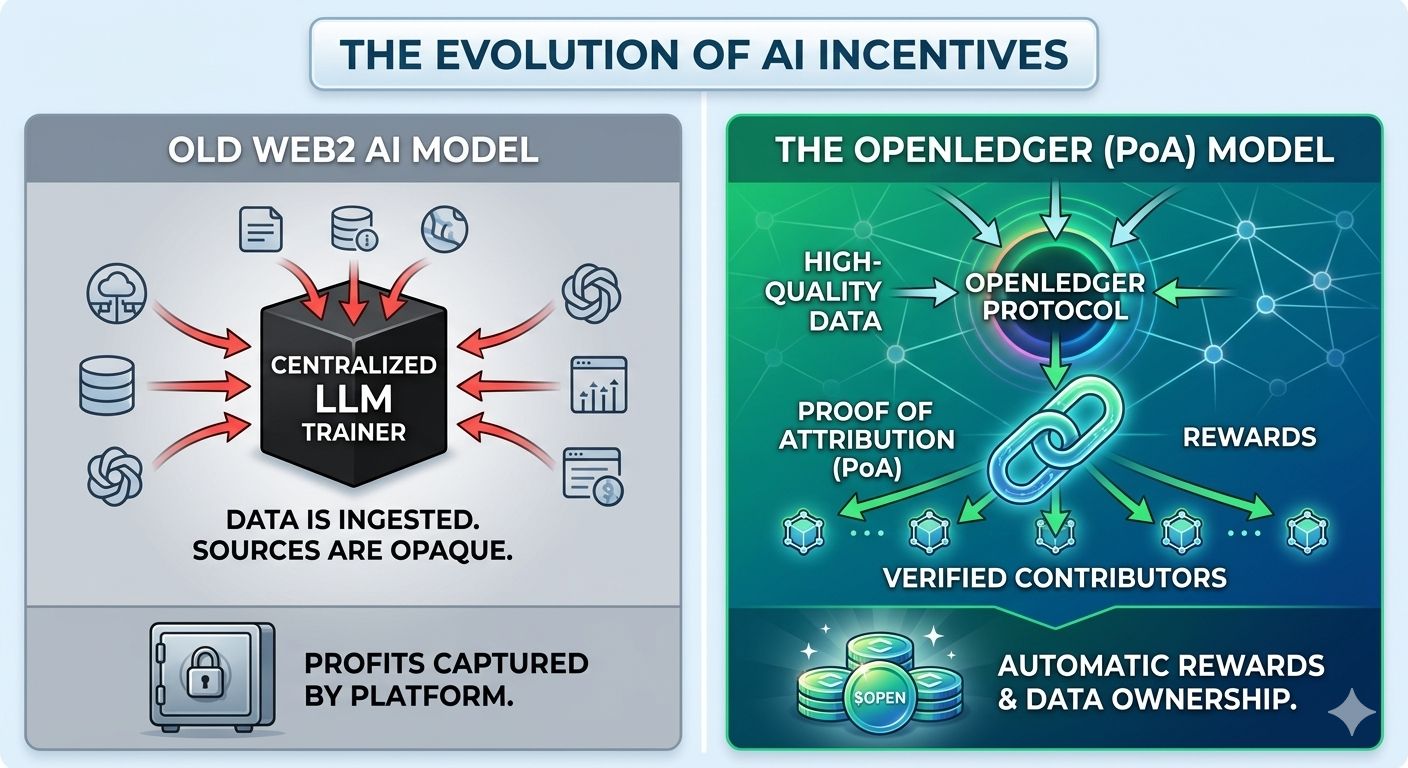
If your creative output, legal analysis, or medical code helps train an AI, you should own a piece of that value. The current model hoards the value, leaving high-quality data providers on the sidelines. Enterprise adoption demands an audit trail, and without attribution, decentralized AI cannot compete with the incumbents.
The Mechanism of Change: Proof of Attribution (PoA)
This is where the OpenLedger architecture finally bridges the gap. The core protocol leverages Proof of Attribution (PoA) to define "Data Sovereignty." While other networks reward simple uptime, $OPEN rewards influence.
* For Large Language Models: The protocol uses suffix-array-based token attribution to pinpoint exactly which memorized spans within a training corpus influenced a model's output.
* For Smaller, Niche Models: It employs gradient-based influence functions to calculate how a specific data point affected the loss function of the model.
2026 Roadmap: Transitioning from Narrative to Utility
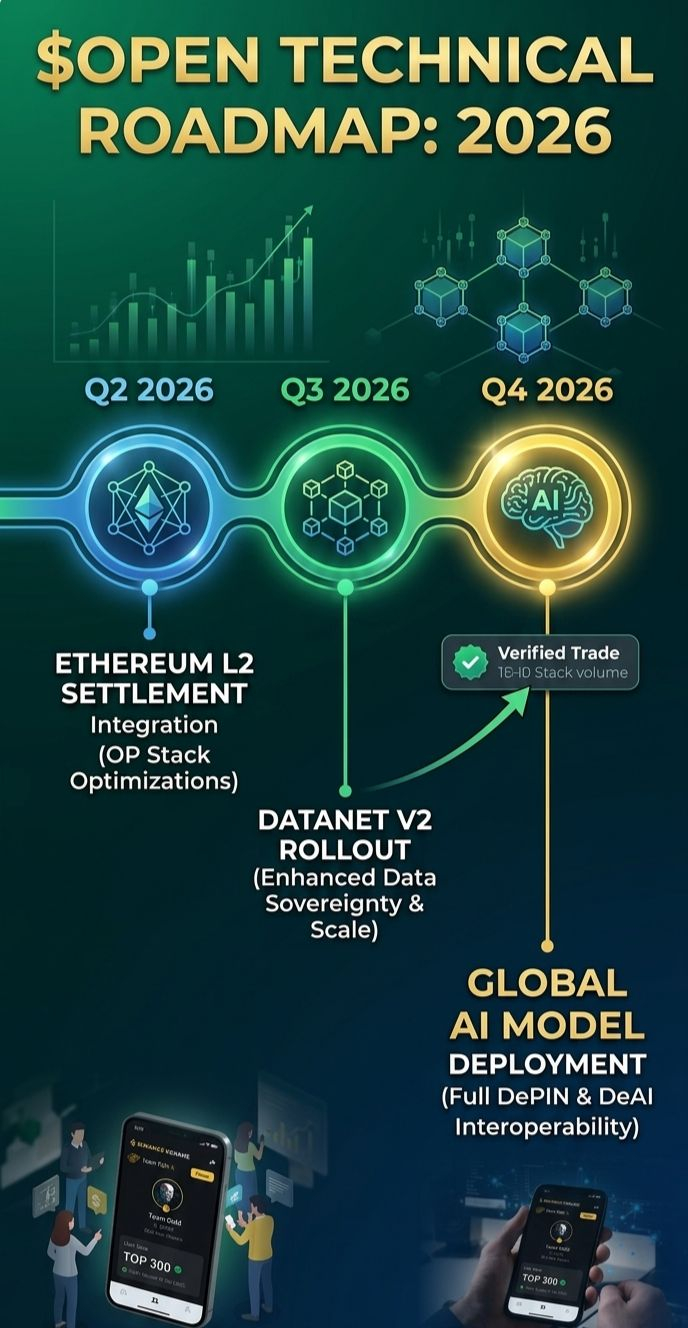
We are currently navigating the transition from the "concept phase" to the "utility phase." The roadmap for 2026 is critical. The infrastructure rollout is focused on creating a self-sustaining data marketplace:
1. DataNet Registries: We are seeing domain-specific datasets (Legal, Medical, Code) being indexed on the DataNet Registry, ensuring high-precision attribution.
2. Autonomous Agent Integration (Q3 Launch): This is the "App Store" moment for decentralized AI. The Marketplace launch will allow any developer to deploy an AI agent that is audit-ready and compliant.
Conclusion: The Alpha is in the Infrastructure
I have reviewed many AI protocols this cycle, and the common pitfall is that they focus entirely on the output (the chat, the image) and ignore the input (the data). The "attribution side" is the most critically underrated alpha in this market.
OpenLedger’s architecture—built securely on the OP Stack—isn't just another layer-2; it is the most robust, enterprise-grade response to the demand for verifiable data provenance. The era of unrestricted data harvesting is ending. The era of verifiable data ownership has begun.