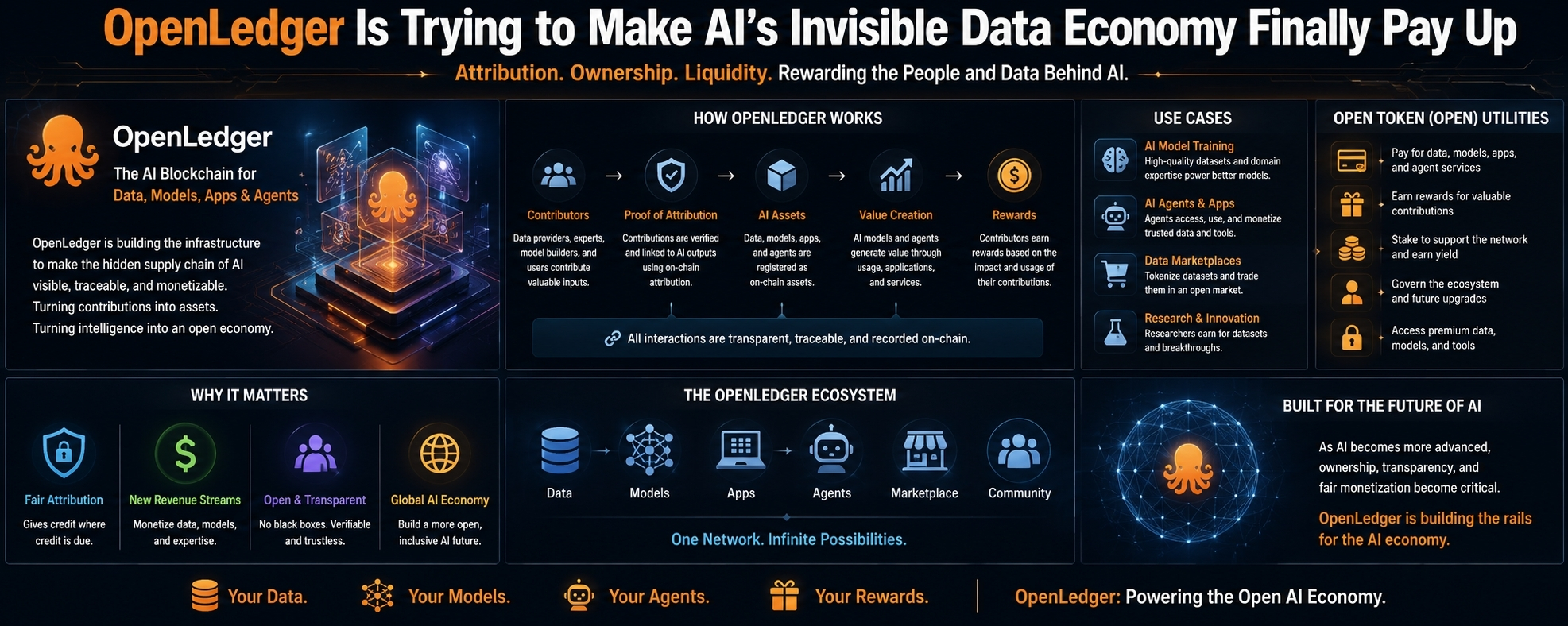

OpenLedger is building around a problem the AI market keeps trying to bury under cleaner language.
AI keeps getting more valuable. Everyone can see that. Models are improving, agents are getting pushed into every workflow, and data is slowly becoming the oil nobody wants to admit they already drilled for free. But the people behind that value? The data providers, the domain experts, the users feeding feedback into the system, the builders improving models in quiet corners?
Mostly invisible.
Mostly unpaid.
Same old story.
That is the part of OpenLedger I actually find worth looking at. Not because it has AI in the pitch. I’ve seen enough AI crypto decks to know how quickly that word turns into noise. Most of them recycle the same promises with a new logo and a thinner token model. OpenLedger is at least aiming at a real wound in the market: if intelligence is becoming an asset, then the inputs behind that intelligence need some kind of ownership, pricing, and reward structure.
That sounds obvious until you realize how badly the current system avoids it.
Data goes in. Models get smarter. Outputs get sold. Somebody captures the upside. Usually not the people who created the useful signal in the first place.
OpenLedger wants to build an AI-focused blockchain where data, models, applications, and agents can be tracked and monetized. That is the clean version. The rougher version is this: it wants to make the hidden supply chain of AI visible enough that people can actually get paid from it.
I like that idea.
I also do not trust it easily.
Crypto has a long history of taking a real problem, wrapping it in incentives, then watching the whole thing get farmed to death. That is the grind. A project says it will reward contribution. Then the market floods it with low-quality participation because rewards attract volume before they attract value. The system gets noisy. The dashboards look active. The token moves for a while. Then everyone realizes most of the activity was just people extracting incentives from a half-built economy.
That is the risk here.
OpenLedger’s attribution layer is the part I keep coming back to. If a dataset, model update, or user contribution actually improves an AI output, the system should be able to recognize that and reward the contributor. On paper, that is powerful. In practice, it is messy.
Very messy.
Because usefulness is hard to measure. Anyone can submit data. Not everyone submits signal. A thousand contributors can show up, but if most of them are feeding junk into the system, the network becomes another landfill with a token attached. The real test is whether OpenLedger can separate valuable contribution from recycled noise.
That is where I’m watching.
Not the slogan. Not the market hype. Not the chart for one green candle.
I’m watching for proof that the system can identify quality and pay for it without turning into a farming machine.
The project gets more interesting when you think about specialized AI. General AI is already crowded, expensive, and dominated by giants with more compute than most crypto projects could dream of touching. OpenLedger probably does not win by pretending it can outmuscle that machine.
The better path is narrower.
Finance data. Security intelligence. Research datasets. Legal models. Creator-owned IP. Enterprise agents. These are areas where the origin of data actually matters. A random scraped dataset is not the same as verified expert input. A generic model is not the same as one trained on rare, high-quality knowledge. A basic agent is not the same as one with trusted access to useful information.
That is where attribution stops being a nice feature and becomes infrastructure.
But here’s the thing. Infrastructure is a brutal business in crypto. Everyone wants to be the base layer. Everyone wants to be the rails. Everyone says they are building for the next wave. Most of them end up building empty highways with beautiful signs and no traffic.
So I’m not asking whether OpenLedger has a strong idea.
It does.
I’m asking whether anyone will use it when the incentives calm down.
That is always the ugly question.
Will real data providers bring valuable datasets because the rewards are meaningful?
Will model builders deploy there because it solves friction they already feel?
Will agents actually interact with the network because it gives them something they cannot get from a normal database or a private system?
Will OPEN have a real role in the economy, or will it just sit beside the project as another tradable symbol?
That last one matters more than people like to admit. A project can be useful while the token remains weak. I’ve seen that too. If OPEN becomes part of payments, access, rewards, staking, and coordination inside the network, then there is a real token argument. If not, the market will eventually treat it like every other narrative coin that sounded smarter than it was.
No mercy there.
The whole idea of unlocking liquidity around data and models sounds good, but I prefer the uglier framing: OpenLedger is trying to make intelligence payable. That is the real angle. Not AI as a buzzword. Not blockchain as a decoration. Payable intelligence.
A useful dataset should not just sit in someone’s folder.
A model that improves from expert input should not erase the expert.
An agent that earns value from trusted information should not pretend that information came from nowhere.
OpenLedger is trying to put an economic trail underneath all of that.
Still, the friction is heavy. Data rights are messy. Attribution is hard. AI outputs are not always easy to trace back to one clean source. Token incentives can distort behavior. Developers hate complexity unless the payoff is obvious. Enterprises move slowly. Contributors get bored if rewards feel small. Speculators leave the second the chart stops entertaining them.
That is the market OpenLedger has to survive.
Not the fantasy version. The real one.
The project does have a serious opening because AI is moving toward agents, specialized models, and permissioned data markets. The deeper AI gets into business and research, the louder the ownership question becomes. Who owns the data? Who gets paid when it improves a model? Who can prove where an output came from? Who carries the risk if the data was not allowed to be used?
These questions are not going away.
They are just being delayed.
OpenLedger is trying to build before that pressure becomes unavoidable. That is a decent instinct. Early, maybe. Difficult, definitely. But not empty.
The thing I want to see now is not more polished language. I want to see usage with weight behind it. Real datasets. Real contributors. Real model activity. Real agents touching the network because they need to, not because there is a campaign running. I want to see whether the reward system creates quality instead of just movement.
Movement is cheap in crypto.
Quality is not.
And that is where OpenLedger either becomes interesting or joins the pile of projects that had the right words, the right timing, and still could not turn the machine on.