We talk a lot about models.
We talk about agents.
We talk about speed, automation, productivity, and all the new things AI can do.
But we do not always talk enough about the people behind the material AI learns from.
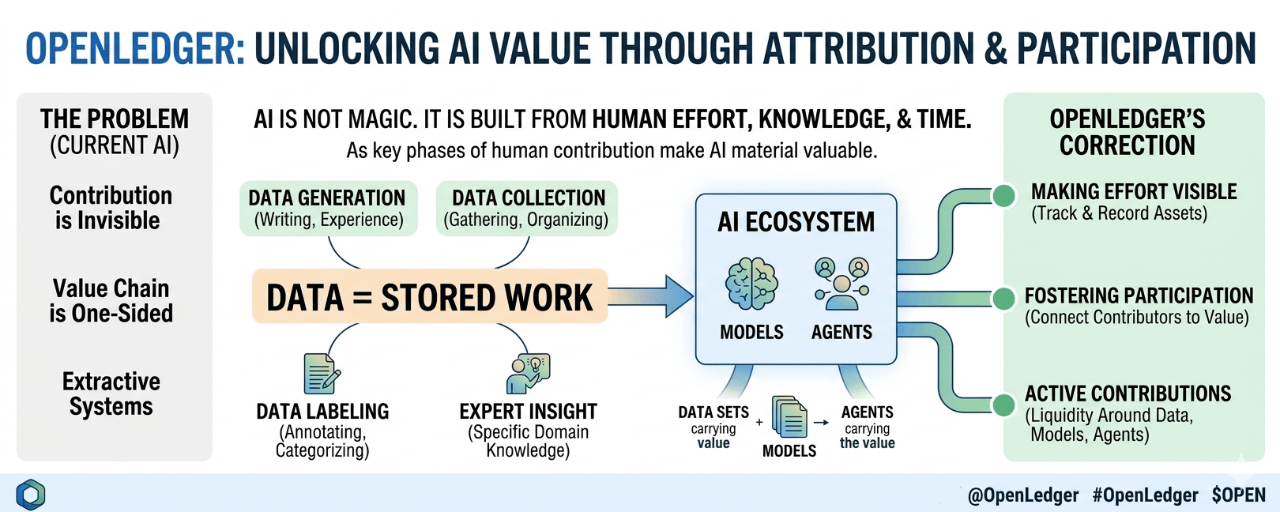
That part is easy to overlook because data often sounds like something neutral. Just a file. Just a dataset. Just information. But most useful data comes from somewhere human, even when it looks clean and technical by the time it reaches a model.
Someone wrote it.
Someone collected it.
Someone labeled it.
Someone organized it.
Someone had the experience that made the information valuable in the first place.
After a while, it becomes obvious that data is not only data.
It is stored work.
That is one way to look at OpenLedger. Not only as an AI blockchain, and not only as a system for monetizing data, models, and agents. More quietly, it can be seen as an attempt to treat AI inputs as something with a history.
That history matters.
Because the AI world has a habit of making contribution feel invisible. A model gives an answer, and the answer looks like it came from the model itself. A tool performs a task, and the user sees the tool. An agent completes a workflow, and the final action gets all the attention.
But underneath that, many earlier contributions are still doing work.
This is where the question starts to change.
Instead of asking only, “How powerful can AI become?”
Maybe we also need to ask, “How should AI remember what helped make it useful?”
That is not a dramatic question. It is not the kind of thing that usually gets the most attention. But it may become more important as AI becomes part of everyday systems.
If data helps train a model, and that model keeps producing value, should the data be treated as a one-time input?
If expert knowledge improves an agent, should that expert vanish from the value chain?
If a community contributes language, culture, behavior, or context that makes AI better, should that contribution be forgotten once it becomes part of the system?
These are uncomfortable questions, because the answers are not simple.
Attribution in AI is hard. Data is mixed together. Models learn patterns, not memories in a clean human sense. Many contributions overlap. Some are public, some are private, some are licensed, some are not. So it would be too easy to pretend there is a perfect solution.
But the fact that it is difficult does not mean it can be ignored.
OpenLedger seems to be working near this problem. Its focus on data, models, and agents suggests a system where AI assets can be tracked, connected, and used with clearer records. That could make it easier to understand which pieces support which outcomes, and how value might flow back to those pieces over time.
Not perfectly.
But maybe more clearly than before.
And sometimes clearer is already a meaningful step.
What feels interesting here is that the conversation becomes less about ownership in a hard, legalistic sense, and more about participation. Who gets to take part in the AI economy? Who can offer something useful without losing all connection to it? Who can benefit when their knowledge becomes part of something larger?
That is where things get interesting.
AI does not just need more data. It needs better data. More specific data. More trusted data. More local, expert, and context-rich data. The kind of information that often does not come from scraping the open internet, but from people and groups who understand a field deeply.
If those people have no reason to share, the system misses out.
If they share and receive nothing, trust weakens.
If they contribute and disappear, the value chain becomes one-sided.
OpenLedger’s idea of unlocking liquidity around AI assets can be read in that light. Liquidity is not only about making things tradable. It is also about making contribution active. Letting data, models, and agents move through a system where they can keep carrying value instead of becoming dead inputs.
That is a subtle shift.
A dataset is no longer just something consumed once.
A model is no longer just a closed object.
An agent is no longer just a tool floating without context.
Each one can become part of a chain of contribution.
And that chain, if designed well, can make AI feel a little less extractive.
That word matters. A lot of people are uneasy about AI because it seems to take from many places and return value to only a few. Sometimes that fear is overstated, but sometimes it is not. People notice when systems benefit from public or collective work without giving much back.
You can usually tell when technology moves too fast for its own social layer. The tools become impressive before the rules feel settled. AI feels like that right now. It can do a lot. But the questions around credit, consent, reward, and responsibility are still catching up.
OpenLedger is not the whole answer to that.
No single project is.
But it is pointing toward a space where these questions can be built into infrastructure rather than discussed only after the fact. That is the part worth noticing. If value is created through many layers, then maybe the system should be able to remember more than just the final product.
It should remember the inputs.
It should remember the model improvements.
It should remember the agents that put things to work.
And maybe it should create better ways for the people behind those pieces to stay connected to the value they helped create.
There is something grounded about that idea.
Not flashy. Not loud. Just a recognition that AI is not magic. It is built from material. And much of that material comes from human effort, knowledge, and time.
If OpenLedger can help make that effort more visible and more usable, then its role becomes easier to understand.
Not as a grand promise.
More as a small correction to the way AI value is usually hidden.
And maybe, as the AI economy grows, those small corrections start to matter more than they first appear…
@OpenLedger #OpenLedger $OPEN
Articolo
There is one part of AI that still feels strangely unfinished.
Disclaimer: Include opinioni di terze parti. Non è una consulenza finanziaria. Può includere contenuti sponsorizzati. Consulta i T&C.