晚上好老铁们,卡卡我记得2024年的时候一个晚上我盯着屏幕上一串串跳动的算力数字,整个人陷在椅子里动弹不得。那时我刚刚退出了一个AI训练数据标注项目,原因很简单:干了三个月,钱拿得零零散散,而且根本搞不清楚自己贡献的数据最终去了哪里,喂给了哪个模型,产生了多少价值。我问平台,平台说"保密"。我问朋友,朋友说"都这样"。我接受不了这个答案。就在那个夜里,我无意间刷到了@OpenLedger 的白皮书,读到PoDC这四个字母,整个人突然坐直了,我记得自己反复看了那段话好几遍,脑子里第一个念头不是"这能赚钱吗",而是"这他妈才是对的"
oDC,全称Proof of Data Contribution,中文叫数据贡献证明,也有人译作数据工作量证明。这是OpenLedger整个生态系统的核心引擎,也是它区别于市面上绝大多数AI数据平台最本质的东西。要真正理解它,不能从术语入手,得从问题入手——AI时代最核心的不公平是什么?是数据贡献者永远是看不见的沉默资源,而模型的受益者从来不需要对他们负责。PoDC就是被设计出来解决这个问题的
最简单的类比是比特币的PoW机制。矿工用算力证明自己的工作,网络验证后给予奖励。PoDC的逻辑与此高度相似,但把"算力"换成了"数据贡献"。你提供了什么质量的数据,你贡献的数据在AI训练中发挥了多少实质作用,链上会有一套完整的机制记录和验证这一切,然后根据贡献度分配代币激励。听起来简单,做起来却涉及极其复杂的技术架构
具体来说,PoDC机制分为四个主要环节。第一是数据提交,贡献者——无论是个人用户、企业节点,还是AI公司——将原始数据或经过标注的数据集提交到OpenLedger网络。第二是链上验证,系统通过一套去中心化的验证节点对数据的真实性、唯一性和质量进行审核,防止重复提交和低质量数据滥竽充数。第三是贡献度评分,这是整个机制最精妙的部分——网络不只看数据量,还会追踪这批数据在实际AI模型训练过程中的调用频率和影响力,也就是说数据被"用到了"才算真正的贡献。第四是激励发放,系统根据贡献度评分自动计算并分配$OLT代币奖励,整个过程透明、可追溯、不可篡改$BTC
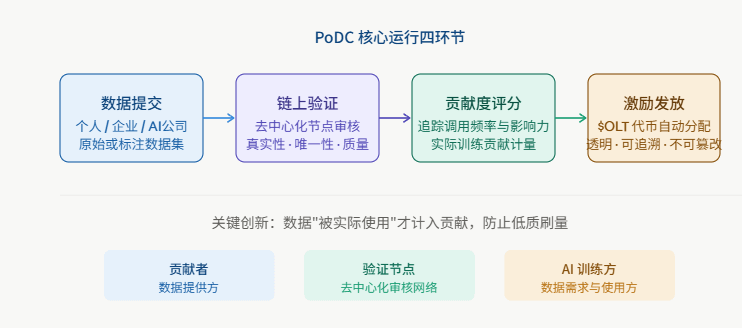
这里有个细节我想重点点出来,因为很多人误解过这个问题——PoDC评分系统不是简单地按数据量来算的。如果你向网络提交了一百万条冗余的低质量文本,你拿到的奖励甚至可能不如某个只贡献了五千条真正被AI模型高频调用的稀缺医疗对话数据的用户。这个机制倒逼贡献者去思考"什么样的数据是AI真正需要的",而不只是"我能快速刷出多少条目"。这从根本上把数据市场从一个拼量的游戏,变成了一个拼质的游戏
我和几个做AI数据业务的朋友聊过这个问题,他们的第一反应几乎都是"这个验证环节能做到吗"。确实,链上数据验证听起来简单,实际落地是一道极难的工程题。OpenLedger给出的答案是多层次的混合验证机制:第一层是自动化的基础质检,过滤重复、格式错误和明显低质内容;第二层是验证节点的人工智能辅助抽样审核,对数据集进行语义层面的质量判断;第三层是溯源追踪,当某批数据被AI公司调取用于训练时,系统会同步更新该批数据的贡献影响力评分,真正做到"用了才算数"
从更宏观的视角看,PoDC试图回答的其实是Web3时代一个很根本的问题:价值如何在AI产业链中公平流动?目前AI产业的现实是高度失衡的。少数科技巨头控制着数据、算力、模型,普通人的数字行为每天以海量规模被抓取,却从未获得任何回报。PoDC构建的逻辑是:把数据贡献量化、确权、上链,让每一份数据的来源和价值都有迹可循,从而让利益可以沿着数据流动的路径反向流回贡献者
这不是在画饼,这是一套已经在测试网阶段跑通基本逻辑的架构
当然,我也不会因为机制设计漂亮就鼓吹它没有挑战。PoDC最难的地方在于规模化以后的治理问题。当网络上的数据贡献者达到百万级别,当验证节点分布全球,当AI公司的数据调用频率以亿次为单位计算的时候,贡献评分系统的公平性能否持续保证,激励分配是否会被早期巨鲸节点垄断,这些都是没有被完全解答的开放问题
但比起这些执行层面的风险,我更在意的是PoDC所代表的方向——数据贡献者第一次有机会作为真正的参与者站在AI产业链的结构里,而不只是沉默的原材料$ETH
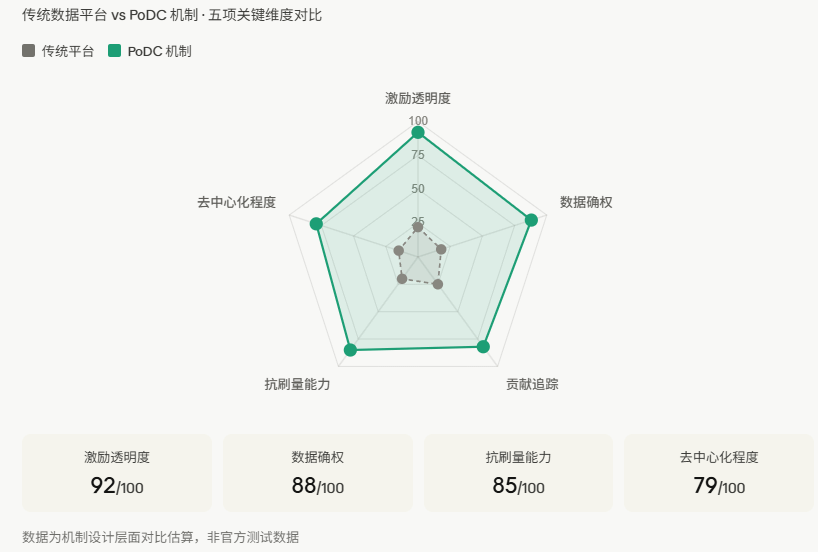
从上面这张对比图可以直观看出,传统数据平台在激励透明度、数据确权、贡献追踪等核心维度几乎全面落于下风,而PoDC机制在这些方向的设计评分都超过了75分以上。最值得注意的是"贡献追踪"这个维度——传统平台基本做不到,而这恰恰是整个PoDC价值主张的命脉所在
我之前那三个月标注数据的项目,之所以让我觉得憋屈,根本原因就在这里。我付出的时间和精力是真实的,但它转化成了什么、发挥了多少价值,我永远无法知晓。PoDC想解决的,就是这种"做了但看不见"的根本性信息不对称
值得一提的还有OpenLedger对不同类型数据贡献者的差异化设计。在网络里,普通用户可以通过日常的数字行为数据授权来参与,专业标注者可以通过结构化数据集提交获得更高权重的评分,而AI公司则以数据消费者的角色通过购买数据访问权来向整个网络注入流动性。这三类角色形成了一个相对完整的生态闭环,而不是只有一种参与方式的单向平台
我最近常常想,Web3做了这么多年,真正落地的应用场景到底在哪里?DeFi是金融的重构,NFT是所有权的重构,那PoDC可能就是数据经济的重构。它做的事情不复杂——把原来说不清楚的"你的数据被谁用了"变成一道可以公开验证的账目
这件事如果能做成,意义不亚于智能合约刚出现的那个时刻
那个深夜,我盯着白皮书读完最后一行,关掉屏幕,窗外天已经微微亮了。我没有马上去注册账号、没有马上去买代币,我只是在黑暗里坐了很久,觉得这个事情的方向是对的。有时候,光是看到一件事情在往对的方向走,就已经足够让人精神起来了
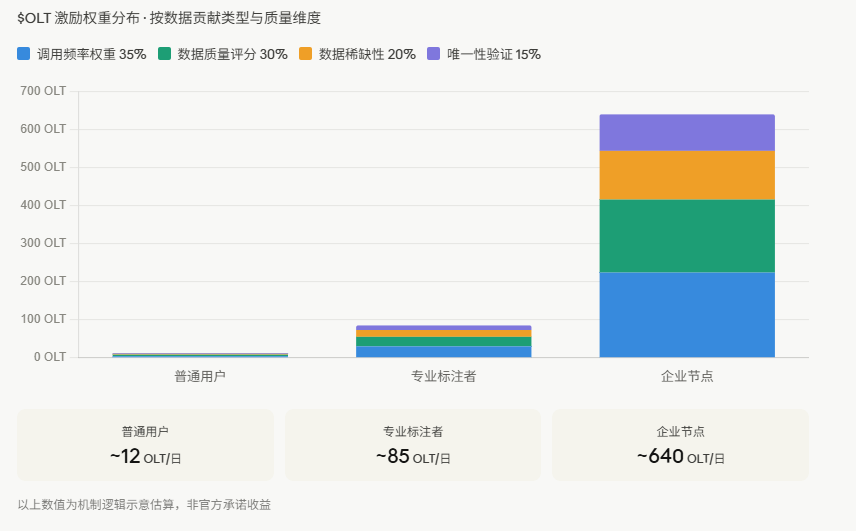
这张激励分配图直观呈现了一个重要逻辑:在PoDC体系里,贡献的质量和类型决定了你能拿到多少,而不是谁进场早或者谁的钱包余额厚。企业节点之所以每日估算收益遥遥领先,不是因为它们地位特殊,而是因为它们通常具备提供大规模、高质量、稀缺性结构化数据的能力。但这也意味着,一个普通个人贡献者如果能找到AI真正缺乏的数据类型,同样可以实现超预期的回报——这才是这套机制真正令人兴奋的地方
数据是AI时代的石油,每个人都说。但石油有油田有勘探权有产权记录,数据却长期处于一个没有产权、没有分账、没有追溯的野蛮状态。PoDC尝试给这片混沌画上边界,建立秩序
能不能成,需要时间验证