The words that changed how I read OpenLedger were not the loudest ones. They were the practical ones sitting around the developer flow: completions, API keys, request IDs, spend logs, token counts, model access, and usage records. That small accounting layer made the project feel different to me. OpenLedger is not only about Datanets feeding AI models, ModelFactory helping create specialized models, OpenLoRA making model deployment lighter, or Proof of Attribution linking outputs back to contributors. The sharper question is what happens when a user, app, or agent actually calls that intelligence.
That is where the AI request becomes important.
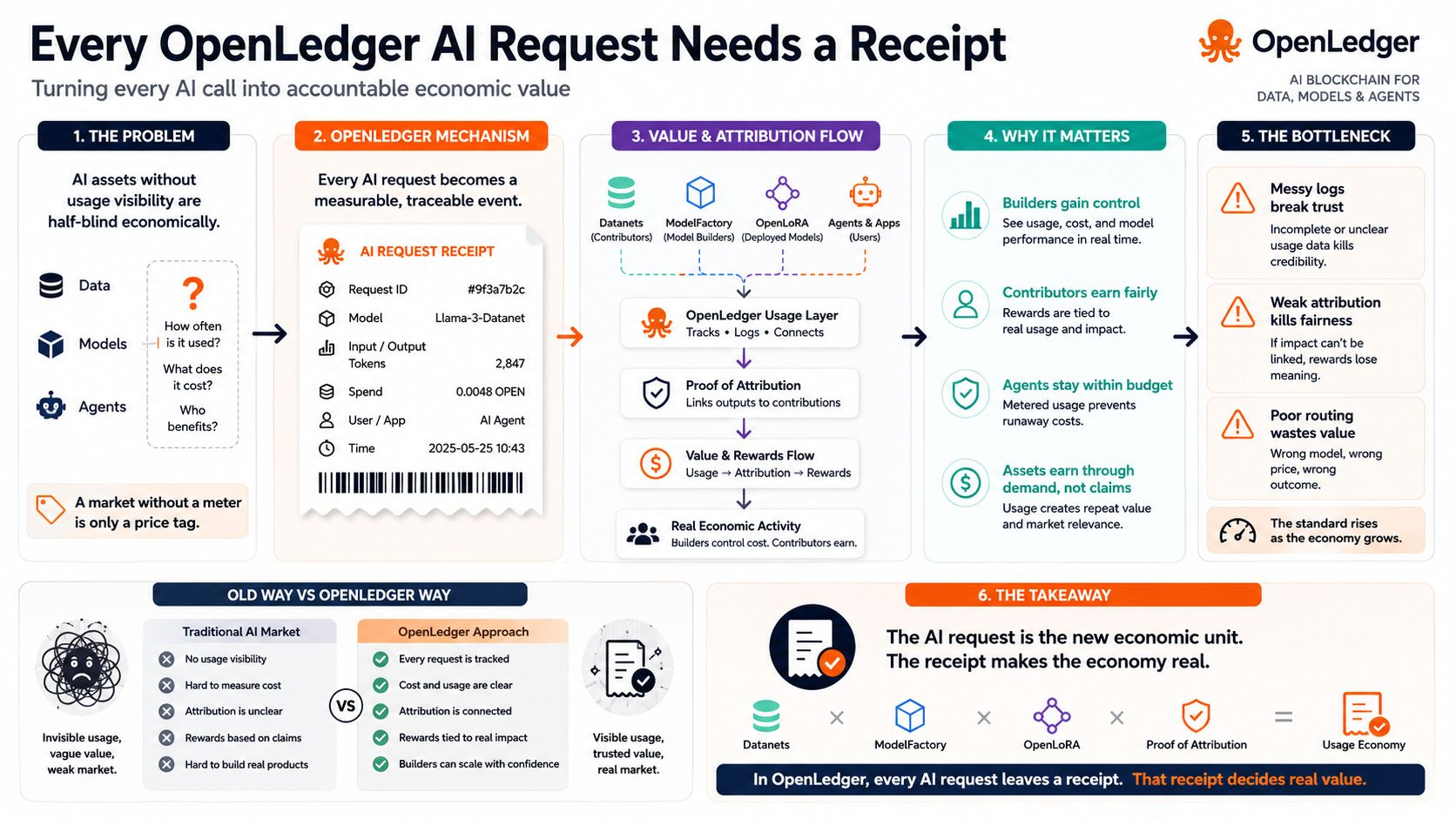
A dataset can be valuable. A model can be valuable. An agent can be valuable. But if nobody can see how often it is used, what it costs, which model handled the call, and which contribution mattered, then the asset is still half-blind economically. It may have a name. It may have ownership. It may even have a reward story. But it does not yet have a clean operating record.
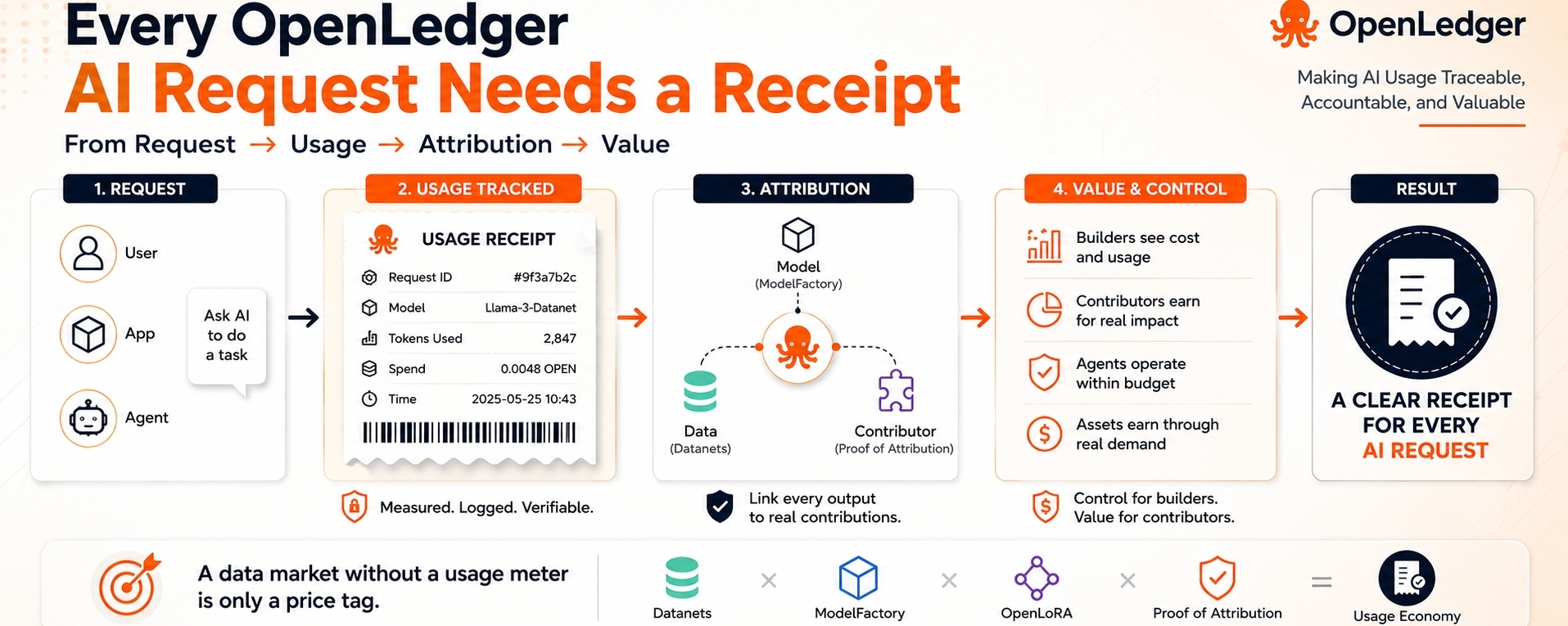
A data market without a usage meter is only a price tag.
That is why OpenLedger’s usage layer deserves more attention than it usually gets. Most people naturally focus on the reward side. Contributors want to know whether their data can earn. Model builders want to know whether their work can be credited. Token holders look for utility. Those are valid questions. But a builder running an actual app has a colder question: can I control usage before costs run away?
This is where OpenLedger’s mechanics become more serious. If a model is called through an API-style completion, that call can become more than a response on a screen. It can become an event with a model, a request, a spend record, token usage, user context, and an attribution path. That turns AI activity into something a builder can measure. And once it can be measured, it can be priced, limited, compared, repeated, or stopped.
That changes who has leverage.
Builders gain leverage because they are no longer buying vague access to “AI.” They can look at usage. They can see which model is being called. They can understand spend. They can decide whether a workflow is worth running again. Contributors also gain, but only if their contribution actually shows up in useful outputs. Low-impact data has fewer places to hide when the system is paying attention to usage, not just ownership claims.
The group that loses flexibility is the vague AI-asset seller. If an asset cannot attract repeated calls, cannot connect to useful outputs, or cannot be measured inside real usage, then its story weakens. It becomes inventory, not a market.
That is a harder claim, but I think it matters. AI monetization is easy to describe and difficult to operate. A project can say that data, models, and agents will earn. The harder part is proving that every earning path comes from something traceable: a request, a model call, a logged cost, an attribution signal, and a reason for someone to pay again. OpenLedger’s stronger lane is that it does not stop at “contributors should be rewarded.” It points toward a system where rewards can be tied to actual AI usage.
The agent side makes this even more important. A normal user may ask one question and leave. An agent can call models many times inside one task. It can create repeated demand, chained requests, and costs that grow faster than expected. Without spend visibility and model-level usage tracking, agents become a budget risk. With a meter, agent activity becomes something an operator can manage instead of fear.
This is the practical bottleneck. If OpenLedger’s economy scales, the pressure will not only come from whether enough data exists or whether enough models are created. It will come from whether usage stays clean enough to trust. Messy logs, unclear spend, weak attribution, or poor model routing would hurt the people who need the system most: builders trying to turn AI into repeatable products.
That is also the trade-off. More accounting creates more credibility, but it also raises the standard. Once the system says every AI asset can earn, it must also show why that earning is deserved. Once it says contributors can be rewarded, it must show which usage made the reward meaningful. Once it says agents can become economic actors, it must show how their activity can be tracked before it becomes uncontrolled cost.
This is why I see OpenLedger less as a simple AI-asset story and more as a usage economy. Datanets, ModelFactory, OpenLoRA, and Proof of Attribution are important pieces, but the request is where those pieces meet the market. That is where a builder sees cost. That is where a contributor proves influence. That is where a model earns repeat demand.
If OpenLedger can make each AI request leave a clear receipt, its economy becomes much harder to fake. Assets without usage lose power. Contributors without impact lose cover. Builders with clean records gain control.
In OpenLedger, the request may become the receipt. And the receipt may decide which AI assets are actually worth paying for.
