
前几天跟几个在硅谷做大模型的老朋友喝茶,大家聊起这两年AI圈子里的狂热,语气里多少都带点疲惫。
那时候ChatGPT刚火,科技巨头们每天都在放PPT,满屏幕都是“通用人工智能”、“硅基生命进化”、“人类文明新纪元”。投资人像疯了一样把几亿几亿的美金砸进那些连服务器都租不起的初创团队,生怕晚了一秒就错过了这趟开往未来的列车。台下的人举着手机,在各种社交媒体上转发那些真假难辨的生成效果,每当模型能多说几句通顺的人话,舆论就跟着高潮一次。
那时候的叙事多大啊,大到你如果只跟他们聊商业化,聊怎么赚钱,你都显得俗气。
但我混了这个圈子十几年,见过太多宏大叙事的起朱楼和宴宾客。回看当年那些喊着要颠覆传统金融的DeFi、要重塑生产关系的Web3,哪一个不是始于星辰大海,终于一地鸡毛?科技巨头们吹嘘的“硅基生命”,撕开那层华丽的极客滤镜,本质上不过是一场史无前例的“数字圈地运动”。
那些所谓的全能大忽悠,说白了,就是把全网创作者几十年积累的心血心安理得地免费爬走,塞进自己的数据库里,经过几万张显卡的暴力洗白,最后包装成高昂的订阅服务卖给大众。
大家都在谈论大模型正在改变世界,但其实大家都在默许这种心照不宣的白嫖。
但这个靠白嫖互联网公开数据堆出来的草台班子,现在的底层逻辑正在慢慢坍塌。网上的语料被搜刮干净了,创作者们开始拿起法律武器维权,科技巨头们发现,网上四处抄的通用模型在面对真正需要专业知识的垂类场景时,蠢得像个刚毕业的实习生。通用大模型的红利期正在见顶,继续堆显卡的边际效应越来越低。
就在这个大家都有些迷茫、有些幻灭的当口,我读到了OpenLedger的白皮书。
这本白皮书没有像其他AI项目那样,花几万字去论证自己的神经网络有多高级、算法架构有多精妙。它甚至连“改变人类命运”这种套话都懒得说。相反,我读到第2章那些关于分成和算账的段落时,突然笑出了声。
这哪里是什么人工智能的宏伟蓝图,这明明就是一本语料供应商给AI巨头们准备的催债账本。
它很坦然地承认了一个现实:那个靠全能大忽悠包打天下的时代已经过去了。未来的AI要想落地,就必须依赖懂行的垂类外包。而这些懂行的垂类外包,需要的是真正高价值、有门槛的专业数据。
但问题是,既然专业数据才是真正的金矿,人家凭什么要把自己压箱底的知识资产白白送给你去训练模型?
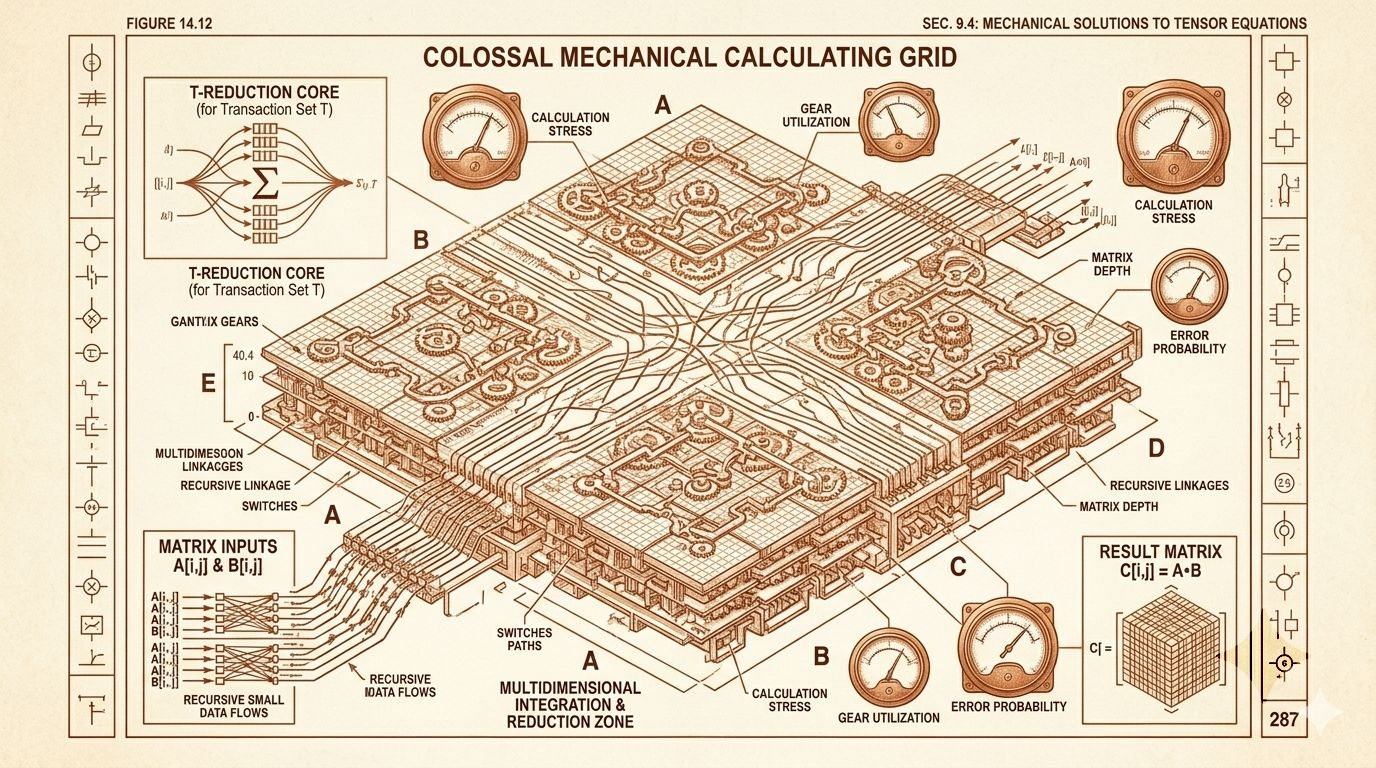
OpenLedger没有去讲什么保护创作者权益的高尚情怀,它直接搬出了一套极度现实的商业收银逻辑。
它说,我们不扯虚的,我们搞了一个叫做数据记账本的东西。任何人,只要你手里有专业的数据,或者你懂行、能帮模型做微调,你就可以把你的数据和能力放到这条链上。我们会用一套叫做按劳分配算盘的数学模型,去精确计算你提供的那条数据在AI最终生成答案的过程中到底起了多大作用。
每次AI只要张嘴回答一个问题,收银机就响一下,这也就是所谓的问答抽水。
这个问答抽水被收上来之后,会按照算出来的功劳比例,一分不差地打进喂语料的人、跑节点的矿工和开发模型的人的钱包里。
这套逻辑俗气吗?极度俗气。它把原本高高在上的AI极客情怀,彻底砸碎成了高速公路收费站的过路费。但你不得不承认,这恰恰是这个行业在经历狂热幻灭之后,最需要的一种诚实。
我们这些在Web3和AI行业里看惯了泡沫的老兵,往往对那些动辄要拯救全人类的口号产生了免疫甚至反胃。相反,OpenLedger这种“我就是个算账的,谁出力谁分钱”的反叙事,反而透着一种让人感到舒适的松弛和现实主义。
它直接把AI从虚无缥缈的神坛上拽了下来,放到了温饱线上的菜市场上。
你想用我的专业数据?可以,先交版权分账费。你想让模型开口说话?可以,留下你的问答抽水。在这样一个充满科技巨头肆意白嫖的世界里,这种极度世俗的记账逻辑,竟然成了普通人守卫数字资产所有权的唯一武器。
这就是它有趣的地方。它不再去卷大模型有多聪明,而是去卷怎么把大模型变成一台可追溯分账的流水线。
我们可以横向对比一下现在的AI和Web3跨界项目。
市面上大多数AI+Web3项目,依然在玩几年前那种老掉牙的套路:租几台服务器,套个开源的API,发个代币,就宣称自己是去中心化AI的领头羊。他们的白皮书里全是各种高大上的学术名词,但核心目的只有一个,那就是把币卖给那些看不懂代码的投机者,然后等着币价在牛市里被风口吹起来。
但OpenLedger在白皮书里写的数据记账本和模型流水线,逻辑冷酷得像一块冰冷的生铁。
在这个体系下,那些我们以前看不上眼的闲卡劣卡,似乎也有了新去处。它搞的那个AI套壳加工厂,其实就是把闲置的算力资源也收纳进来了,让多个定制化的模型共用一个底层骨架。这么做的好处是显而易见的,它不再逼着大家去买几万美金一张的顶级卡,而是用精密的算法把计算资源压榨到极致。
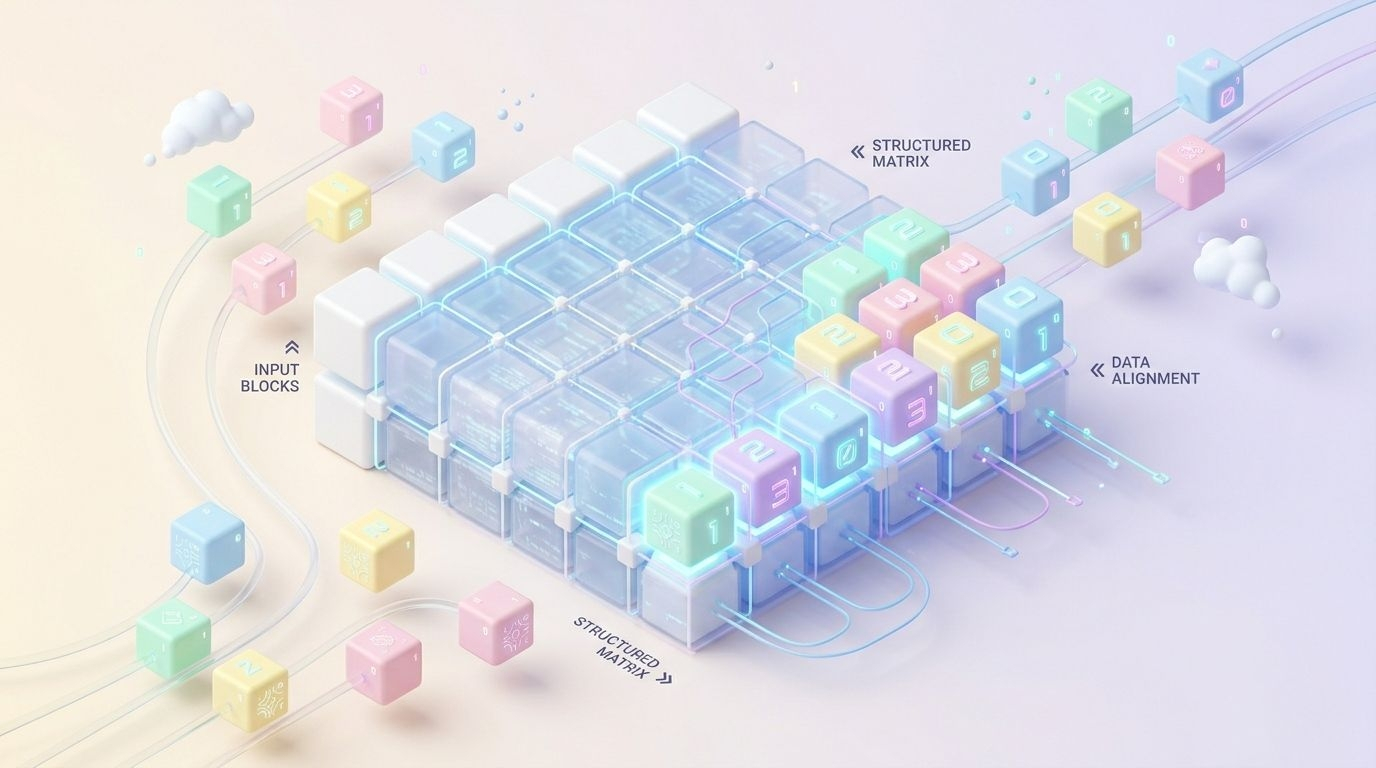
它给所有的参与者都画好了利益的边界。数据提供者要赚钱,必须提供真正能提升模型表现的干货,因为按劳分配算盘会冷静无情地过滤掉垃圾信息;模型开发者要想拿到分成,必须把模型真正部署上去并有人使用;Protocol Governors要想躺赚,必须把手里的Token抵押进去参与真实治理,去投票甄别哪些模型才是真正有市场需求的。这也就意味着,你想浑水摸鱼蹭热度是绝无可能的。
这里没有暴富神话的温床,只有精打细算的供应链生意。
这种极度真实、甚至有些冷血的分账机制,对于那些习惯了靠讲故事拿融资的团队来说,可能是一场灾难。因为在真实的使用场景下,你的模型有没有人用、你的数据有没有价值,每一笔问答抽水都会在链上记录得清清楚楚。代码不会撒谎,账本也不会配合你演戏。这就像是老菜市里的那杆公平秤,甭管你把自己的菜吹得多么天花乱坠,放上去一称,有几两分量立马现形。
但这恰恰是这个行业走向成熟的唯一路径。
早些年互联网数据随便爬、大模型闭着眼就能融到钱的草莽时代已经彻底结束了。未来的AI世界,注定是专业化、垂类化以及精细化运作的天下。当免费的公共数据被开采殆尽,AI的竞争就会演变成一场关于专业数据供应链的存量博弈。
而在这种存量博弈里,谁能率先建立起一套让数据所有者放心、让开发者有利可图、让算力提供者稳赚不赔的利益分配体系,谁就能在这条产业链上扎下最深的根。
OpenLedger不想去当那个最聪明的AI,它只想去当那个在AI菜市场门口收费的收银台。
对于那些习惯了在加密市场里追逐百倍币、万倍币的投机者来说,OpenLedger的白皮书可能会让他们感到无聊。因为这里没有能让他们一夜暴富的漏洞,只有用一串串数学公式搭建起来的抽水分账规则。你要想在这里面分一杯羹,你就得像个老老实实的作坊工人一样,要么去收集和清洗数据,要么去参与模型的微调,要么老老实实地去质押代币提供信用背书。
但这不就是生产力工具该有的样子吗?
我们不需要那么多虚无缥缈的AGI宏大叙事来麻痹神经,我们需要的是一个能给辛苦工作的语料农夫按时结账的收银台。在这个满是科技巨头白嫖的环境里,能用最俗气的账本逻辑把普通人的数字版权保护起来,并且还能让大家顺便赚点钢镚,这已经是我近几年看到的,最体面、也最诚实的Web3叙事了。
故事总会破灭,但收过路费的永远在赚钱。
在这个充满了噱头和泡沫的时代,我们或许不需要去赌哪一个大模型会成为最后的硅基上帝,我们只需要看看,当这群巨兽在疯狂吞噬数据的时候,是谁在台面下默默地拨弄着算盘,给每一个被白嫖的普通人,递上了一份迟到的版权账单。
这就是我在这本冰冷的白皮书里,看到的全部真相。