There is something oddly unfair about the way the AI world works right now.
We see the final result. A model gives an answer. An agent completes a task. A tool writes, summarizes, analyzes, predicts, or recommends something in seconds. It feels clean and almost effortless from the outside.
But it is not effortless.
Behind every useful AI system is a long chain of work that most people never notice. Someone created the data. Someone cleaned it. Someone labeled it. Someone trained or fine-tuned the model. Someone built the infrastructure. Someone tested the output, corrected mistakes, and made the whole thing more useful.
And yet, when money starts moving, many of those contributors are nowhere to be seen.
That is the gap OpenLedger is trying to fill.
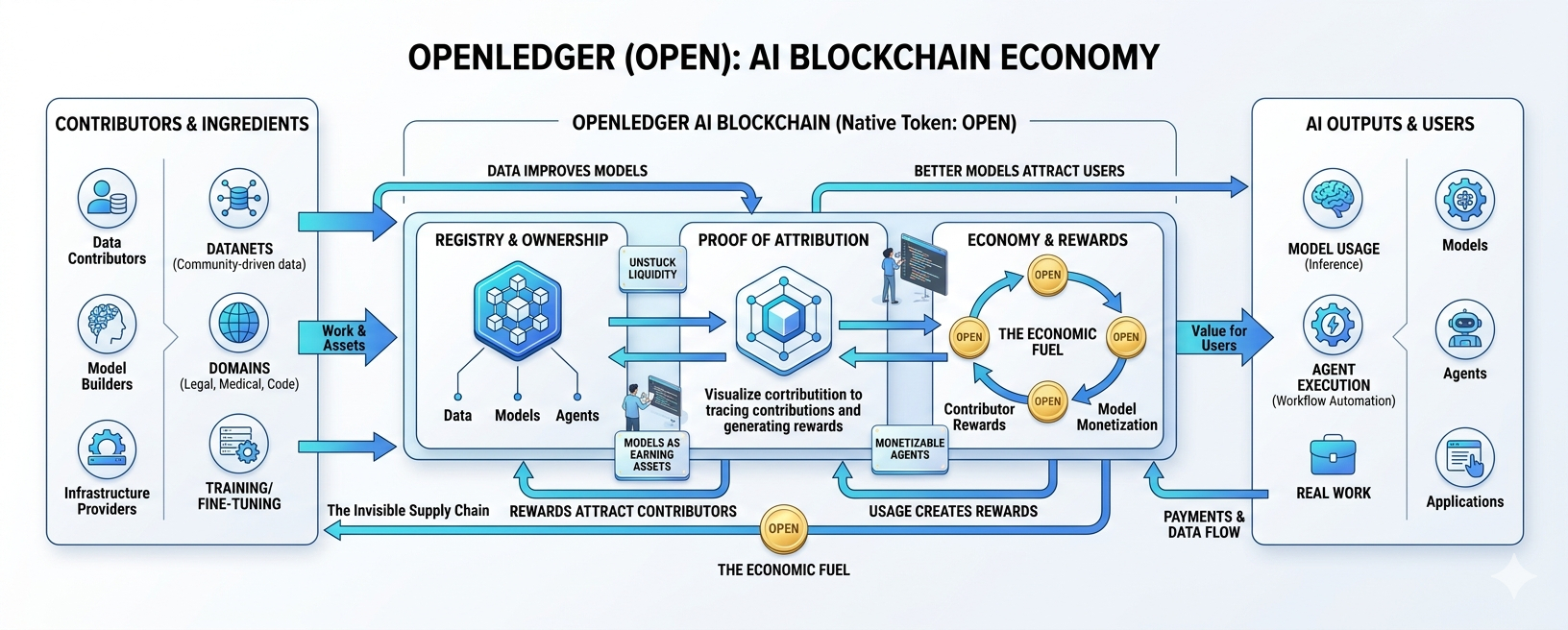
OpenLedger, with its native token OPEN, is building what it calls an AI Blockchain. The idea is fairly simple on the surface: make data, models, and agents traceable, usable, and monetizable. Instead of letting these assets disappear inside closed systems, OpenLedger wants to give them identity, ownership, and a way to earn.
 That may sound like a big Web3 idea, and it is. But the problem behind it is very real.
That may sound like a big Web3 idea, and it is. But the problem behind it is very real.
AI is creating a new kind of economy. The question is whether that economy will reward only the platforms at the top, or whether the people and communities providing the building blocks will also share in the value.
OpenLedger is betting on the second version.
The invisible supply chain behind AI
Most people interact with AI at the surface level.
They type something. They get a response. Maybe they use an agent to automate a workflow. Maybe they use a model to analyze a document or generate ideas. The experience feels direct: user in, answer out.
But that simple interaction hides a much deeper supply chain.
A useful model depends on data. Good data often comes from people with knowledge, experience, or access to a specific domain. It might be legal data, medical data, financial data, code examples, local-language content, scientific research, product documentation, or expert annotations.
That data does not organize itself.
It has to be collected, cleaned, structured, and improved. Then models need to be trained or fine-tuned. Agents need to be built around those models. Tools need to be connected. Infrastructure has to support everything in the background.
The problem is that once these ingredients are absorbed into a larger system, they often become hard to trace.
If a dataset helps improve a model, how do you prove it?
If a fine-tuned model powers a useful agent, who gets paid?
If an agent depends on multiple models and datasets, how should revenue be shared?
In most systems today, these questions are either ignored or handled privately by centralized platforms.
OpenLedger wants to make this process more transparent.
It wants the hidden supply chain behind AI to become visible enough that value can flow back to the people and assets that helped create it.
Proof of Attribution: the core idea
The most important concept in OpenLedger is Proof of Attribution.
The name sounds technical, but the idea is not difficult to understand. If a piece of data, a model, or an agent contributes to a useful output, the system should be able to recognize that contribution and reward it.
That is the heart of OpenLedger.
In today’s AI economy, attribution is messy. A model may produce a good answer, but it is rarely clear which data shaped that answer or which contributor helped make it possible. The final output gets attention. The underlying contributions usually do not.
OpenLedger is trying to change that by creating a system where AI assets can be registered, tracked, and rewarded when they are used.
simple way to think about it is royalties.
If a song is played, there is a system for paying the people connected to that song. It may not always be perfect, but the principle exists. OpenLedger wants to bring a similar idea to AI: when data, models, or agents help generate value, they should not vanish into the background. They should remain connected to the value they helped create.
That shift matters.
It changes data from something people give away once into something that can keep earning. It changes models from isolated files into economic assets. It changes agents from simple tools into revenue-generating systems with traceable parts underneath.
That is where OPEN comes in.
What OPEN is meant to do
OPEN is the native token of the OpenLedger network.
Its role is to move value through the ecosystem. It can be used for network fees, model registration, inference payments, contributor rewards, and governance.
Put more simply, OPEN is meant to be the economic fuel of the system.
When a developer registers a model, OPEN can be used.
When someone queries a model, OPEN can move through the payment flow.
When a dataset contributes to an output, OPEN can reward the contributor.
When the community votes on protocol decisions, OPEN can support governance.
The idea is to create a loop.
Useful data improves models.
Better models attract users.
More usage creates more rewards.
Rewards attract more contributors.
More contributors improve the network.
That is the flywheel OpenLedger is aiming for.
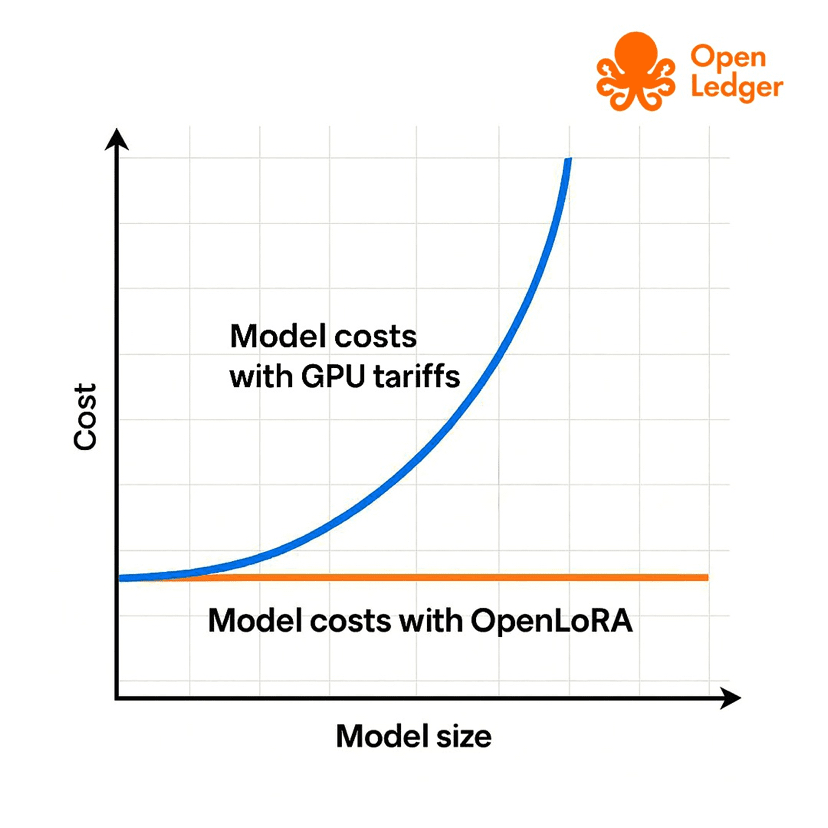
Of course, the real world is never as clean as a diagram. A token only matters if people actually use the network behind it. If $OPEN becomes disconnected from real activity, it becomes just another speculative asset. But if it is tied to real data, real models, real inference, and real agent usage, then the token has a more meaningful role.
That is the important difference.
OpenLedger is not just trying to launch a token around AI. It is trying to build an economy where the token moves through actual AI activity.
Data should be more than raw material
The strongest part of OpenLedger’s vision is its treatment of data.
For years, data has been treated like raw material. Companies collect it, process it, train on it, and turn it into products. The data itself may be extremely valuable, but the people behind it often have little control once it enters the system.
OpenLedger takes a different approach.
It treats data as an asset.
That matters most when we talk about specialized data. General internet data is everywhere, and a lot of it is repetitive or low quality. But domain-specific data is different. It can be rare, expensive, and extremely useful.
Think about legal contracts, medical terminology, financial research, local-language datasets, engineering notes, scientific annotations, customer support histories, or expert-labeled examples. This kind of data can make models far better at specific tasks.
The problem is that many people who own or create this data do not have an easy way to monetize it.
OpenLedger’s Datanets are designed to help with that.
A Datanet is basically a community-driven data network. People can contribute, organize, and improve datasets that may later be used for model training or inference. Instead of uploading data once and losing all future upside, contributors can remain connected to the value their data creates.
Imagine a group of legal experts building a dataset around contract clauses.
Or a community creating high-quality data for a language that most large models do not understand well.
Or developers organizing examples for a specific coding framework.
Or researchers building structured datasets for a scientific field.
If that data improves a model and helps produce useful results, contributors should have a way to earn from it. That is the point.
OpenLedger is not simply saying “data is valuable.” Everyone knows that already. It is trying to build a system where data can keep earning when it is actually useful.
Models as earning assets
Models are the next major piece of the OpenLedger economy.
A model is not just code. It represents training, testing, tuning, evaluation, and judgment. A good model often reflects a lot of hidden work.
But turning a model into a business is not easy.
A developer might build a model that performs well in a niche area, but then what? Hosting costs money. Distribution is hard. Users need to trust it. Payments have to be handled. Discovery is another problem. A model can be genuinely useful and still struggle to reach the people who need it.
OpenLedger wants to give model builders a more direct path.
By registering models on-chain, developers can make them visible and usable within the network. When users or applications access those models, payments can flow through the system. If the model relies on certain datasets, those contributors can also receive rewards.
This creates a more layered economy.
The model builder earns from usage.
The data contributor earns from impact.
The network supports the transaction.
The user gets access to a useful service.
That is the ideal version.
But there is an obvious challenge here: quality.
A network filled with random models is not automatically valuable. Users need to know which models are reliable, which ones perform well, and which ones are worth paying for. OpenLedger will need strong discovery tools, reputation systems, benchmarks, and filters.
Still, the direction makes sense. It gives independent builders a way to treat models as assets that can continue earning instead of one-time projects that fade into the background.
Agents make the whole idea more interesting
Agents are where OpenLedger’s vision starts to feel bigger.
A normal model responds to a request. An agent can do more. It can follow a goal, use tools, call different models, search information, make decisions, and complete multi-step tasks.
That makes agents powerful. It also makes them complicated.
An agent might use one model for reasoning, another model for writing, a dataset for retrieval, and a tool for execution. It may depend on several different contributors without the user seeing any of that complexity.
So when the agent creates value, who should get paid?
OpenLedger’s answer is that the system should be able to trace the components behind the agent and distribute rewards accordingly.
A research agent might rely on academic datasets and analysis models.
A customer support agent might depend on company-specific knowledge and a fine-tuned service model.
A coding agent might use documentation, repositories, and specialized model adapters.
A finance agent might combine market data, research models, and workflow tools.
The user may only see one clean interface. Underneath, though, there is a stack of assets working together.
OpenLedger wants that stack to become economically visible.
This could matter a lot as agents become more common. If agents are going to do real work, then payment systems around them need to mature. The developer of the agent should earn, yes. But so should the people and assets that make the agent useful.
That is the bigger idea behind monetizing agents.
It is not just about launching bots. It is about creating an economy where automated services can share value with the data and models beneath them.
Why blockchain makes sense here
It is fair to ask whether this needs a blockchain.
A lot of projects use blockchain when they probably do not need it. Sometimes a normal database would do the job better. So the question is reasonable.
For OpenLedger, the blockchain argument is stronger because the project deals with ownership, attribution, payments, public registries, and coordination between many different participants.
A blockchain can record who registered an asset.
Smart contracts can handle payment rules.
Tokens can coordinate incentives.
On-chain records can make activity easier to verify.
Governance can give participants a say in how the network changes.
That does not mean blockchain solves everything.
It will not automatically make data high quality.
It will not magically make attribution perfect.
It will not guarantee that developers show up.
It will not turn weak models into useful ones.
But it can provide a shared economic layer where different contributors, builders, and users interact without relying entirely on one central platform.
That is what OpenLedger is really trying to build.
Not blockchain for decoration. Blockchain as an accounting and coordination system for AI assets.
What “unlocking liquidity” really means
When OpenLedger talks about liquidity, it is not only talking about trading OPEN on exchanges.
The deeper idea is that data, models, and agents can become liquid.
A dataset becomes liquid when it can be registered, discovered, used, and rewarded.
A model becomes liquid when people can access it, pay for it, and build with it.
An agent becomes liquid when its services can generate revenue and share that revenue with the components behind it.
That is a different kind of liquidity.
It is about turning useful but trapped assets into active economic assets.
A dataset sitting in a private folder may be valuable, but if nobody can find it, use it, or pay for it, its value is stuck.
A model built by a skilled developer may solve a real problem, but if there is no market around it, the value stays limited.
 An agent may perform useful work, but if there is no transparent way to reward the assets behind it, the system becomes unfair.
An agent may perform useful work, but if there is no transparent way to reward the assets behind it, the system becomes unfair.
OpenLedger is trying to unlock that trapped value.
That is why the liquidity message matters. It is not just financial language. It points to a future where the building blocks of AI can move through markets instead of remaining hidden inside closed systems.
The promise is strong, but the hard parts are real
OpenLedger has a compelling vision.
A fairer AI economy.
Better rewards for data contributors.
New monetization paths for model builders.
Agents that can share revenue across the stack.
A network where useful contributions do not disappear.
But the challenges are serious.
The biggest one is attribution. Knowing which data influenced an output is not easy. Models are complex. Outputs are shaped by huge numbers of examples, weights, prompts, and tuning decisions. OpenLedger’s Proof of Attribution has to be reliable enough for people to trust it with money.
Data quality is another challenge. If contributors can earn rewards, some people will try to game the system. They may submit duplicate, low-quality, or misleading data. The network will need strong curation and verification.
Then there is adoption. Developers already have tools and platforms they know. They will not switch just because a new idea sounds good. OpenLedger has to make building easier, more profitable, or more open than the alternatives.
And then there is token sustainability. OPEN needs real demand from real activity. If the token economy grows faster than the actual product economy, the whole thing becomes fragile.
These are not minor details. They will decide whether OpenLedger becomes useful infrastructure or remains an interesting concept.
Why OpenLedger feels timely
OpenLedger is arriving at a moment when people are asking harder questions about AI.
Who owns training data?
Who should be paid when models use public or private knowledge?
How can creators and developers share in the value they help produce?
Can AI infrastructure become more open without becoming chaotic?
Can contributors earn without slowing down innovation?
These questions are not going away.
As AI becomes more deeply embedded in work, business, research, and daily life, the economics behind it will matter more. People will care not only about what AI can do, but also about who benefits from it.
That is why OpenLedger feels relevant.
It is trying to build an answer before the problem becomes even bigger. Its answer may not be perfect yet, and no project has fully solved decentralized AI attribution at scale. But the direction is important.
AI creates enormous value. The value chain behind it is still too hidden.
OpenLedger wants to make that chain visible enough to pay people fairly.
What success would actually look like
The success of OpenLedger should not be judged only by the price of $OPEN .
That would be too narrow.
Real success would look like active Datanets producing useful datasets. It would look like developers publishing models that people genuinely use. It would look like agents earning revenue from real tasks. It would look like contributors receiving rewards because their data actually improved results.
Most importantly, it would look like people using OpenLedger because it solves a real problem, not because it has a good narrative.
That is the standard.
The project has to prove that contributors can add assets, receive attribution, earn rewards, and build applications without dealing with too much friction. If the experience is too complicated, only a small group of crypto-native users will care. If it is simple and useful, the idea becomes much bigger.
In the end, most people do not care about infrastructure. They care about whether something works.
OpenLedger has to work.
Final thoughts
OpenLedger is trying to solve a problem that sits right underneath the AI boom: how to reward the hidden contributors behind intelligent systems.
Data has value.
Models have value.
Agents have value.
 The people who create and improve them should not disappear once that value reaches the end user.
The people who create and improve them should not disappear once that value reaches the end user.
That is the simple belief behind the project.
OPEN is designed to power the economy around that belief. Datanets help organize useful data. Model infrastructure gives builders a way to monetize their work. Agents expand the system into real services. Proof of Attribution tries to connect value back to the contributors who helped create it.
There are risks. Attribution is difficult. Data quality matters. Adoption will take time. Token demand has to come from real usage.
But OpenLedger is pointing at a real issue.
The next phase of AI will not only be about bigger models or faster tools. It will also be about ownership, transparency, incentives, and fair participation. It will be about making sure the value created by intelligent systems does not only flow to the platforms at the top.
OpenLedger’s vision is that data, models, and agents should not remain invisible.
They should be traceable.
They should be usable.
They should be liquid.
And when they create value, they should be able to earn.