I almost didn't write this. Honestly, I have been sitting on my thoughts about @OpenLedger for a while because every time I start typing, it comes out sounding like a press release. So let me just talk through it the way I would with someone over coffee.
The moment it clicked for me
I have a friend who builds data pipelines. Not a crypto person at all. He mentioned a few weeks ago that his team has been sitting on a specialized dataset for almost two years with zero idea how to monetize it. Licensing conversations go nowhere. Selling it outright means giving up ownership. He was looking at OpenLedger as a possible solution and that stopped me cold. When someone outside the token bubble starts sniffing around a protocol for a real business reason, I take that seriously.
What OpenLedger is actually doing
The short version is this. AI models need data to get better. Good data is getting harder to find. The big labs are paying Reddit and news archives for scraps of usable content because the easy public internet stuff is basically exhausted. Meanwhile there are organizations everywhere sitting on genuinely valuable datasets with no clean way to get paid for them.
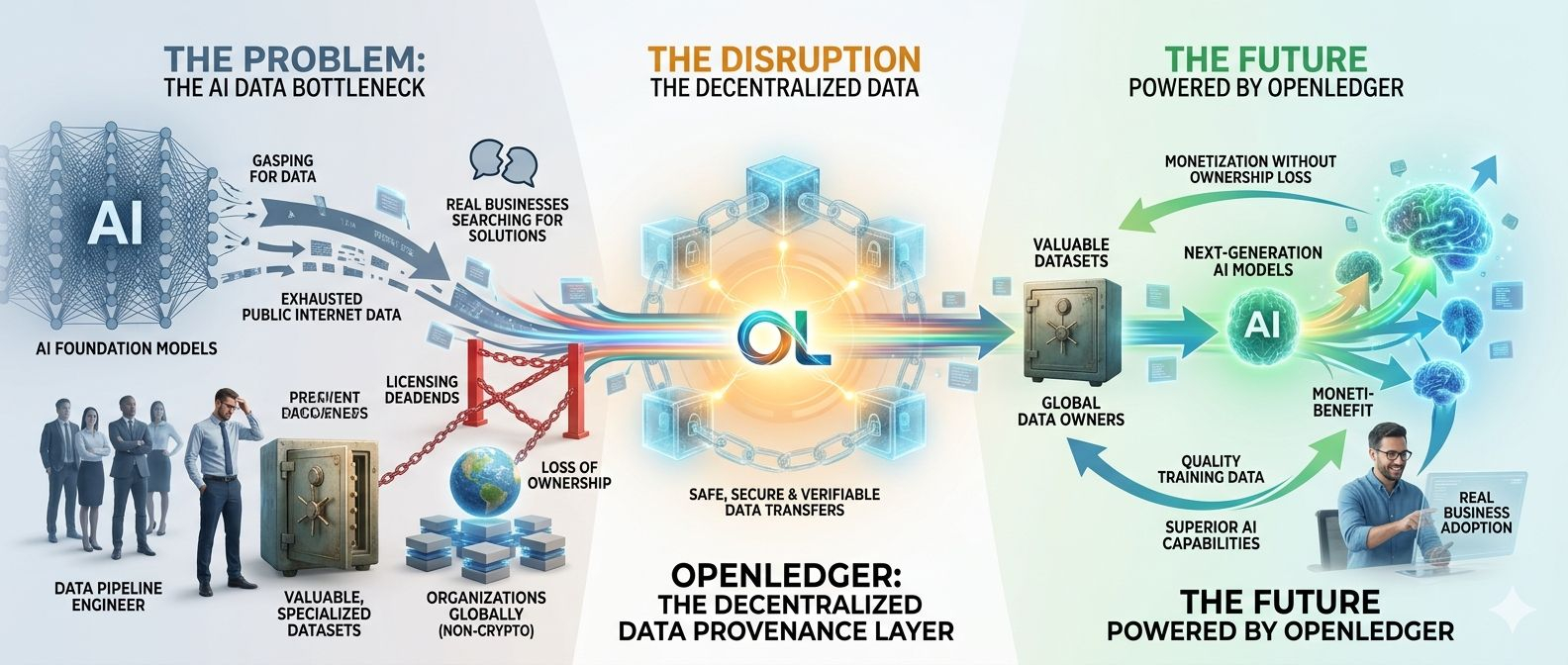
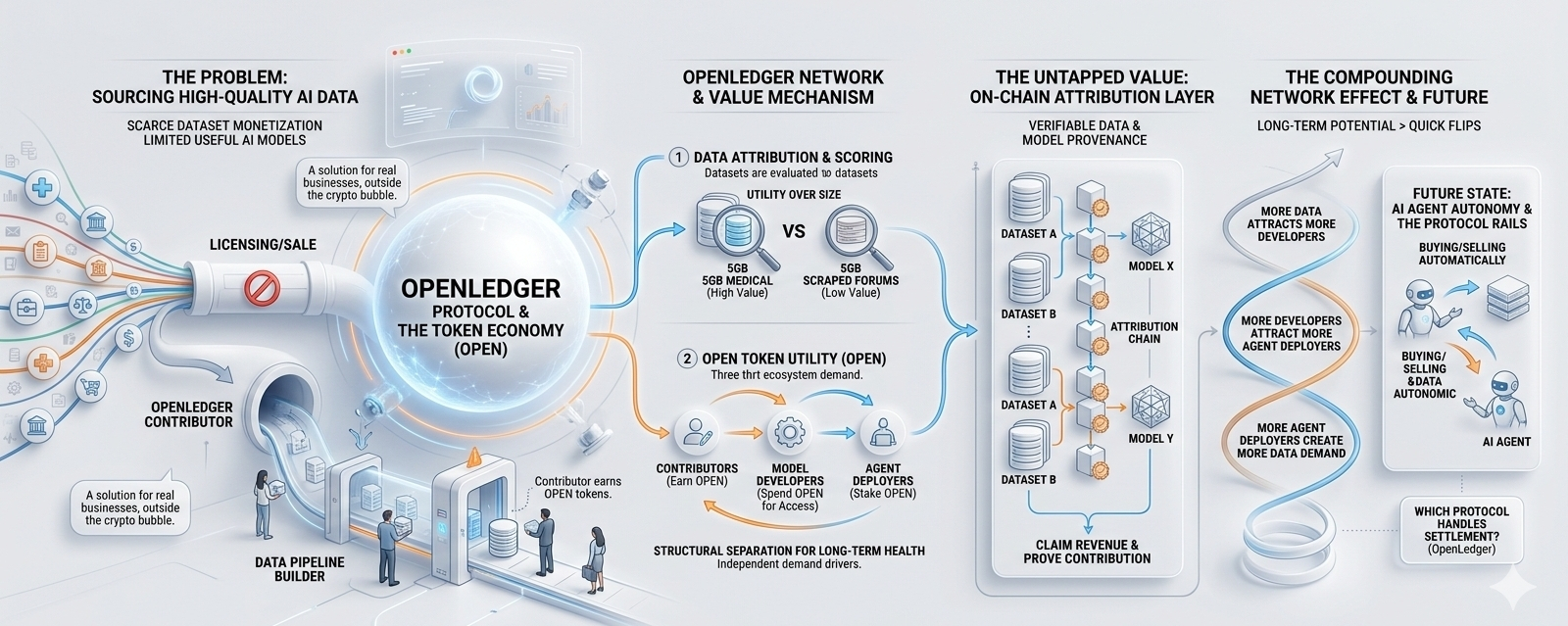
OpenLedger built a network where you contribute your dataset on-chain, it gets scored based on how useful it actually is, not just how big it is, and you earn OPEN tokens. That utility scoring piece is what I keep coming back to. A 5GB dataset from a niche medical or legal domain gets priced differently than 5GB of garbage scraped from random forums. That distinction is the whole ballgame if you want serious contributors showing up instead of people gaming a rewards system.
Why I think the token makes sense here
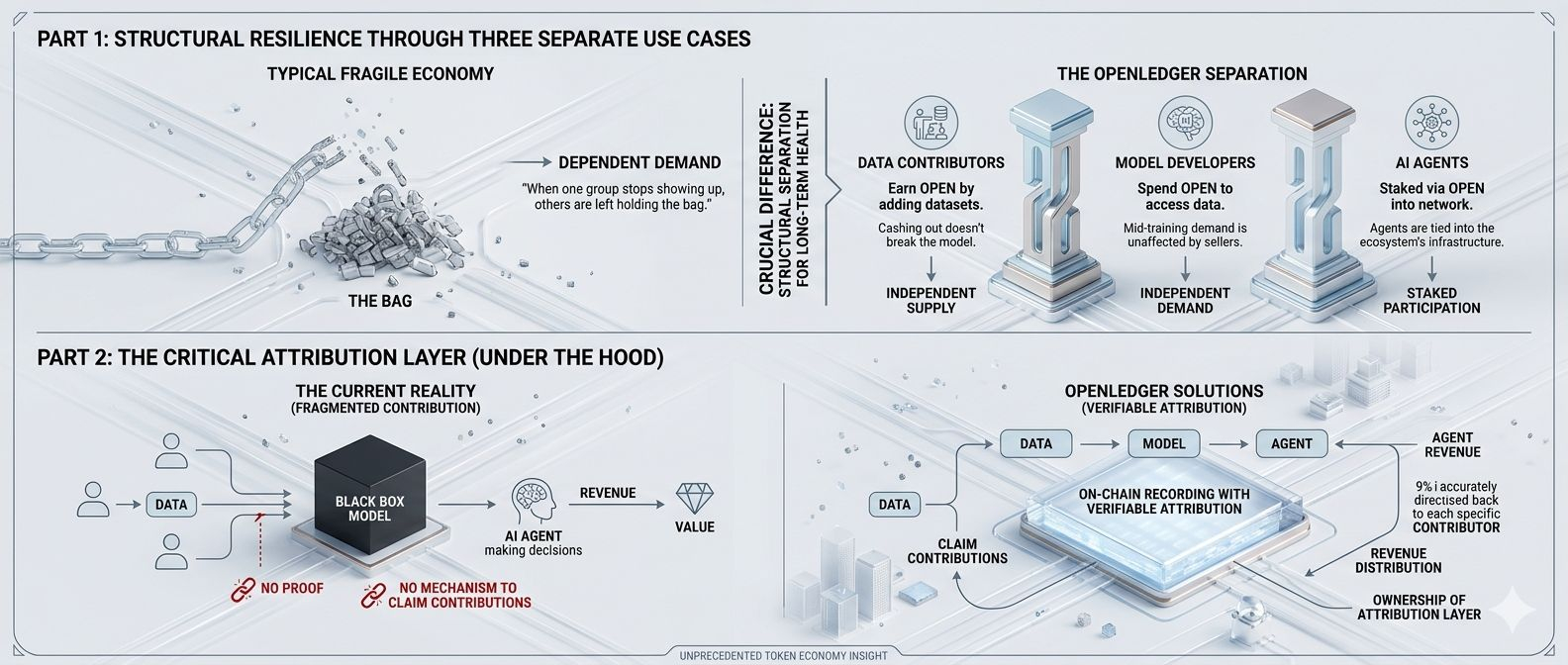
I have watched a lot of token economies fall apart and the pattern is almost always the same. One group of people holds the bag when another group stops showing up. What I find interesting about OPEN is that three separate groups need it for completely different reasons. Data contributors earn it. Model developers spend it to access datasets. Agents get staked into the network using it. These groups are not dependent on each other staying excited at the same time. A data contributor cashing out does not crash demand from a model developer mid-training run. That kind of structural separation is genuinely rare and I think most people tracking this project have not fully thought through what it means for long-term token health.
The part nobody talks about
There is something under the hood that I think matters more than the marketplace itself. Every dataset and model deployed through OpenLedger gets recorded on-chain with verifiable attribution. Right now if an AI agent makes decisions using a model trained on your data and that model generates revenue somewhere, you have no way to prove your contribution or claim anything from it. No mechanism exists. OpenLedger is building that mechanism. For anyone paying attention to where AI and Web3 intersect over the next few years, ownership of that attribution layer is a very big deal.
I am not buying OPEN looking for a quick flip. The chart is not what I am watching. I am watching whether real contributors and real model developers show up over the next year. Because if they do, the whole thing compounds on its own. More data attracts more developers. More developers attract more agent deployers. More agent deployers create more demand for quality data. That loop does not need a bull market to run.
The thing I keep thinking about is this. When AI agents start buying and selling data and models from each other automatically, which protocol handles that settlement? Because that market is coming whether we are ready for it or not, and somebody is going to own the rails underneath it.