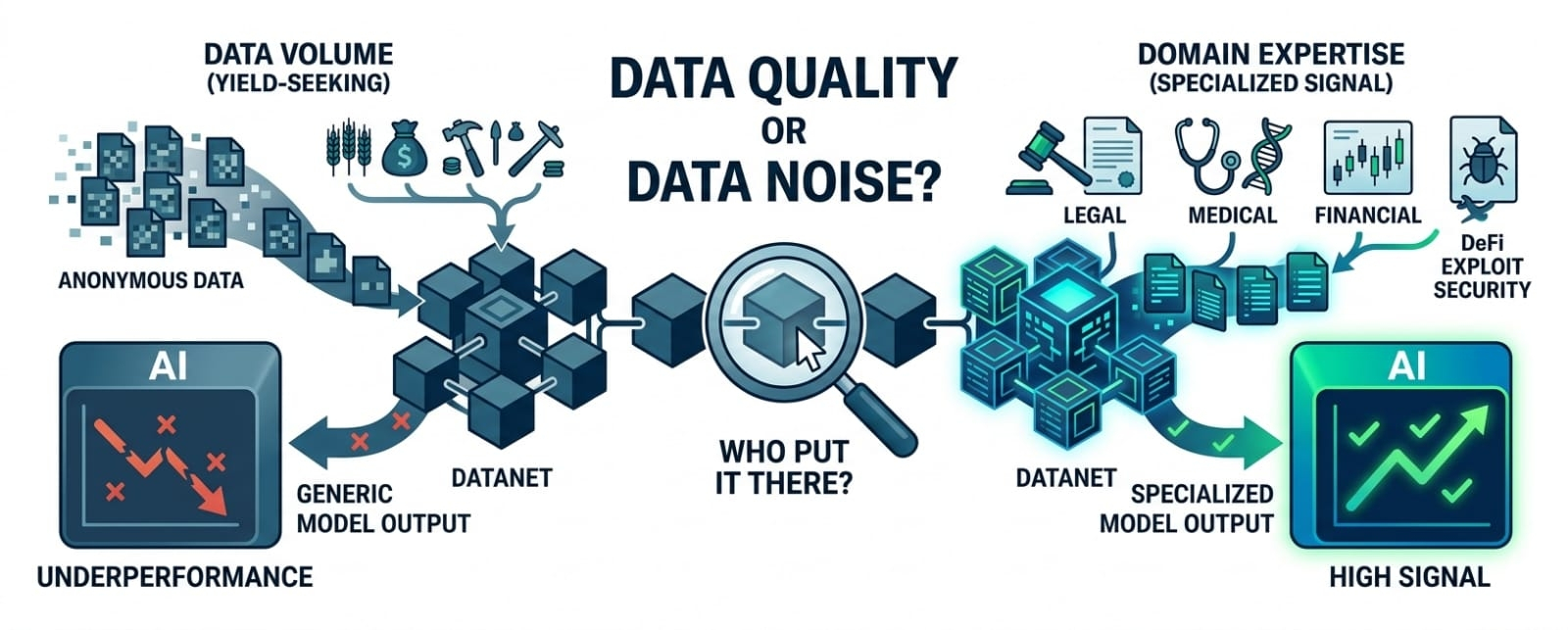
Something about the Datanet contribution model kept pulling me back after I first looked at it. Not the architecture the architecture is coherent. What bothered me was a simpler question that I couldn't find a clean answer to anywhere in the documentation or the on-chain activity: who is actually contributing data to these Datanets, and what do they know about the domain they're contributing to? OpenLedger's entire model quality argument rests on Datanets producing specialized, high-signal training data for narrow domains legal contracts, medical records, financial transactions, DeFi exploit patterns. That specificity is the point. A generalist dataset produces a generalist model. The value proposition of OpenLedger's Specialized Language Models only holds if the data feeding them is genuinely domain-relevant and contributed by people who understand the domain well enough to know what good data looks like.
The mechanism OpenLedger uses to incentivize contribution is token rewards distributed through Proof of Attribution. Contribute data, get attributed, earn OPEN when that data influences a model output. That's the loop. The problem is that this reward structure doesn't differentiate between a legal professional contributing carefully structured contract clauses and a yield-seeker uploading publicly scraped text that happens to contain legal language. Both contributions get hashed, recorded on-chain, and enter the attribution pipeline. The blockchain verifies that the contribution happened. It doesn't verify that the contribution was good. Data quality is not a property the chain can measure directly it's a downstream consequence that only surfaces when model performance either meets or fails to meet the specialized standard the Datanet was supposed to produce.
This is where the consequence gets interesting and slightly uncomfortable. If the contributor base skews toward yield-seekers rather than domain experts and there's a reasonable structural argument that it would, given that the reward mechanism selects for participation volume rather than participation quality then the Datanets fill up with data that looks valid on-chain but performs poorly in training. The models that get built on top of those Datanets underperform against their specialized claims. Developers who integrated those models for domain-specific tasks notice the gap between the documented capability and the actual output quality. They don't make a loud announcement about it. They quietly route their inference requests elsewhere. And the demand side of OpenLedger's economic loop the inference payments that are supposed to reward contributors and validators and sustain OPEN token velocity doesn't materialize the way the model predicts, not because the infrastructure failed but because the data underneath it was never as specialized as the contribution numbers implied.
What keeps bothering me is that this failure mode is invisible until it isn't. On-chain, everything looks healthy. Contribution counts are up. Datanets are active. Attribution events are being recorded. The token is moving. None of those metrics distinguish between a Datanet that is genuinely building specialized model capability and one that is accumulating well-formatted noise. The only moment of truth arrives when someone actually tries to use a model trained on that data for a real task in the domain it was supposed to specialize in and by then, the infrastructure has been built, the marketing has been done, and the developer integrations have been announced. I'm less interested in whether OpenLedger's chain works. I'm more interested in whether anyone is currently measuring Datanet quality at the contribution level rather than the contribution volume level, and whether that measurement exists anywhere outside the core team's internal tooling.
There is a version of this where I'm wrong. OpenLedger could have curator mechanisms or contribution quality filters that aren't prominently documented but are operating quietly something between the raw upload and the attribution record that filters signal from noise before it enters the training pipeline. If that exists and works, the data quality problem is managed at the source rather than discovered at inference. What I'd want to see, and haven't seen yet, is a public breakdown of contributor demographics across at least one active Datanet not wallet counts, not transaction volumes, but evidence that the people contributing to a legal Datanet have any proximity to legal work, or that the people feeding a DeFi exploit dataset are actually security researchers rather than farmers looking for attribution events. That one transparency signal, appearing from any Datanet currently active on mainnet, would fundamentally change how seriously I take the specialized model claim and its absence is currently doing more work in my thinking than anything else about this protocol.
