Other Than OpenLedger Is Seriously Trying To Fix It
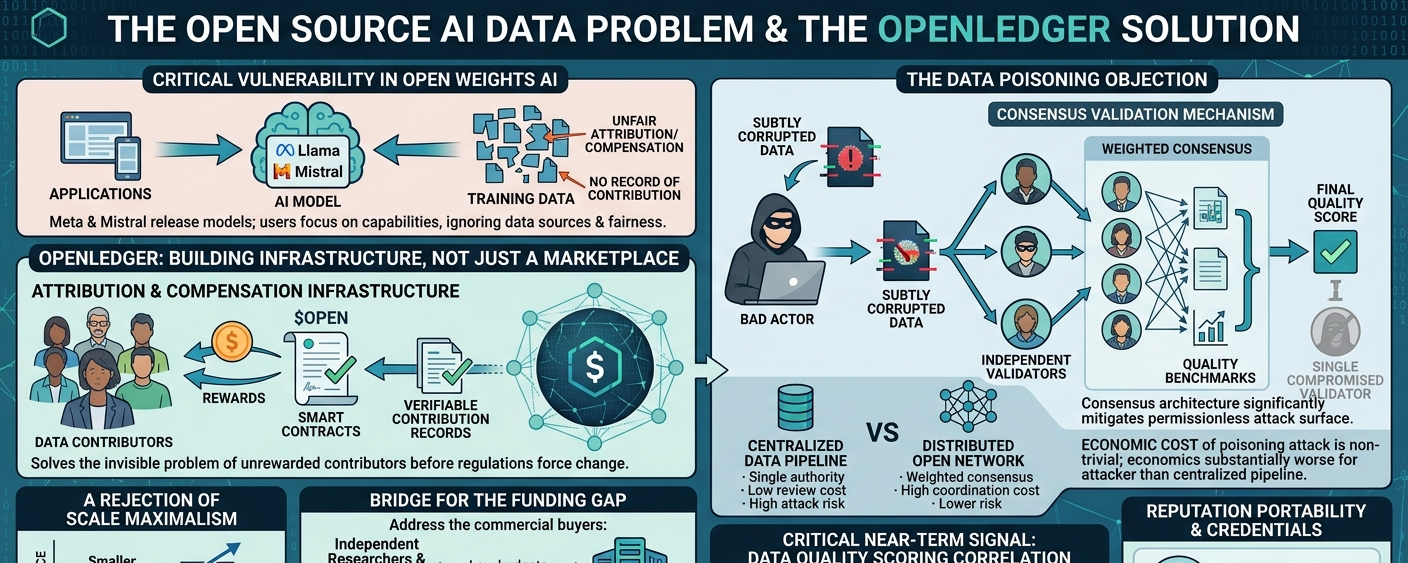
The open weights AI movement is one of the most significant shifts in the technology industry over the last two years and almost nobody is talking about its most critical vulnerability. When Meta releases a Llama model or Mistral publishes open weights the discussion immediately focuses on what the model can do and how quickly developers can build applications on top of it. The conversation almost never turns to the training data that produced those capabilities and whether the organizations and individuals who generated that data received anything resembling fair attribution or compensation for their contribution to a model now being used commercially by thousands of companies worldwide.
This is the context in which I think about $OPEN most seriously. OpenLedger is not just building a data marketplace for AI labs with large procurement budgets. Its building attribution and compensation infrastructure for a world where AI model training is increasingly distributed across open source ecosystems where the current norm is that data contributors receive nothing and have no record of their contribution existing at all. That is a problem that will not stay invisible indefinitely and the protocol that builds credible infrastructure for solving it before regulatory or community pressure forces the issue is going to be in a structurally advantaged position.
The data poisoning problem is one I want to address directly because it is the most common technical objection I hear raised against open contributor data networks. The concern is legitimate. When you allow permissionless contributions to a dataset used for AI training you create an attack surface where bad actors can submit subtly corrupted or adversarially crafted data designed to influence model behavior in specific undesirable ways. This is not a theoretical risk it has been demonstrated in academic literature and in real-world incidents involving open data crawling pipelines. The question is not whether the risk exists but whether OpenLedger’s validation architecture actually mitigates it.
What I find credible about the @OpenLedger approach to this problem is the consensus validation mechanism. Individual validators dont have unilateral power to approve or reject submissions. Validation outcomes are determined by weighted consensus across multiple independent validators whose assessments are compared against each other and against automated quality benchmarks before a final quality score is assigned. A single compromised or low-quality validator cannot meaningfully influence the outcome for a well-reviewed submission because their score is weighted against the broader consensus. That distributed validation design doesnt eliminate poisoning risk entirely but it raises the cost of a successful poisoning attack significantly above what most open data networks require.
And the economic cost of a poisoning attack in this system is non-trivial. An actor attempting to introduce adversarial data at scale would need to either compromise multiple independent validators simultaneously which requires significant capital and coordination or submit enough volume of subtly corrupted data to slip through consensus validation which becomes exponentially harder as the validator network grows in size and expertise. Im not saying its impossible. Im saying the attack economics are substantially worse than what you face against a centralized data pipeline with a single approval authority and a small internal review team.
My frustration is with how the open source AI community talks about data. The same developers who spend hours debating model architecture choices and training hyperparameters often treat dataset quality as an afterthought assuming that scale compensates for noise and that more data is always better than carefully curated data. The research increasingly does not support that assumption. Studies on data pruning and quality filtering consistently show that training on a smaller highly curated dataset outperforms training on a larger noisier one for a wide range of benchmark tasks. OpenLedger is essentially building the infrastructure that makes high-quality curated data economically producible at scale and I think that thesis is going to age better than the scale maximalism that currently dominates AI training discourse.
But here is my honest concern about the open source AI angle specifically. The organizations most likely to benefit from a verified high-quality open data protocol are also the organizations least likely to have budget for accessing it in its early commercial phases. Independent researchers small open source collectives and academic teams all have genuine need for the kind of attributed verified training data that @OpenLedger produces but they often operate with near-zero data acquisition budgets. The commercial buyers who can actually pay for dataset access are the mid-to-large AI companies and those companies have the internal resources to build their own data pipelines even if those pipelines are inferior. Bridging that gap between the users who need the product most and the buyers who can actually sustain the economics is a challenge I dont think has been cleanly addressed yet.
The reputation portability question is something I think will become increasingly important as the protocol matures. A contributor who builds a strong verified reputation inside the OpenLedger network has demonstrated something real about their ability to produce high-quality structured knowledge. That on-chain reputation record is currently valuable within the protocol but I think about the downstream potential of a verifiable contributor reputation that AI developers can query when making decisions about dataset sourcing. Its essentially a professional credential for data work and the infrastructure for that kind of credential doesnt exist anywhere in the current ecosystem in a form that transfers across platforms or organizations.
I will say directly what I think the most important near-term signal for $OPEN will be. Its not token price and its not total contributor count. Its whether the dataset quality scores produced by the OpenLedger validation network correlate measurably with model performance improvements when AI developers actually train on the data. If that correlation is demonstrable and publishable then the project moves from an interesting infrastructure thesis to a product with proven utility and the enterprise adoption conversation changes completely. Without that correlation evidence the project remains compelling theory and I have seen too many compelling theories fail at the validation step to invest confidence ahead of that evidence.
Thats my read. Smart architecture. Real problem. Unproven at the outcome level that actually matters to serious buyers. Im still watching and my watch list is not long.