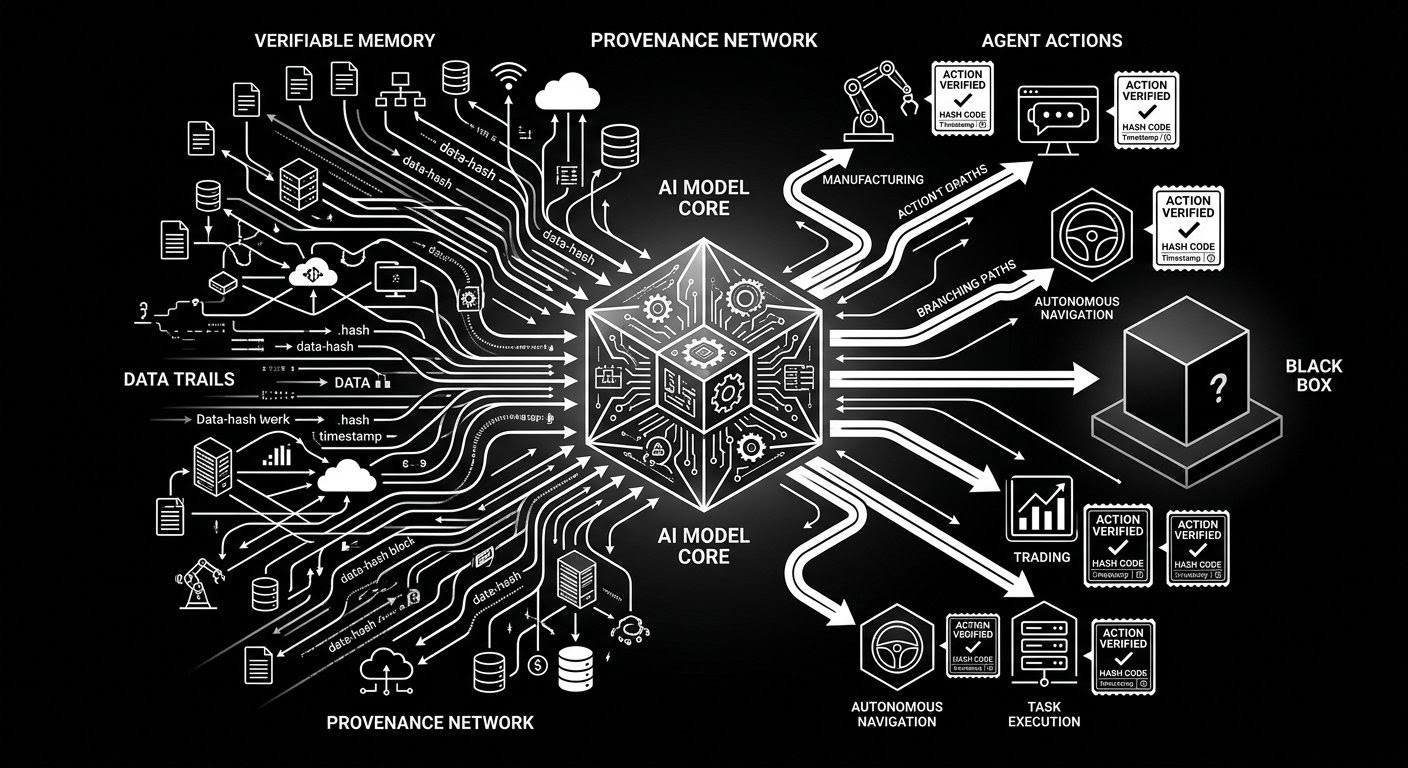

OpenLedger pone la domanda che la maggior parte dei progetti AI ignora. Non quanto velocemente possiamo costruire modelli, ma se i sistemi che costruiamo possono ancora essere tracciati una volta che iniziano a compiere azioni che muovono denaro reale.
Un chatbot che dà una risposta sbagliata è un errore che puoi cancellare. Un agente AI che gestisce capitale, esegue un trade o distribuisce un contratto basato su influenze nascoste è una transazione che non puoi annullare. Gli errori vengono corretti. Le transazioni vengono chiuse. E una volta che il regolamento avviene, l'unica cosa che conta è se possiamo leggere il sentiero che ha portato alla decisione.

Gli Agenti Trasformano i Modelli in Infrastruttura :
Per anni l'IA è stata costruita per dimenticare. I dati fluivano, i pesi si formavano e un modello veniva spedito senza memoria di chi lo avesse plasmato. Questo funzionava quando i modelli rispondevano solo a domande, perché le domande non muovono portafogli. Gli agenti hanno distrutto quella supposizione.
Gli agenti non generano solo testo. Ricercano mercati, instradano capitale, gestiscono flussi di lavoro, attivano azioni on-chain e chiamano API. Nel momento in cui un agente agisce, il modello sottostante smette di essere un progetto di ricerca. Diventa infrastruttura. E l'infrastruttura senza provenienza è solo automazione che chiede fede cieca.
Il problema diventa più acuto perché l'IA specializzata funziona su dati specializzati. Gli agenti finanziari si allenano su corpus di comportamenti di trading, strategie DeFi, storie di rischio e segnali di mercato etichettati. Questi non sono scrapes generici di internet. L'influenza è concentrata. Ogni fine-tune è un filtro che decide quali segnali vengono amplificati e quali vengono scartati. Se non c'è traccia di quelle scelte, l'influenza diventa invisibile. Quando il valore fluisce, o quando le perdite colpiscono, non c'è un percorso per la Proof of Attribution per verificare chi ha contribuito a cosa.
OpenLedger ModelFactory rende la creazione responsabile :
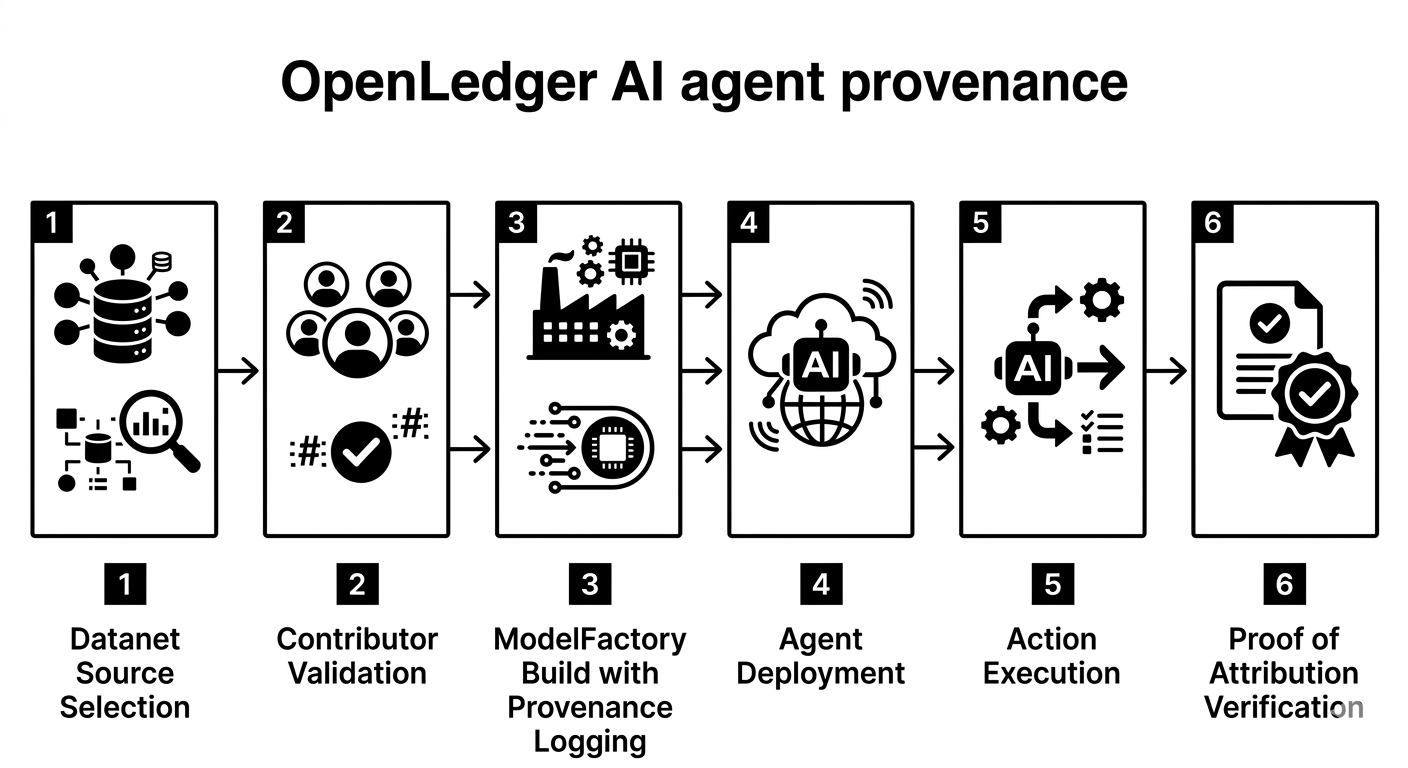
OpenLedger ModelFactory sembra uno strumento IA a basso codice a prima vista. Il vero cambiamento è più profondo. Trasforma la creazione di modelli in parte di un'economia di attribuzione dal primo clic.
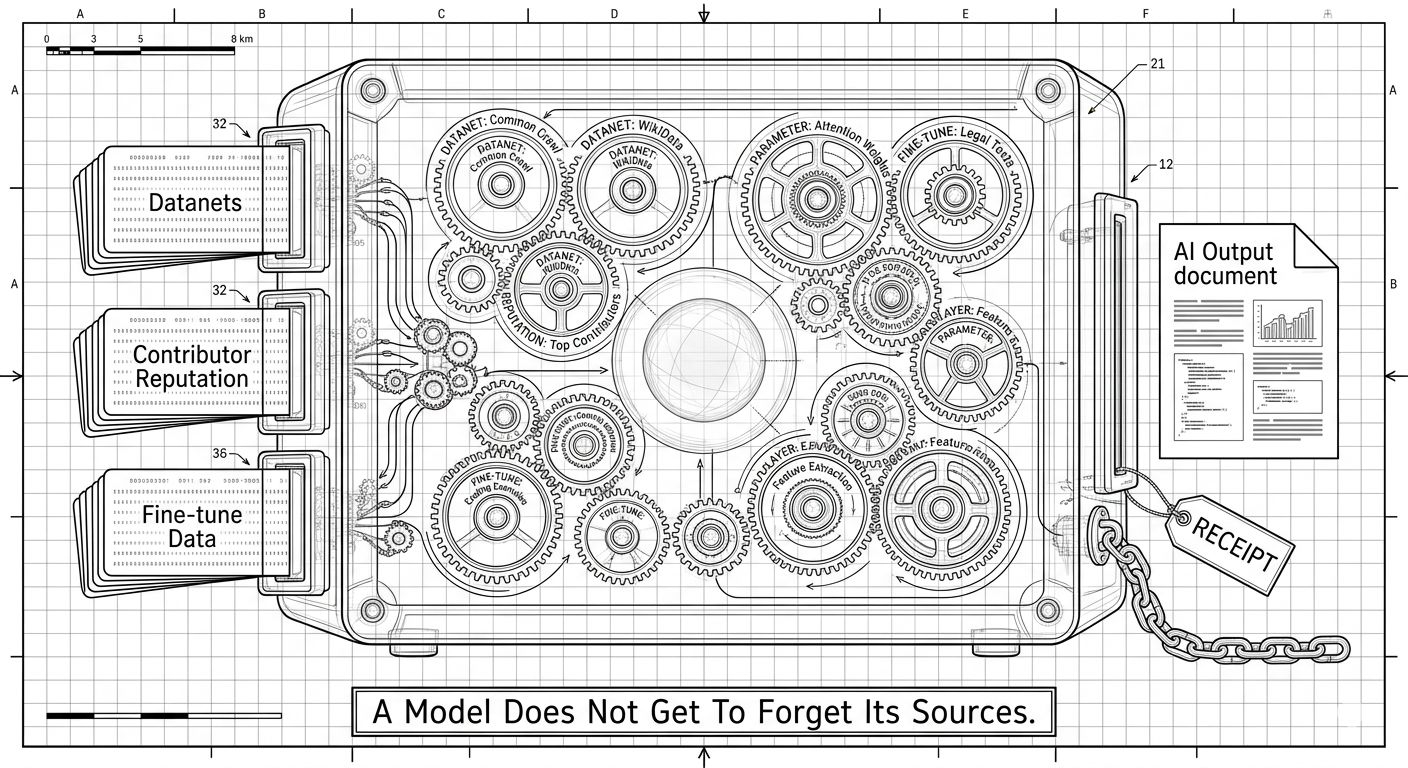
Ogni decisione silenziosa durante la costruzione viene registrata prima di scomparire nei pesi. Quali Datanet sono stati approvati e attivati. Quale reputazione e storia di validazione ha plasmato il dataset. Quali segnali sono stati enfatizzati durante il fine-tuning. Quali adattatori OpenLoRA hanno reso il modello modulare, economico o temporaneo. Quelle scelte non svaniscono. Risuonano in avanti attraverso l'inferenza, attraverso l'esecuzione dell'agente, attraverso la distribuzione delle ricompense, attraverso gli audit di conformità.
Questa è la linea di demarcazione tra un modello e un modello con provenienza. Uno può rispondere a un prompt. L'altro può essere interrogato, tracciato e regolato quando inizia a creare impatti economici.
Creazione più facile significa dimenticanza più difficile :
C'è un paradosso che attraversa l'IA in questo momento. Man mano che la creazione di modelli diventa più facile, la responsabilità diventa più urgente, non meno. Se costruire rimane difficile, solo pochi team centralizzati lanciano modelli e la scatola nera rimane piccola. Se ModelFactory rende la costruzione facile, otteniamo un'esplosione di modelli di nicchia, modelli specifici per agenti, casi d'uso verticali. Questa è l'onda di innovazione di cui lo spazio ha bisogno. Ma senza attribuzione, è caos con un'interfaccia più pulita.
La comodità di solito cancella la storia. La creazione diventa più facile e anche la dimenticanza. I dataset si mescolano. I crediti svaniscono. Le uscite sembrano auto-generate. OpenLedger spinge il principio opposto nel sistema: creazione più facile, dimenticanza più difficile. Quando un modello è legato ai Datanet e alla Proof of Attribution fin dall'inizio, non può sfuggire completamente alla sua catena di approvvigionamento. Può diventare utile, redditizio, ampiamente distribuito, ma porta comunque la ricevuta di ciò che lo ha aiutato ad arrivarci.
Ecco perché OpenLedger è importante in questo movimento non come un ticker o decorazione, ma come linguaggio di regolamento. Se un modello guadagna attraverso l'uso, il percorso della ricompensa deve sapere cosa sta premiando. I contributori di dati, i costruttori di modelli, i partecipanti al calcolo e gli esecutori di agenti devono essere tutti visibili nel flusso. Altrimenti, la monetizzazione diventa un'altra parola per estrazione.
Fidati della Traccia, Non della Dichiarazione
La maggior parte delle persone vuole che l'IA sembri istantanea. Prompt dentro, risposta fuori. Nessuna discendenza, nessun bagaglio, nessuna ricevuta. L'architettura di OpenLedger si oppone a quella fluidità di proposito. L'interfaccia del costruttore può essere pulita. Il sistema sottostante non dovrebbe esserlo. Se i dati di qualcuno hanno plasmato il comportamento, se un Datanet ha addestrato l'istinto, se il lavoro di un contributore ha migliorato l'esito, il sistema ha bisogno di abbastanza memoria affinché questo abbia importanza in seguito.
Un modello non sembra pericoloso mentre viene costruito. Sembra un flusso di lavoro. Alcuni config, alcuni dataset, un costruttore che clicca attraverso i passi. Il rischio si presenta più tardi, quando quel modello si trova all'interno di un agente, o di un flusso di trading, o di un'API di query da cui dipende un capitale reale. A quel punto le scelte della ModelFactory diventano portanti. Quale Datanet è stato fidato. Quale contributore ha superato la validazione. Quali dati sono sopravvissuti al fine-tuning. Quale pezzo verrà riconosciuto dalla Proof of Attribution quando le ricompense vengono distribuite.
Non è un dettaglio di backend. È l'argomento del futuro. Ogni modello è una disputa futura sull'influenza.

Le azioni hanno bisogno di ricevute, non solo di risposte
Una cattiva risposta da un modello è una cosa. Una cattiva azione da un modello con influenze nascoste è tutta un'altra storia. Se un agente instrada capitale, attiva un'operazione o esegue on-chain, il modello sottostante non può essere trattato come un cervello vuoto. L'azione deve avere anche una traccia.
Una ricevuta di esecuzione dell'agente senza la provenienza del modello sottostante è solo metà di una ricevuta. OpenLedger ModelFactory è il punto di partenza silenzioso per quel problema più forte. Non è la parte più appariscente dello stack. Ma decide che tipo di discendenza avrà il modello prima che il modello inizi a comportarsi come se fosse venuto dal nulla.
Ogni modello utile deve una spiegazione agli input che lo hanno reso utile. OpenLedger sta cercando di rendere quella spiegazione economica, tracciabile e più difficile da falsificare.
La Memoria Verificabile Batte l'Intelligenza Grezza :
La verità scomoda è che OpenLedger non chiede solo se l'IA può essere costruita più velocemente. Chiede se la cosa costruita può ancora essere tracciata dopo aver iniziato a guadagnare. Alcuni modelli porteranno tracce pulite. Alcuni porteranno tracce disordinate. Alcuni appariranno intelligenti fino a quando la Proof of Attribution non mostrerà cosa si è realmente mosso al loro interno.
Quella distinzione è il punto. Se l'IA deve diventare un'economia, i modelli non possono comportarsi come orfani.
Con OpenLedger, ogni azione dell'agente ha una ricevuta. Ogni ricevuta ha una fonte. Ogni fonte ha un Datanet.
La memoria verificabile batte l'intelligenza grezza. Perché quando gli agenti iniziano ad agire, tu ti fidi della traccia, non della dichiarazione.