here’s a problem that PoA doesn’t actually solve.
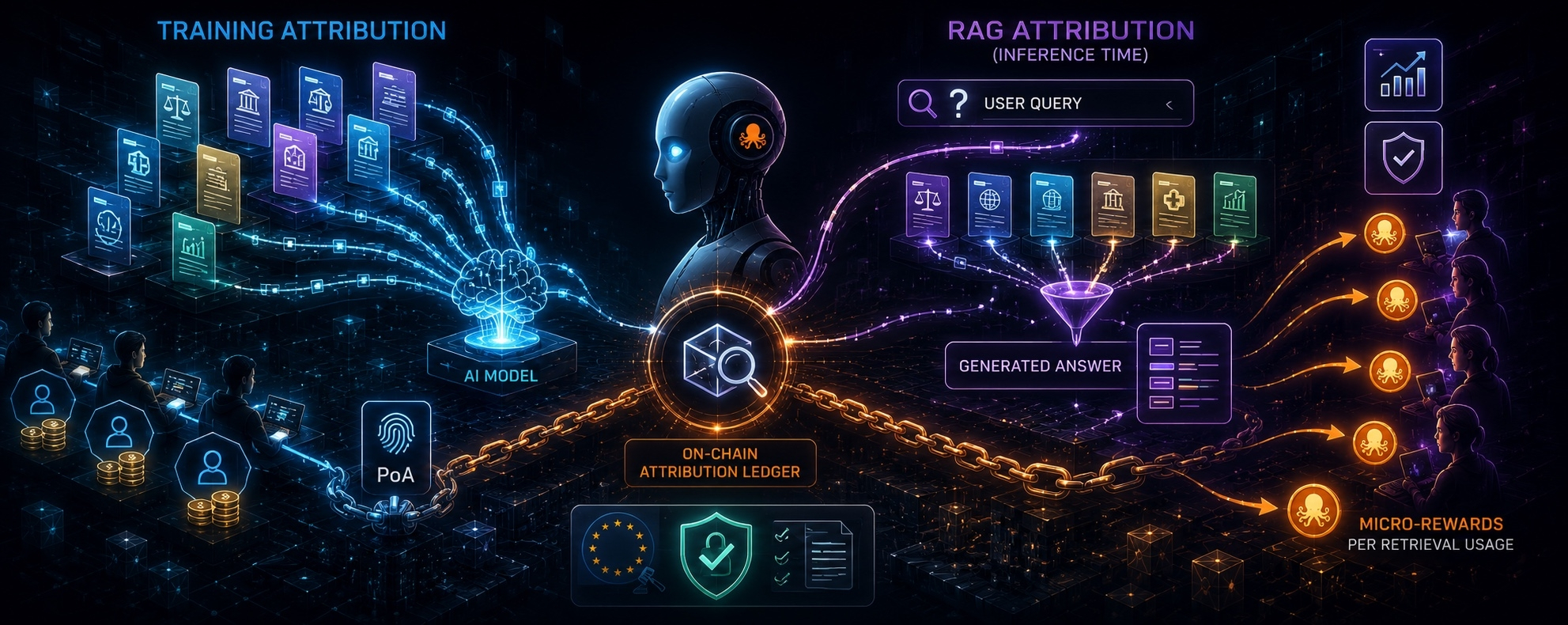
when a model answers a question using RAG, it doesn’t just draw from what it learned during training. it reaches out in real time, pulls relevant documents from external sources, and weaves those retrieved pieces into its response. training weights plus live retrieval — simultaneously. two separate sources, one answer.
traditional AI has no way to tell you which external source contributed what. the retrieval happens, the generation happens, the provenance disappears. you get an answer. you don’t get a receipt.
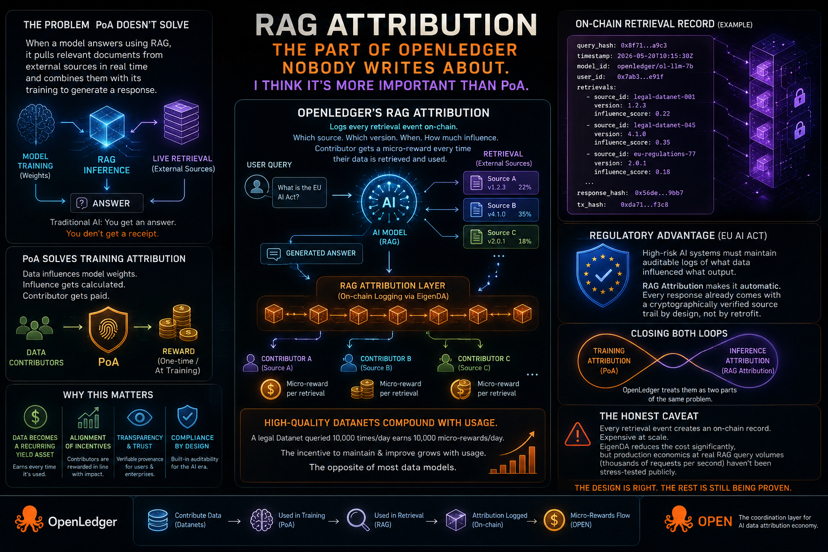
I kept thinking about this after reading through OpenLedger’s docs. PoA handles training attribution well — data influences model weights, influence gets calculated, contributor gets paid. clean. but what about the data that gets retrieved at inference time, every single time the model runs? that data is also shaping outputs. those contributors are also doing the work. and without RAG Attribution, they get nothing.
OpenLedger’s RAG Attribution logs every retrieval event on-chain. which source, which version, which timestamp, how much it influenced the final output. contributor gets a micro-reward each time their data gets retrieved and used. not once at upload. every query.
the compounding math is interesting. a high-quality legal Datanet that gets queried ten thousand times a day earns rewards ten thousand times a day. the incentive to maintain and improve that Datanet grows with usage. which is the opposite of how most data contribution models work — where you contribute once and your involvement ends.
the regulatory angle is the part I find most underrated. the EU AI Act requires high-risk AI systems to maintain auditable logs of what data influenced what output. most companies are treating this as a compliance problem to retrofit later. RAG Attribution makes it automatic — every response already comes with a cryptographically verified source trail, as a byproduct of the system running normally. that’s not a feature you add on. that’s infrastructure you build in from the start.
I haven’t seen another project close both loops — training attribution and inference attribution — in a single protocol. most solve one. OpenLedger’s architecture treats them as two parts of the same problem.
the honest caveat: every retrieval event creating an on-chain record is expensive at scale. EigenDA reduces that cost significantly, but production economics at real RAG query volumes — thousands of requests per second in serious deployments — haven’t been stress-tested publicly. that’s the gap between the design being right and the system being production-ready.
the design is right. the rest is still being proven.