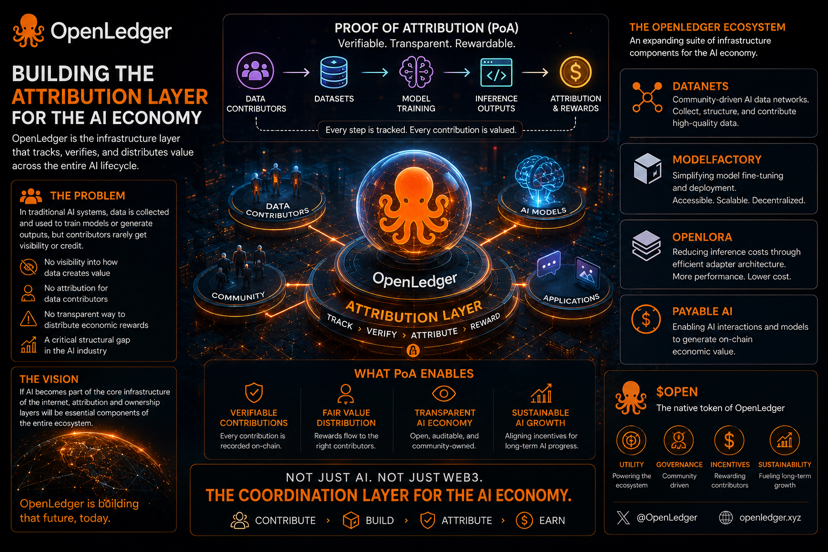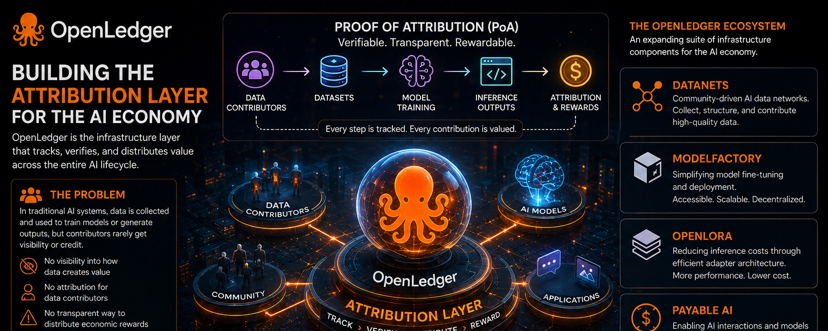
After following recent updates from OpenLedger, I’ve started to see the project as more than just another AI narrative in Web3. What makes it interesting is the way it focuses on one of the biggest unresolved problems in AI today: how data value is tracked, verified, and distributed.
In traditional AI systems, data is collected and used to train models or generate inference outputs, but contributors rarely have visibility into how their data creates value. There is almost no transparent attribution mechanism that connects data contribution to economic rewards. As AI continues to scale, this could become one of the most important structural issues in the industry.
OpenLedger is approaching this challenge through Proof of Attribution (PoA). Instead of treating data as an invisible resource, the project aims to build an infrastructure layer capable of tracking contribution across the entire AI lifecycle — from datasets and model training to inference outputs. Once attribution becomes verifiable, value distribution can become more transparent through the Open ecosystem.
Another thing that stands out is how the ecosystem is gradually expanding into multiple infrastructure components:
• Datanets → community-driven AI data networks
• ModelFactory → simplifying model fine-tuning and deployment
• OpenLoRA → reducing inference costs through efficient adapter architecture
• Payable AI → enabling AI interactions and models to generate on-chain economic value
What I find most interesting is that OpenLedger is not only building AI applications, but attempting to create a coordination layer for the AI economy itself — where contributors, models, and data can interact in a decentralized and transparent environment.
If AI eventually becomes part of the core infrastructure of the internet, then attribution and ownership layers may become essential components of the entire ecosystem.