Ho iniziato a notare OpenLoRA da una domanda molto noiosa.
Non è 'fino a che punto l'agente AI sarà intelligente?'
Non è 'come OpenLedger sbloccherà l'economia dei dati?'
Ma è: se in futuro ci saranno migliaia di modelli specializzati, chi li utilizzerà davvero abbastanza per farli sopravvivere?
Suona un po' demotivante. Ma il crypto mi ha insegnato una lezione piuttosto dura: creare offerta è sempre più facile che creare domanda. Creare token è più semplice che creare utilità. Creare asset è più facile che creare motivi per cui gli altri tornino ad usarli ogni giorno. GameFi ha avuto troppe cose senza veri giocatori. DeFi ha avuto troppe vault che sopravvivevano solo grazie alle emissions. L'AI crypto potrebbe ripetere quell'errore, solo che questa volta ciò che è in magazzino non sono NFT o vault, ma modelli piccoli chiamati 'specializzati'.
All'inizio quasi credevo a quella narrativa troppo in fretta.
L'AI specializzata sembra molto sensata. Un modello per l'audit dei contratti intelligenti. Un modello per la ricerca di trading. Un modello per il flusso di lavoro legale. Un modello per ogni comunità con dati propri. OpenLedger ha Datanets per raccogliere dati specializzati, ModelFactory per il fine-tuning, Proof of Attribution per registrare il contributo. Sulla carta, tutto si connette piuttosto bene.
Ma la bellezza sulla carta spesso tralascia una questione molto reale: quel modello viene chiamato abbastanza?
OpenLoRA mi ha fatto fermare esattamente su questo punto.
LoRA può essere vista semplicemente come uno strato di adattamento leggero applicato al modello originale, invece di dover riaddestrare un intero modello grande da zero. OpenLoRA nel whitepaper è descritto come un sistema multi-tenant per servire modelli LoRA fine-tuned con un overhead minimo. Questo punto dati può sembrare secco, ma è importante perché OpenLedger non ha solo bisogno di creare modelli. Ha bisogno di far sì che molti modelli piccoli possano essere eseguiti a costi sufficientemente bassi.
In passato vedevo questo dettaglio come un'ottimizzazione dell'infrastruttura. Ora lo vedo più come una prova.
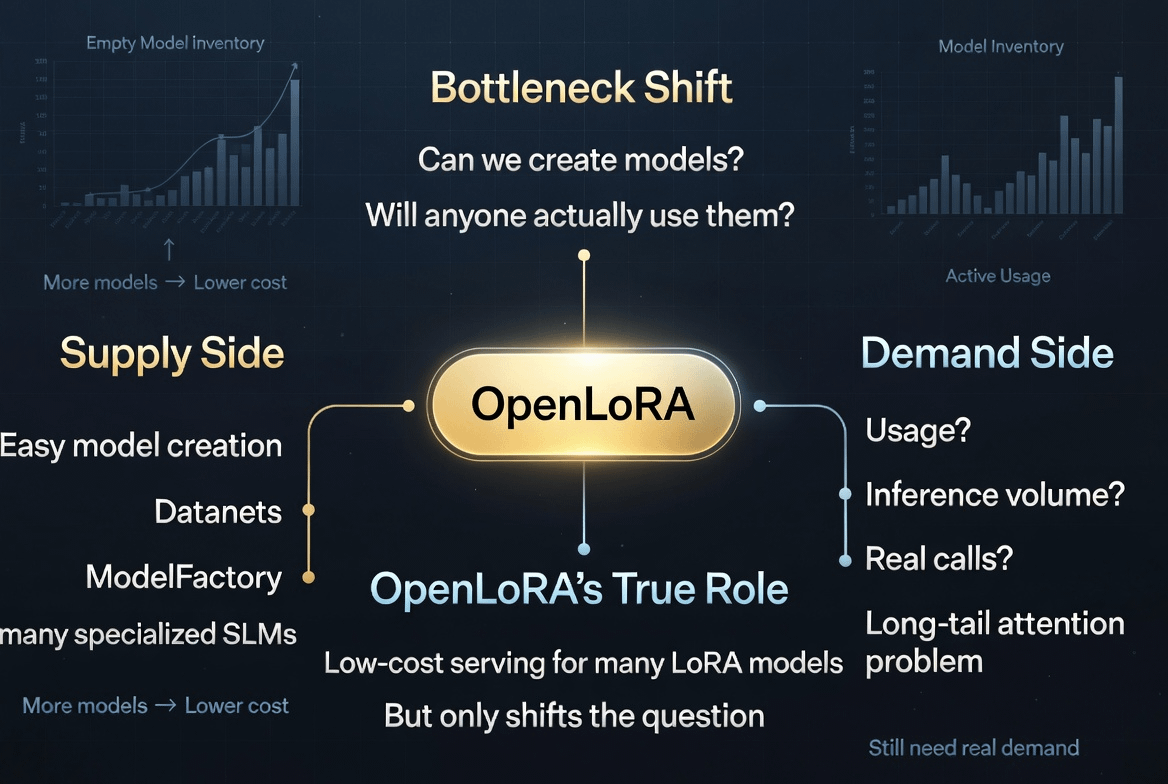
Quando i costi di erogazione sono ancora troppo alti, abbiamo sempre una scusa: l'AI specializzata non è emersa perché l'infrastruttura è costosa, perché il deploy è difficile, perché i modelli piccoli non possono sostenere i costi. Ma se OpenLoRA riduce quell'attrito, la vera domanda inizia a emergere: c'è davvero domanda per l'AI a coda lunga, o c'è solo offerta a coda lunga?
Questo è il punto in cui trovo OpenLoRA più interessante della sua parte tecnica.
Non dimostra che OpenLedger avrà un'economia AI sostenibile. Sposta solo il collo di bottiglia in un posto più difficile da nascondere. Da "possiamo eseguire molti modelli piccoli?" a "quali modelli piccoli hanno un vero utilizzo?" Da "i costi di erogazione sono troppo alti?" a "il volume di inferenza è sufficientemente denso per ricompense significative?" Da "chi crea modelli?" a "chi torna a chiamare quel modello la seconda, la decima, la millesima volta?"
Perché in OpenLedger, un modello specializzato ha realmente vita economica solo se viene utilizzato. L'inferenza non è solo la risposta dell'AI. È il punto in cui si paga, l'attribuzione ha dati da misurare, e la ricompensa ha l'opportunità di tornare al contributor. Se l'uso è scarso, la Proof of Attribution può essere logicamente corretta, ma la ricompensa per chi ha fornito i dati può essere troppo piccola per cambiare il comportamento. L'equità sulla carta non si trasforma automaticamente in incentivi nella vita reale.
Questo è il punto che penso molti trascureranno.
La gente ama parlare di "sbloccare la liquidità per i dati e i modelli". Ma la liquidità non appare solo perché un asset è definito. Appare quando ci sono persone pronte a usarlo, a pagare, a tornare. Senza di ciò, l'ecosistema può avere molti adattatori, molti modelli e dashboard belle, ma sembrano un mercato aperto tutta la notte senza abbastanza compratori.
Non dico questo per sminuire OpenLoRA. Al contrario, è proprio per questo che lo trovo degno di osservazione. Una buona infrastruttura non risolve solo problemi passati. Rivela il problema successivo. Se OpenLoRA rende i modelli piccoli più economici da eseguire, allora OpenLedger non sarà più testato dal numero di modelli creati. Sarà testato dalla qualità della domanda dietro quei modelli.
Gli sviluppatori li integrano davvero nel loro flusso di lavoro?
Gli agenti li chiamano perché sono più utili delle opzioni generiche?
I contributor vedono le ricompense abbastanza reali da continuare a fornire buoni dati a Datanets?
O tutto ciò crea solo un nuovo strato di inventario per il mercato della valutazione prima che l'utilità possa apparire?
Questo è il punto in cui vedo OpenLoRA connessa a una domanda più grande dell'AI crypto. Forse il prossimo ciclo di questo settore non mancherà di intelligenza. Mancano meccanismi per sapere quale intelligenza merita di esistere. Quando la creazione e l'erogazione di modelli piccoli diventano più facili, la scarsità non è più nel numero di modelli. È nell'attenzione, distribuzione, fiducia e vero utilizzo.
Quindi OpenLoRA non è la "risposta definitiva" di @OpenLedger .
È come aprire un rubinetto in un sistema di tubazioni. Prima, la gente poteva discutere a lungo se l'acqua potesse scorrere perché il rubinetto era troppo stretto. Quando il rubinetto si apre, la nuova domanda diventa molto più chiara: c'è davvero acqua nei tubi e quella acqua arriva dove c'è bisogno?
Se ci riesce, OpenLoRA potrebbe essere uno dei dettagli silenziosi che aiutano l'AI specializzata a coda lunga a diventare un'economia reale.
Se no, l'intelligenza a coda lunga diventerà solo un magazzino infinito di modelli che nessuno chiama.
E penso che questa sia la vera prova da osservare in OpenLedger. Non quanti modelli possono essere creati che suonano bene sulla carta, ma quanti modelli possono essere chiamati abbastanza affinché i dati dietro di essi non siano solo registrati, ma portino realmente valore.