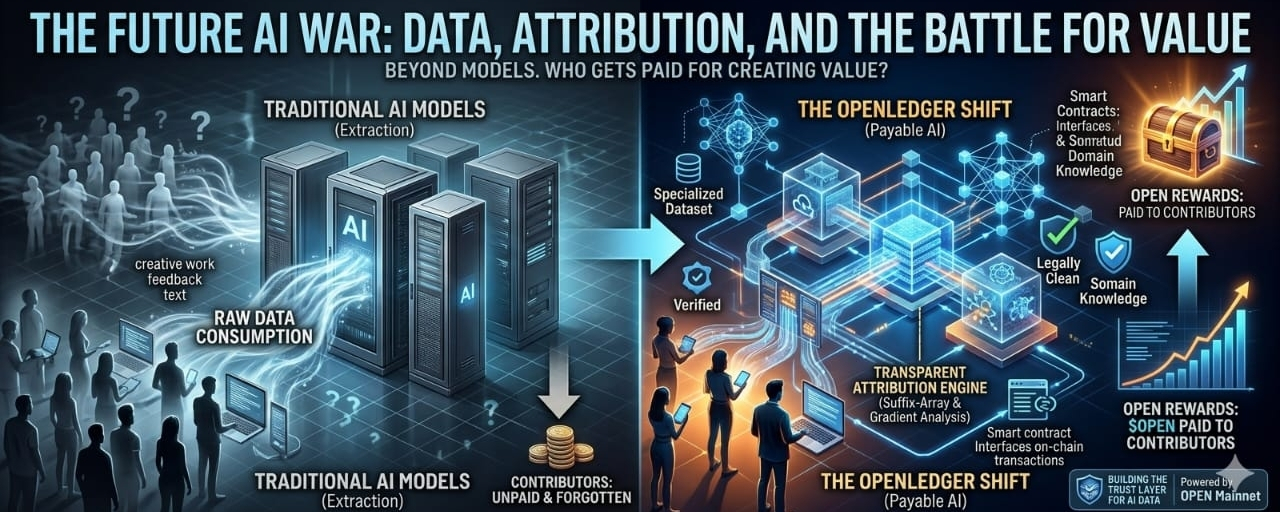
Sometimes I feel like most people are still looking at the AI race from the wrong angle. The conversation is always around models. Which model is faster, which model can reason better, which company has more capital, which team has the biggest infrastructure. And yes, all of that matters. But underneath all this noise, there is a much deeper question slowly becoming impossible to ignore. Who actually owns the data that makes these systems valuable? Who verifies it? Who gets credited for it? And maybe most importantly, who gets paid when that data becomes part of something commercially useful?
This is where the idea of data ownership starts feeling much bigger than a normal crypto narrative. AI has always depended on human input. Text, datasets, corrections, feedback, domain knowledge, research, user behavior, creative work, and countless small contributions that help models become better over time. But once the model becomes powerful, most contributors simply disappear from the economic layer. The system keeps the knowledge, but the people behind that knowledge are almost forgotten. That imbalance has existed for years, and honestly, it is one of the most uncomfortable truths about AI infrastructure.
That is why @OpenLedgerDatanet has been catching my attention more seriously. Not because it is another AI + crypto project using strong words, but because it seems to be approaching the problem from a structural level. The idea behind “Payable AI” is interesting because it tries to change data from something that is silently consumed into something that can be traced, valued, and rewarded. Since OPEN Mainnet went live, this no longer feels like only a roadmap idea or a theoretical concept. Contributors can submit datasets, developers can use those datasets to build domain-specific models, and smart contracts can distribute $OPEN rewards on-chain based on contribution value. That changes the entire psychology of participation. Data stops being just fuel for AI. It starts becoming visible labor.
The attribution side is probably the part I find most important. OpenLedger’s upgraded Proof of Attribution engine seems to be trying to solve one of the hardest problems in AI: how do you know which data actually helped a model perform better? The small-model gradient attribution approach makes sense in a practical way. If removing a specific datapoint weakens model performance, then that datapoint clearly had some measurable value. But the more ambitious part is the Suffix-Array-Based Token Attribution system for large language models. LLM outputs are not simple. They are blended, collective, and deeply difficult to trace. So even attempting to connect generated outputs back to source-level training influence is a very serious infrastructure challenge.
I do not think attribution will ever become mathematically perfect. AI systems are too complex, and influence inside a model is not always clean or linear. But the fact that OpenLedger is trying to build a transparent attribution layer already feels like a meaningful shift. Most platforms in the AI world have historically optimized for extraction first. Collect the data, train the model, capture the value, and leave contributors outside the reward loop. OpenLedger seems to be moving in a different direction, or at least trying to. It is not only asking how AI can become more powerful. It is asking how value inside AI systems can be remembered, measured, and shared.
Another thing I keep thinking about is the legal and sourcing side of this whole architecture. In the future, legally clean data may become just as important as raw data. Maybe even more important. Enterprises will not only ask whether a model is smart. They will ask whether the data behind that model is verified, licensed, attributable, and defensible. This matters even more in sensitive areas like medical AI, financial AI, legal AI, and enterprise-grade decision systems. A model trained on questionable or unverified data may become a liability, no matter how impressive its output looks. That is why OpenLedger’s focus on data sourcing, attribution, and partnerships such as Story Protocol feels strategically important.
The domain-specific Datanet approach also feels more grounded than trying to become “AI infrastructure for everything.” A lot of AI crypto projects are trying to sound broad because broad narratives attract attention. But broad does not always mean useful. In my view, the more valuable direction may be specialized, verified, contributor-driven datasets that can serve real model-building use cases. If OpenLedger can make that work, then the value is not only in the token or the narrative. The value is in becoming part of the trust layer for AI data.
Of course, none of this means the road will be easy. The moment real rewards enter the system, gaming behavior will follow. People will try to manipulate leaderboards. Low-quality synthetic data will appear. Spam contributions will increase. Attribution disputes will happen. Some users will optimize for rewards instead of real usefulness. These are not small problems. In fact, they may become the real test of OpenLedger after mainnet. The question is whether the validation process can stay strong at scale. Whether attribution can remain trusted across millions of contributions. Whether incentives can stay aligned over the long term. Whether the system can reward genuine value without being captured by noise.
And honestly, I do not know the final answer yet. Nobody does. But that uncertainty is exactly what makes this phase interesting. For once, an AI crypto project is not only talking about faster models, bigger narratives, or vague future promises. It is touching a much harder question that the entire AI industry will eventually have to face: if people help create AI value, will the system remember them?
That question may become one of the biggest questions in the next phase of AI. Because the future AI war may not only be about who has the best model. It may be about who controls the data, who can prove its origin, who can defend its legitimacy, and who can build an economy around fair attribution. OpenLedger may not have every answer yet, and the architecture still has to prove itself under real pressure. But at least it is building toward a problem that actually matters. And in a market full of surface-level AI narratives, that alone makes it worth watching closely.