Sometimes I genuinely feel like most people still don’t fully understand how important “data ownership” is going to become in the future of AI.
Because the entire conversation is still trapped inside a model-centric mindset.
Which model is faster.
Which one reasons better.
Which company raised more funding.
Which AI giant will dominate the next cycle.
Most people are focused on the surface layer.
But underneath all of that, something much deeper is quietly forming…
and I think that thing is attribution.
Who is actually creating the value inside these AI systems?
I have a feeling this question is going to become very uncomfortable for the industry sooner or later.
And honestly, the more I observe @OpenLedger Datanet, the more it feels like they’re not simply building another “AI + crypto” narrative.
They seem to be trying to redefine the relationship between contributors and AI infrastructure itself.
It sounds massive.
Maybe even overly ambitious.
And truthfully, it may still take years before we fully understand whether this architecture can actually work at global scale.
But even so… there’s something structurally different happening here.
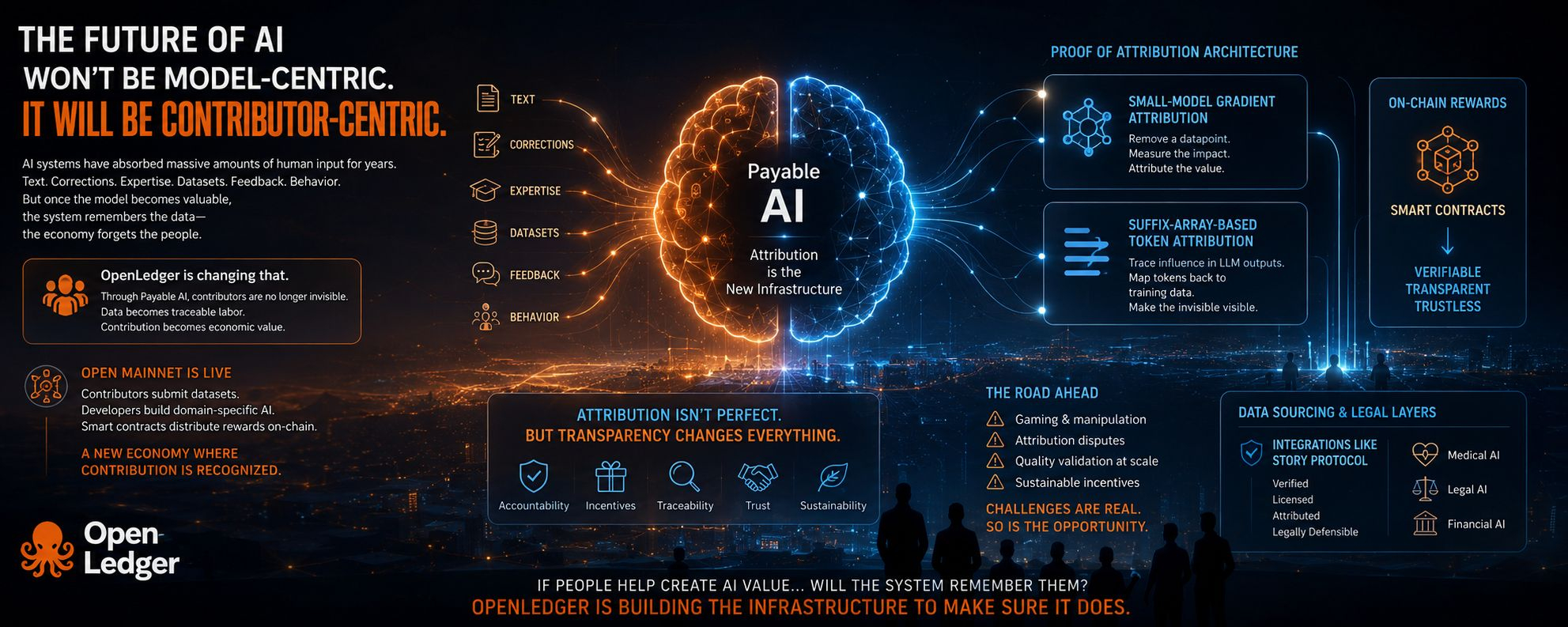
Because historically, AI systems have absorbed enormous amounts of human input.
Text.
Corrections.
Domain expertise.
Datasets.
Feedback loops.
Behavior patterns.
But once the model becomes commercially valuable, contributors almost disappear from the equation.
The system remembers the data.
The economy forgets the people.
That imbalance has quietly existed for years.
And honestly, this is where OpenLedger’s “Payable AI” concept starts to become interesting to me.
Not as a marketing slogan.
Crypto creates new buzzwords almost every week.
But since OPEN Mainnet went live, the conversation feels like it shifted from theory into actual economic execution.
Now the Datanet contribution layer is no longer just a roadmap concept.
Contributors can submit datasets.
Developers can train domain-specific AI models using those datasets.
And smart contracts distribute rewards directly on-chain.
That changes the psychology of participation itself.
Suddenly, data is no longer just passive fuel.
It becomes traceable labor.
And I honestly think people are underestimating how important that distinction could become.
Especially after looking deeper into the upgraded Proof of Attribution architecture.
The small-model gradient attribution layer at least makes conceptual sense.
If removing a specific datapoint measurably worsens model performance, then obviously that datapoint contributed real value.
But the more fascinating part is probably the Suffix-Array-Based Token Attribution system for LLMs.
Because contribution tracing in large language models has historically been incredibly opaque.
Outputs are collective.
Blurred.
Almost anonymous.
Nobody really knows where influence begins or ends.
So trying to map generated tokens back to training-data influence is actually a massive infrastructure challenge.
Maybe even an impossible one to perfect completely.
And honestly, I don’t think attribution will ever become mathematically pure.
But even attempting to create a transparent attribution layer feels fundamentally different from the direction most of the industry has been moving toward.
Because most platforms optimized extraction first.
OpenLedger at least appears to be trying to optimize accountability.
Or at minimum, moving in that direction.
And there’s another thing I keep thinking about…
In the future, data sourcing and legal protection layers may become one of the most important parts of the entire AI economy.
Especially integrations like Story Protocol.
Because as AI systems move deeper into commercial ecosystems, legally clean datasets may become even more valuable than raw datasets themselves.
Right now everyone talks about model intelligence.
But over the next few years, enterprises may start asking equally important questions:
Can this dataset be verified?
Licensed?
Attributed?
Legally defensible?
And honestly… those questions could completely reshape the medical, legal, and financial AI sectors.
Looking at OpenLedger’s roadmap, at least they seem aware of where this direction may lead.
Their domain-specific Datanet approach also feels intentional.
Instead of trying to become infrastructure for everything, they appear to be focusing on specific data economies first.
Personally, that feels far more realistic.
Especially in a market where countless projects are still trying to sell the narrative of being “AI infrastructure for everything.”
But at the same time… the challenges ahead are enormous.
Because wherever economic incentives exist, gaming behavior follows.
Leaderboard farming.
Synthetic low-quality data.
Spam optimization.
Attribution disputes.
Reward manipulation.
Those pressures are unavoidable.
Which is why I think the real test probably begins now — after mainnet.
Will validation remain reliable at scale?
Will attribution still be trusted across millions of interactions?
Will contributor incentives remain sustainable long term?
Honestly…
I don’t know.
But maybe that uncertainty is exactly what makes this phase important.
Because after a long time, an AI crypto project is finally emerging that isn’t only talking about better models or speculative hype.
It’s asking a far more uncomfortable question:
“If people help create AI value… will the system remember them?”
And I honestly think the entire industry will eventually have to confront that question.
Maybe OpenLedger doesn’t have all the answers yet.
But it does seem like one of the very few projects actually trying to build infrastructure around the problem instead of pretending it doesn’t exist.
Anyway… let’s see where this goes