OpenLedger non è interessante perché dice “AI” accanto a “crypto.” Ho visto quel trucco troppe volte. Il mercato sta riciclando la stessa proposta da anni: prendi un settore caldo, attacca un token, aggiungi qualche diagramma pulito e aspetta che l'attenzione torni.
La maggior parte muore in silenzio.
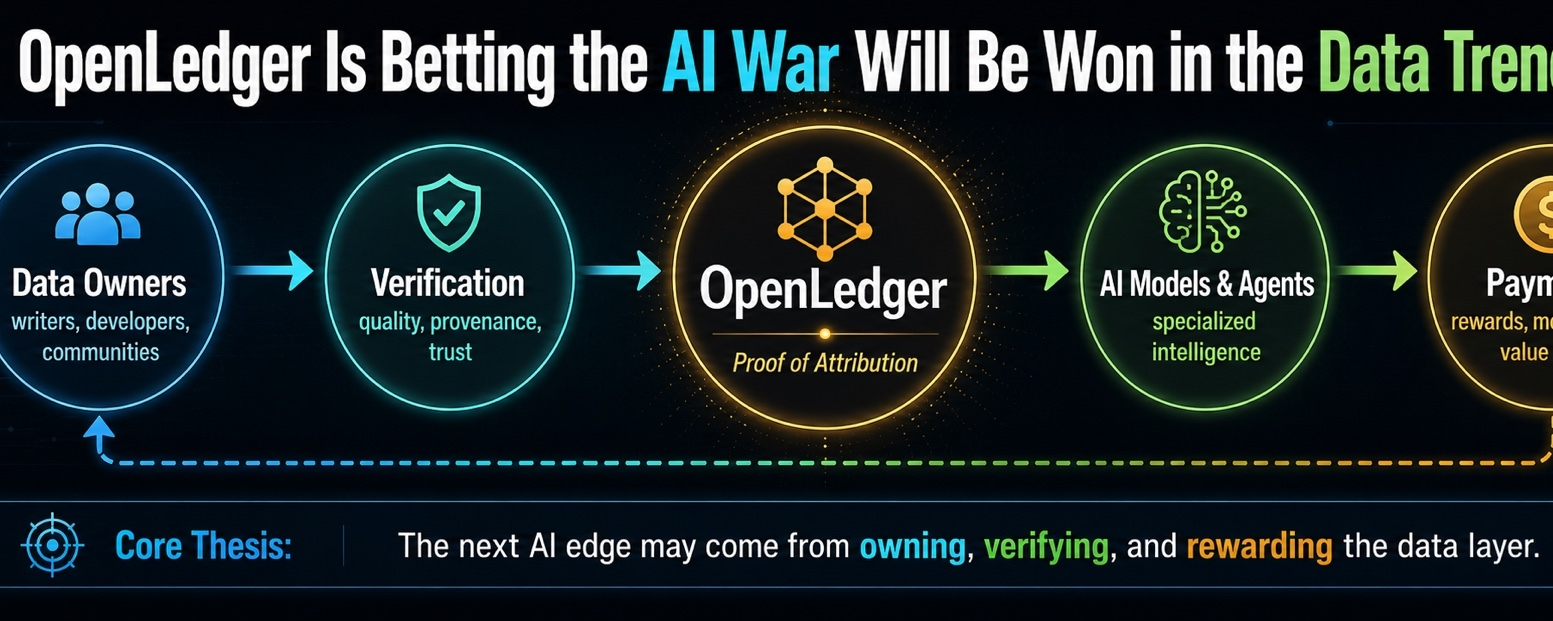
OpenLedger merita attenzione per un motivo diverso. Sta affrontando uno dei problemi più brutti dietro l'AI: i dati. Chi li possiede. Chi li verifica. Chi viene pagato quando diventano utili. Non è la parte glamour. Non è roba da demo. È la parte tecnica.
E l'impiantistica è di solito dove si nascondono i soldi.
L'AI non diventa utile dal nulla. Si nutre del lavoro umano. Scrittura, codice, ricerca, comportamento di mercato, etichette, correzioni, conoscenze della comunità, note di esperti, schemi di trading, commit degli sviluppatori, argomenti nei forum, tutto. Il modello riceve gli applausi, ma l'intelligenza grezza di solito proviene da persone che svaniscono dalla linea di pagamento.
Questo mi ha sempre infastidito.
L'idea di OpenLedger è smettere di trattare quei collaboratori come carburante usa e getta. Se un dataset migliora un sistema AI, il contributo dovrebbe essere tracciabile. Se quel contributo crea valore, dovrebbe esserci un modo per far muovere i premi indietro. Frase semplice. Problema molto difficile.
Questa è la parte su cui le persone devono rallentare.
Tracciare i dati sembra facile quando è scritto in un whitepaper. Non lo è. I modelli AI non funzionano come un distributore automatico dove un input ti dà un output. Una risposta può essere plasmata dai dati di addestramento, affinamento, feedback, contesto utente, comportamento del modello, memoria dell'agente e una dozzina di strati nascosti nel mezzo. Quindi quando OpenLedger parla di attribuzione, non sto applaudendo ancora. Sto osservando.
Voglio vedere dove questo si rompe effettivamente.
Perché si romperà da qualche parte.
Forse i dati spam allagano il sistema. Forse dataset copiati fingono di essere originali. Forse i collaboratori coltivano premi con spazzatura di bassa qualità. Forse i dati utili rimangono privati perché il pagamento non vale il rischio. Forse gli sviluppatori amano l'idea ma non costruiscono mai nulla che conti. La crypto ha una lunga storia di design di incentivi belli che si trasformano in giochi di farming rumorosi non appena appare il denaro.
Questa è la fatica.
Tuttavia, la direzione ha senso.
Il mercato AI è stanco dell'intelligenza generica. Tutti vogliono modelli specializzati ora, anche se non lo dicono sempre chiaramente. Dati finanziari. Dati di sicurezza. Comportamento DeFi. Ragionamento legale. Flussi di lavoro medici. Schemi di gioco. Dati linguistici regionali. Conoscenze degli sviluppatori. Cose che sono specifiche, disordinate, difficili da raccogliere e realmente utili.
Quel tipo di dati non appare semplicemente perché qualcuno scava di più nel web aperto.
Ha proprietari. Ha contesto. Ha problemi di qualità. Ha bisogno di pulizia. Ha bisogno di prove. Ha bisogno di persone che sanno cosa stanno guardando.
Qui è dove OpenLedger potrebbe avere importanza. Non come un altro progetto front-end luccicante. Non come un cervello AI magico. Più come uno strato di coordinamento per persone e comunità che hanno dati preziosi ma nessun modo pulito per provarlo, valutarlo o continuare a guadagnare da esso una volta che lascia le loro mani.
Questa è la versione migliore della storia.
La versione più debole è facile da immaginare. Molto parlare di 'monetizzazione dei dati' nella crypto diventa vuoto molto in fretta. La gente carica spazzatura. I dashboard mostrano attività. I premi token creano rumore. Tutti lo chiamano traction finché gli incentivi non si prosciugano. Ho già visto quel film.
Quindi non mi interessano le affermazioni.
Sono interessato a sapere se OpenLedger può rendere il contributo utile più redditizio rispetto all'attività falsa.
Questa è la vera prova.
Se il sistema premia il volume, affonderà. Se premia la qualità ma non può provare la qualità, sarà sfruttato. Se costruisce attribuzione ma nessuno usa i modelli, tutto diventa uno strato contabile per un mercato che non è mai arrivato. Se i costruttori si presentano, i dataset migliorano, gli agenti usano input verificati e i contributori guadagnano effettivamente qualcosa di significativo, allora la conversazione cambia.
Non prima.
Il lato agente è dove questo diventa un po' più serio. L'AI che parla è una cosa. L'AI che agisce è un'altra. Una volta che gli agenti iniziano ad aiutare gli utenti a spostare asset, giudicare il rischio, instradare transazioni, gestire approvazioni o interagire con i protocolli, il vecchio modello 'fidati di me' non funziona.
Una cattiva risposta è fastidiosa.
Una cattiva transazione fa male.
Quindi input verificati, percorsi di audit e attribuzione non sono solo bei extra. Diventano parte dello strato di sicurezza. Gli utenti devono sapere su cosa un agente si è basato. I costruttori devono sapere quali fonti di dati sono pulite. Le reti hanno bisogno di un modo per separare il segnale dalla spazzatura prima che l'automazione inizi a muovere denaro.
È qui che OpenLedger ha una vera possibilità di essere utile.
Ma di nuovo, utile è la parola. Non rumoroso. Non alla moda. Utile.
Il mercato è esausto perché troppi progetti vendono il futuro senza sopravvivere al presente. Ogni ciclo ha un nuovo costume. DeFi. Gaming. Metaverso. AI. DePIN. Agenti. Stesso ritmo sotto: grande linguaggio, utilizzo scarso, memoria breve.
OpenLedger deve evitare di diventare un altro costume.
Ha bisogno di reti di dati reali. Costruttori reali. Attribuzione reale. Payout reali. Domanda reale da applicazioni che necessitano di input AI verificati perché l'alternativa è troppo rischiosa o troppo disordinata. Senza ciò, questo diventa un'altra narrazione commerciale con un vocabolario migliore.
Non lo dico come un insulto. Lo dico perché l'idea è effettivamente abbastanza forte da meritare pressione.
La versione migliore di OpenLedger non è 'AI on-chain' come slogan. È un mercato in cui i contributori di dati non sono più invisibili, dove le conoscenze specializzate possono essere valutate, dove modelli e agenti possono mostrare il loro lavoro e dove il valore non fluisce solo verso l'alto in sistemi chiusi.
Questo sarebbe importante.
Ma la strada è tortuosa. Gli incentivi attirano parassiti. La verifica è difficile. L'attribuzione è ancora più complicata. E la maggior parte degli utenti non si preoccupa dell'infrastruttura fino a quando qualcosa non si rompe.
Forse è allora che questo tipo di progetto diventa ovvio.
Non durante la fase di hype.
Dopo il rumore. Dopo i primi fallimenti. Dopo che le persone si rendono conto che lo stack AI ha bisogno di più di modelli più grandi e interfacce più pulite.
OpenLedger mira a quella parte dell'AI che nessuno voleva sistemare.
Ora voglio vedere se può gestire la sporcizia.