OpenLedger and the Strange Feeling That AI Might Finally Be Hitting the Same Wall.
I've been around crypto long enough to stop reacting every time a project claims it is “redefining” something.
Most of the time, those words are just recycled packaging around the same old incentives. New token, new branding, same underlying reality: a few insiders capture the value, the crowd provides liquidity, and eventually the narrative moves somewhere else.
That’s probably why I’ve become slower to get excited about anything tied to AI lately. The space already feels overcrowded with oversized promises. Every week there’s another protocol claiming it will decentralize intelligence, tokenize agents, reinvent compute, or replace the internet itself. After a while it all blends together into the same background noise.
But every now and then something catches my attention, not because I suddenly believe in it, but because it seems focused on a problem that actually exists.
OpenLedger is one of those projects for me.
I’m not saying it works. I’m not saying it wins. I’m not even saying the model is sustainable. I honestly don’t know yet.
But I keep noticing that the underlying question it is asking feels more real than most of the AI narratives floating around crypto right now.
The question is simple: if AI models are becoming some of the most valuable systems in the world, why does almost nobody know where the value actually comes from anymore?
That sounds obvious at first, but the deeper you think about it, the stranger the entire AI economy starts to look.
Most AI systems today are built on oceans of data gathered from people who usually never see compensation, ownership, or even acknowledgment. Writers, artists, researchers, forum users, developers, niche communities, random internet archives — all of it gets absorbed into models that eventually become products worth billions.
And somehow everyone just accepted that this is normal.
Maybe because the systems became too large to question. Maybe because the companies building them moved faster than regulation. Maybe because nobody could realistically track attribution once models reached a certain scale.
That last part matters.
For years, one of the biggest problems in AI has been attribution itself. Once a model trains on enough data, tracing influence becomes blurry. The entire thing turns into a black box. A useful black box sometimes, but still a black box.
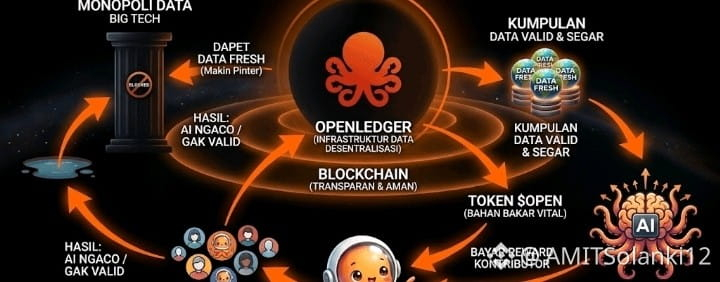
That’s the part OpenLedger keeps circling around with this idea of Proof of Attribution.
The concept sounds almost too ambitious when you first read it. The protocol tries to connect model outputs back to the data that influenced them, then reward contributors proportionally through the network.
I’ve seen crypto attempt similar things before in different forms. Music royalties. Creator economies. Storage incentives. Attention markets. Data marketplaces.
Most of them eventually ran into the same wall: measuring contribution in a meaningful way is brutally hard.#OpenAIToConfidentiallyFileForIPO $OPEN

#