AI is becoming easier to use, but harder to understand.
That sounds a little strange at first. The tools feel simple. You open a page, type a question, and something comes back. Sometimes it is useful. Sometimes it is wrong. Sometimes it sounds confident in a way that makes you pause for a second.
And after a while, you start asking a different question.
Not “can AI answer this?”
But “where did this answer come from?”
That question is starting to matter more.
We are moving into a world where AI will not only write text or generate images. It will make decisions, compare information, run tasks, speak to other systems, and act on behalf of people. Some of these actions will be small. Others may involve money, data, business processes, or personal decisions.
When that happens, trust becomes less about the final output and more about the path behind it.
What data shaped this model?
Which model powered this agent?
Who built the agent?
Was the data allowed to be used?
Did someone improve the system later?
Can any of this be checked?
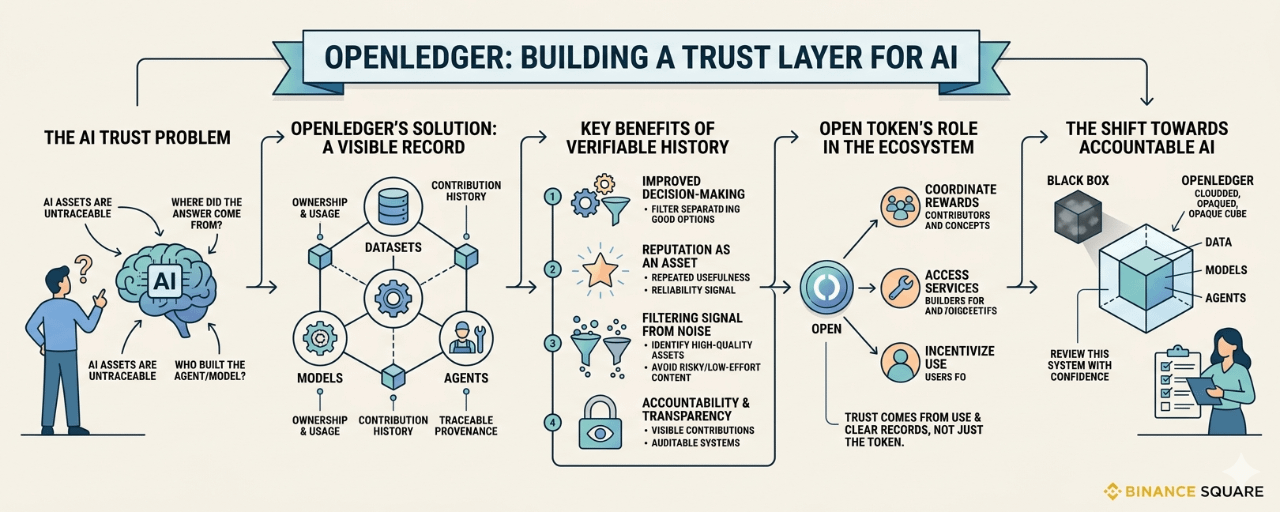
This is where @OpenLedger becomes interesting from a different angle. Not just as an AI blockchain, and not only as a way to monetize data, models, and agents. It can also be seen as an attempt to build a trust layer around AI activity.
That may sound less exciting than markets and tokens, but it may be more important.
Because AI has a traceability problem.
Most people only see the surface. They see the answer, the tool, the app, or the agent. But they do not see the chain of inputs underneath. They do not know which datasets were involved. They do not know whether a model was trained on clean, verified, useful information or a messy pile of low-quality content. They do not know whether the agent they are using has a reliable history.
And honestly, most users do not want to check all of that manually.
They just want some reason to trust the system.
#OpenLedger seems to approach this by giving AI assets a kind of record. Data, models, and agents can be connected to ownership, usage, and contribution history. That sounds simple, but it changes the feel of the system. An AI asset is no longer just something floating around without context. It has a source. It has activity. It has a trail.
You can usually tell when a digital system has no memory of how things were made. Everything becomes flat. A high-quality dataset and a poor one can look similar from the outside. A serious builder and a careless one can both publish something with the same kind of description. A useful agent and a risky one may sit side by side until something goes wrong.
A record does not solve everything. But it gives people something to look at.
That’s where things get interesting.
In the current internet, reputation often lives in scattered places. A developer may have a GitHub profile. A company may have a website. A dataset may have documentation. A model may have a page somewhere. An agent may have user reviews. But these pieces are not always connected. The story is broken across platforms.
OpenLedger’s idea feels closer to joining those pieces into one economic and technical history.
If a dataset is used often, that matters.
If a model performs well across different agents, that matters.
If an agent creates value repeatedly, that matters.
If contributors keep improving the system, that matters too.
Over time, these signals can become more than background information. They can become part of how people decide what to use.
The angle here is not only ownership. It is reputation.
In AI, reputation may become a serious asset. Not the loud kind of reputation that comes from social media attention. A quieter kind. The kind that comes from repeated usefulness. The kind that says, this data has been used before, this model has a history, this agent has done the job, this contributor has added something real.
That could matter a lot in a world filled with AI tools that all claim to be intelligent.
Because the more AI grows, the harder it becomes to separate signal from noise.
There will be many models. Many agents. Many datasets. Many claims. Some will be strong. Some will be copied. Some will be low effort. Some may be unsafe. Users and builders will need ways to filter through all of it without relying only on branding or hype.
OpenLedger could become useful if it helps create that filter.
Not by telling people what to trust, but by showing more of the history behind what they are using.
That is a softer but important role. A system does not always need to control the whole market to matter. Sometimes it matters by making the market easier to read.
$OPEN the token, fits into this only if the activity around it is real. That part is worth saying plainly. A token can help coordinate rewards, access, and incentives. But a token cannot create trust by itself. Trust comes from repeated use, clear records, and systems that behave in ways people can verify.
So the deeper question around OpenLedger may not be about price first.
It may be about whether AI contributors want a place where their work has a visible record. Whether builders want to use assets with clearer histories. Whether users eventually care about the source of the intelligence they rely on.
At the beginning, maybe only builders care. That is normal. Infrastructure usually starts out invisible. Most people do not think about payment rails, cloud systems, or databases when they use an app. They only notice when something breaks or when something becomes easier.
#OpenLedger sits in that kind of hidden space.
It is not trying to make AI feel more magical. If anything, it is trying to make AI feel more accountable. Less like a black box. More like a system with parts, owners, usage, and memory.
And maybe that is the quiet shift here.
As AI becomes more active in the world, people may stop asking only what it can do. They may start asking what it is built on, who stands behind it, and whether its history can be trusted.
That question will not disappear quickly. It will probably get louder over time.
@OpenLedger #OpenLedger $OPEN
Articolo
OpenLedger (OPEN): The Problem of Trust in an AI World
Disclaimer: Include opinioni di terze parti. Non è una consulenza finanziaria. Può includere contenuti sponsorizzati. Consulta i T&C.