I've spent the last few days going porperly deep into OpenLedger. Not the price chart. Not the listing news. The actual mechanism underneath everything. The Proof of Attribution paper, the Datanet architecture, how OPEN tokens actualy move every time a model gets called by a developer somewhere in the world. I had a notpad open the whole time, writing the flow out by hand, becuase i wanted to understand it with my own eyes before forming any real opinion on it.
And somewhere in that process i found something that genuinely unsettled me. Not because its bad. Becuase its important and nobody is talking about it clearly.
I'll be honest about where i started. When i first saw OpenLedger a few weeks ago i scrolled past it without blinking. AI blockchain. Data monetization. Decentralized attribution. I've read those exact words in so many project pitches over the last two years that my brain stoped processing them. They became noise. So i closed the tab and moved on like i always do with projects that lead with that combination.
What pulled me back was an argument in a Telegram group i'm in. Someone was defending OpenLedger and someone else was calling it narrative dressing on a token launch. Standard back and forth. But the person defending it droped one line that i couldn't let go of. They said most people who are excited about OpenLedger are excited about the wrong thing. That the payout mechanism isn't what the marketing makes it sound like.
That specific claim sent me back to the docs that same night.
The thing that caught me first, genuinly caught me, was how diffrent OpenLedger feels from most projects once you actually go inside it. Most AI crypto projects are really just dashboards with tokens attached. You poke around for twenty minutes and realize the AI part is a label and the blockchain part is just a wallet. OpenLedger isn't that. When you read the Proof of Attribution documentation properly you start to feel the weight of what they are actualy trying to do. They are trying to build a system where every single piece of human knowledge that trains an AI model gets tracked, attributed, and compensated automaticaly. Every dataset. Every contribution. Every inference that touches your data sends value back to you.
I sat with that for a while and felt something i dont feel often in this space. Something that felt close to hope. Because the problem they are solving is real in a way that actualy matters to me personaly. The people who create knowledge, who curate data, who spend years building domain expertise, they get nothing right now when that knowledge gets scraped and turned into billion dollar AI products. Thats broken. OpenLedger is one of the only projects i've seen that is attacking that problem with actual infrastructure rather then just a whitepaper promise.
But then i kept reading and something started to quietly bother me.
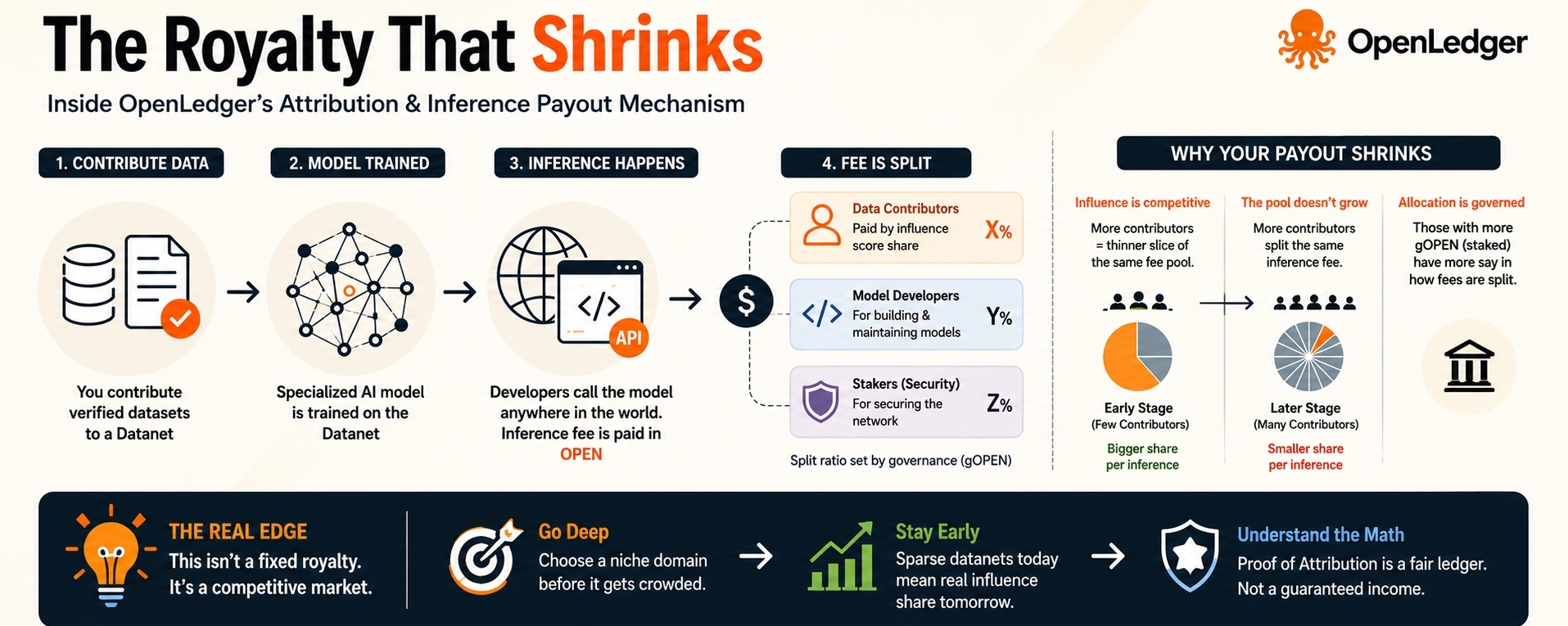
OpenLedger's pitch to data contributors is built around one word. Royalties. You contribute your dataset to a Datanet, a specialized AI model gets trained on it, and every time that model runs an inference anywhere in the world, every API call, every query, every output it generates, you automaticaly earn OPEN tokens. Passively. Ongoing. Like a musician earning every time their song streams on Spotify. Your data works for you while you sleep.
I understand exactly why they use that framing. Its warm. Its human. It speaks directly to the feeling of finaly being recognized for something you created. And unlike most crypto pitches there is real infrastructure underneath it. Proof of Attribution genuinly tracks which specific datasets shaped which model outputs at inference time, cryptographicaly, on chain. Mainnet went live November 2025. This is not vaporware. I respect the engineering deeply.
But here's what the royalty framing quietly leaves out.
When a musician earns royalties on Spotify the rate per stream is esentially fixed. It doesn't matter how many other artists join the platform. A million new musicians uploading songs tommorow doesn't reduce what you earn per play. Your song earns the same rate whether there are ten thousand artists in the world or ten million. That stability is the whole point of a royalty. Fixed rate per use. Predictable. Protected.
OpenLedger's inference payout does not work like that. Not even close.
When an inference call happens on OpenLedger, the OPEN fee from that call splits between data contributors, model developers, and stakers. But the split isn't fixed by the protocol. It gets determned by an influence score calculated after each inference. The system measures how much your specific dataset actualy shaped that specific output, then pays you proportional to your measured influence share.
The problem is that influence share is competative.
The more contributors uploading data in the same Datanet domain as you, the more ways that influence pool gets divided. The fee doesn't grow just becuase more contributors exist. It stays what it is and splits more ways. Your slice per inference call shrinks. Not because your data got worse. Not becuase the protocol failed you. Just because more people arrived in your domain and the math was never designed to protect you from that.
Let me make this feel real because i know mechanism talk is easy to mentaly skip over.
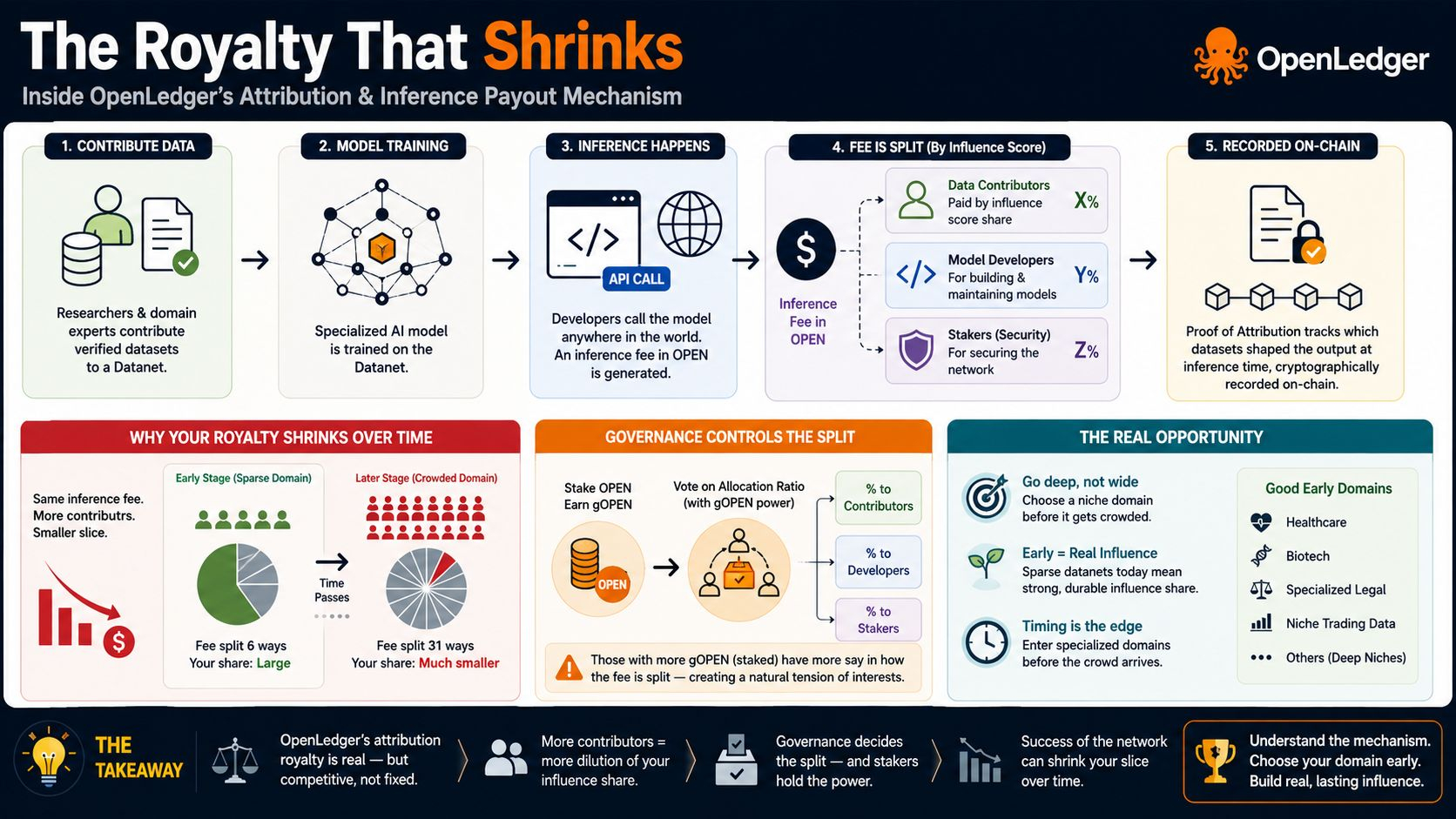
Imagine you are a researcher. You've spent years building deep expertise in healthcare data. You contribute a genuinly strong specialized dataset to a healthcare AI Datanet on OpenLedger today, in May 2026, when that domain has maybe five or six serious contributors in it. Your influence score is high. Your share of each inference payout is meaningfull. Every time a developer anywhere calls a healthcare model trained on your data, you earn a real slice of that fee. This feels exactly like the royalty promise. It works. You feel recognized for the first time in a long time.
Now twelve months pass. OpenLedger is growing, which is what you wanted. More developers are building healthcare AI models. The category is active and visible and generating real inference volume. So twenty five other contributors have uploaded healthcare datasets becuase they see the activity and want in. Your original dataset is still there. Still verified on chain. Still contributing to model outputs. Still doing the work. But that same inference fee that used to split six ways is now splitting thirty one ways. Your monthly earnings droped quietly and significantly and the protocol sent you nothing. No warning. No notifcation. Just a smaller number in your wallet every month and no clear explanation of why.
That moment, that quiet shrinking, is what the royalty framing never prepares you for.
And it isn't a bug. Its not something they forgot to fix. Its the natural consequence of building a competative influence pool inside a growing ecosystem. The same growth that proves the project is working is the exact force that compresses your individual share over time. The success of OpenLedger and the stability of your personal payout are quietly pulling against each other in a way the marketing never acknowleges.
There is one more layer that made me genuinly sit back in my chair when i thought it through fully.
The allocation ratio, the actual parameter that controlls how the inference fee divides between contributors, developers, and stakers, is not hardcoded into the protocol. It is set by governance. Governance on OpenLedger runs through gOPEN, which you earn by staking OPEN tokens. Larger staking positions mean more governance weight. Which means the group with the most say over how much of each inference fee actualy reaches data contributors is largely composed of people who benefit most from the staking side being generous to stakers.
Im not saying this is malicious. Governance structures like this exist accross most of crypto. But it creates a real tension that lives completely outside the royalty narrative. The researcher who contributed their years of domain expertise to a Datanet becuase they believed in fair compensation, and the large staker quietly voting on the allocation ratio that determines how much of each inference fee that researcher actualy receives, are not the same person with the same interests. That distance matters. It matters more as the protocol scales.
I want to say something clearly before i finish becuase i mean this genuinly.
OpenLedger is one of the most interesting infrastructure projects i've looked at this year. The problem they are solving is real and it matters. The engineering is serious. Proof of Attribution, EigenDA, OP Stack, Polychain Capital, Sreeram Kannan, Balaji Srinivasan. These are not names that show up on hollow projects. When you go deep enough into what they are building you start to feel the genuine ambition underneath it. A world where human knowledge is finaly legible and compensable inside an AI economy. Thats worth building. I believe in it.
But believing in the mission and understanding the incentive structure clearly are two diffrent things. And right now there is a gap between the warmth of the royalty framing and the competative reality of how influence scores actualy work at scale. That gap is going to matter more and more as the ecosystem grows.
Here is where i actualy land after all of this.
The real opportunity inside OpenLedger right now is not the royalty. Its the timing. We are early enough that most Datanets are genuinly sparse. Competiton per domain is thin. A contributor who goes deep into a specific niche today, before it becomes the obvious next category, faces almost zero influence dilution right now. Healthcare. Biotech. Specialized legal. Niche trading datasets. These are domains where serious inference volume will build over the next two to three years and many of them are still uncrowded enough that entering today gives you real durable influence share rather then a fraction of a pool that already has thirty people in it.
The contributor who truly understands this mechanism isn't asking whether OpenLedger pays royalties forever. They are asking which specific domain they can go deep in before everyone else realizes the same category is valueable. That is a sharper question. A harder question. But it is the right one.
Proof of Attribution is a fair ledger. It does not promise a fair market.
The royalty is real. It just gets smaller every time someone new walks through the door. The people who understand that are already choosing their domains carefuly and quietly while most people are still debating whether the royalty narrative is accurate. That gap in understanding is the actual edge right now.
I spent a few days and a full notpad getting here. But i think anyone who is seriously considering contributing to OpenLedger deserves to understand exactly what they are participating in. Not the version on the landing page. The real version underneath it.
That version is still worth it. Just not for the reasons most people think.
