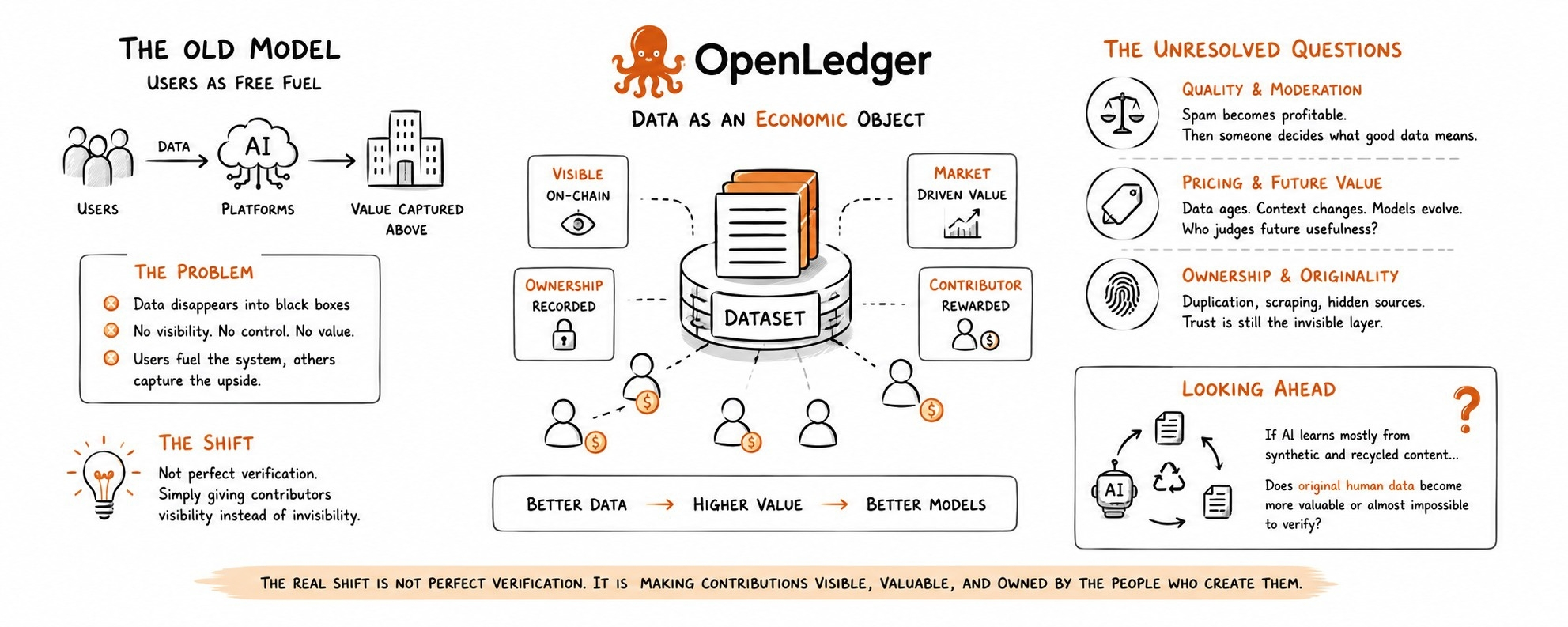
For a time I thought data inside crypto was mostly talk. People talk about owning data a lot but most systems still treat users like fuel for models and platforms. The value usually gets captured by the company building the AI or by those controlling the infrastructure.
That is partly why OpenLedger stayed on my mind longer than most AI projects I looked at this year.
I spent some time testing their ecosystem with datasets and honestly the strange part was not the tech. The strange part was seeing the system give a market value to information that normally gets ignored.
Not huge numbers. Not life-changing money.. Still a number.
That changed everything.
Usually when people upload data into AI systems it disappears. You never really know where it goes or how useful it becomes later. OpenLedger seems to be trying to make the opposite. The dataset stays visible as an object. That small design decision changes behavior more than people think.
I noticed people becoming picky.
Instead of uploading garbage just to get rewards some users started thinking more carefully about quality and consistency. The system quietly pushes people toward data because useless data has weak value. At least that is the theory.
I still wonder how stable this becomes once it gets big.
Every data marketplace says quality matters until spam makes money. Then moderation starts. Ranking systems appear. Reputation layers grow. Eventually someone still decides what good data means.
That part feels unresolved in OpenLedger.
Another thing I noticed is how hard pricing really is. A dataset can look valuable today. Become irrelevant later if models change. Some information gets old. Some becomes sensitive later. Some only matters when combined with datasets. So when the network gives value who is actually judging its usefulness?
That question stayed on my mind more than the rewards.
Most crypto AI systems now focus on compute power or agent activity. OpenLedger feels more focused on the raw input layer. That makes it different. Also exposes it to problems people are still underestimating. Data ownership sounds clean until disputes happen around originality duplication and scraping.
I even started checking some datasets carefully after seeing obvious recycled material. That made me realize something. Decentralized systems still depend heavily on trust even when they pretend everything is verified.
Maybe that is normal.
Maybe the real shift is not verification. Maybe it is simply giving contributors visibility of invisibility.
Still I keep thinking about one thing.
If AI systems eventually learn mostly from content and recycled outputs then what happens to the value of real human datasets later on? Does original information become more expensive or almost impossible to verify?
I do not think most people, inside crypto are thinking that yet.