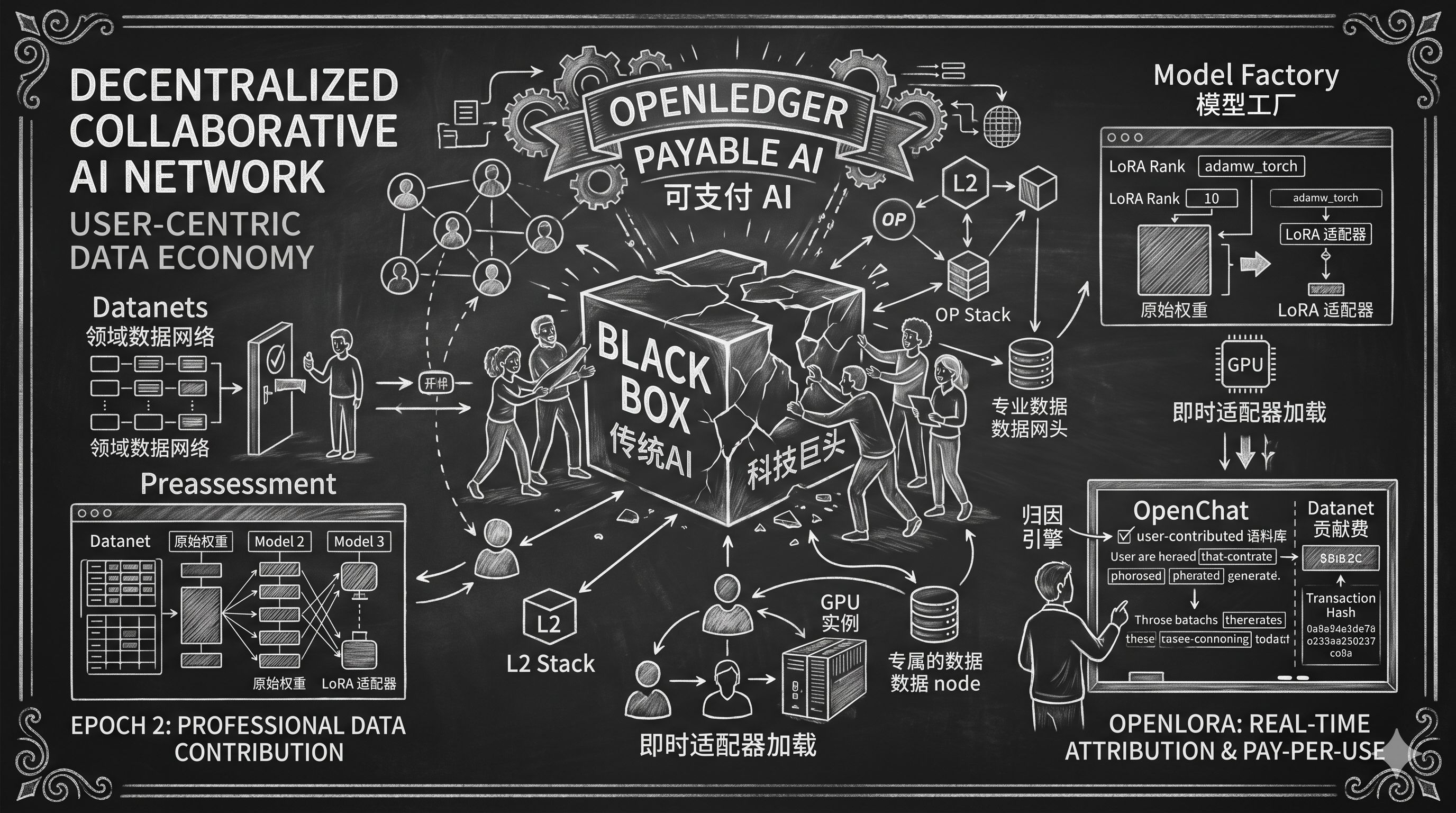
在通用人工智能(AGI)研发体系加速向专业化、领域特定化演进的今天,传统AI产业中由中心化科技巨头主导的AGI运作机制存在明显的数据剥夺与“黑盒化”。
#OpenLedger 一个专注于AI数据管线去中心化与可追溯性的L2区块链基础设施
我感觉他是想通过首创的“可支付 AI(Payable AI)”概念,试图构建一个数据与模型全生命周期均在链上锚定的去中心化协作网络,旨在打破传统 AI 数据利益分配的非对称性格局,也就是传统AI利益分配基本跟用户没有联系,用户是付钱获得AI服务,但Openledger能够让用户自己使用、自己创造、自己部署、自己获益的结构。
对于深度参与@OpenLedger 生态的建设者、数据贡献者以及模型开发者而言,该协议不仅是一套底层的账本协议,更是日常开发、训练与推理的核心工具链 。其底层采用基于 OP Stack 的以太坊 L2 Rollup 技术,通过优化状态转换函数,确保在大规模并发微交易场景下的密码学安全与执行效率,其系统状态转移方程定义为:sigma(s, T) → s',其中 s表示前置状态,T表示包含链上证明与交易的数据集,而 s'为转移后的有效状态 。
首先是领域数据网络与 Epoch 2 任务流
高质量的专业领域数据集(如医疗影像、法律卷宗、金融高频交易数据等)被组织为去中心化的“数据网络(Datanets)” 。数据贡献者可以通过社交认证登录平台并申请加入 Datanets 。进入 Epoch 2 阶段后,Datanet 引入了严格的准入机制,仅允许通过白名单审核的用户参与特定数据集的建设 。用户在正式承接数据贡献、验证或标注任务前,必须通过包含选择题和场景应用题的“前置评估(Preassessment)”测试 。通过考核后,用户可解锁具体的 Datanet 任务,完成验证并经过系统多重审核(Validation Process)后,方可获得相应的测试网积分(Testnet Points)与经验值(XP) 。这种设计能够有效过滤低质和恶意数据,但也显著增加了普通用户的参与门槛。
模型工厂与 GUI 微调控制台对于模型微调团队而言,OpenLedger 提供了免除命令行工具(CLI)与复杂 API 配置的“模型工厂(Model Factory)”控制台 。开发者仅需输入模型元数据,并选择行数不少于 1,500 行的 Datanets 作为微调基础 。模型工厂底层深度集成了 Supervised Fine-Tuning(SFT)、低秩适应(LoRA)及 4-bit 量化低秩适应(QLoRA)等先进微调算法 。在实际训练过程中,开发者可以通过 GUI 调节精细的参数指标,这些参数的配置直接影响到 GPU 显存占用与模型收敛性能。
数据配置:截断长度(Cutoff Length)默认设为 2048 Token,超出部分将被自动截断以防止显存溢出;最大样本数(Max Samples)默认上限为 100 万条。训练超参数:预处理线程数(Preprocessing Num Workers)默认为 16 以提升并行读取速度;单设备训练批次大小(Per Device Train Batch Size)默认为 2;梯度累积步数(Gradient Accumulation Steps)设为 8,从而在受限的物理显存下模拟更大批次的梯度更新。优化器与衰减:采用 adamw_torch 优化器,学习率设为稳定收敛的 5e-5,并搭配 cosine 学习率调度器进行平滑收敛。LoRA 参数:秩大小(LoRA Rank)默认为 8,LoRA 缩放因子(LoRA Alpha)设为 16,LoRA 目标模块(LoRA Target)指定为 all,以对模型的所有线性层(如 Attention 和 MLP)进行全面自适应微调。性能优化加速: 自动启用 Flash Attention(flash_attention: auto),并支持序列打包(Sequence Packing),通过消除无效 Padding 来最大化 GPU 推理和训练吞吐量,使用 bf16 半精度格式以在保障数值稳定性的前提下降低显存带宽压力 。相比传统的 P-Tuning 方法,模型工厂的 LoRA 微调在广告文本生成等任务中实现了高达 3.7 倍的训练加速,同时 Rouge 指标表现更为优异 。开放 LoRA 架构与即时适配器加载为了解决去中心化网络中成千上万个微调模型独立部署带来的计算开销与 GPU 显存浪费问题。同时OpenLedger 还开发了开放 LoRA 架构(OpenLoRA),支持在单一 GPU 实例上同时服务数千个经过微调的 LoRA 模型 。该框架的核心逻辑在于“即时适配器加载(Just-In-Time Adapter Loading)” 。当接收到推理请求时,系统并不会预先加载整个模型副本,而是动态地从去中心化文件系统(如 Hugging Face 或 Predibase)拉取目标 LoRA 权重适配器,并按需将其与基础 LLM 的共享权重进行实时合并。配合张量并行(Tensor Parallelism)和分页注意力(Paged Attention)机制,OpenLoRA 极大地压低了单次推理的计算成本与服务冷启动延迟。
最终当用户在 OpenChat 界面提交查询时,系统会触发链上微归因与结算机制。推理生成的内容流在前端实时输出的同时,内容会被拆分为句子或子句级别的 Token 窗口,并采用 BERT 或 Sentence-T5 等向量化模型进行嵌入(Embedding)。后端集成的归因引擎利用了基于 infinity-gram 语言模型算法的高保真匹配框架 。该引擎依靠后缀数组(Suffix Arrays)对海量 user-contributed 语料库进行无索引表、毫秒级延迟的实时刻匹配 。一旦发现生成的文本中包含源自 Datanets 的段落或模式特征,系统将在 UI 中对匹配短语进行下划线高亮显示,并在侧边栏展示数据源元数据、归因置信度得分(Confidence Score)及贡献者的 Transaction Hash 。此归因匹配会实时触发 Datanet 贡献费(Datanet Contribution Fee)的计算,实现精准的“Pay-per-use”利益分配 。$OPEN