been going through openledger’s architecture docs and contributor mechanics lately, mostly trying to understand what layer of the stack they actually believe matters long term. most people seem to frame it as another ai + crypto token project, but honestly that misses the more interesting part.
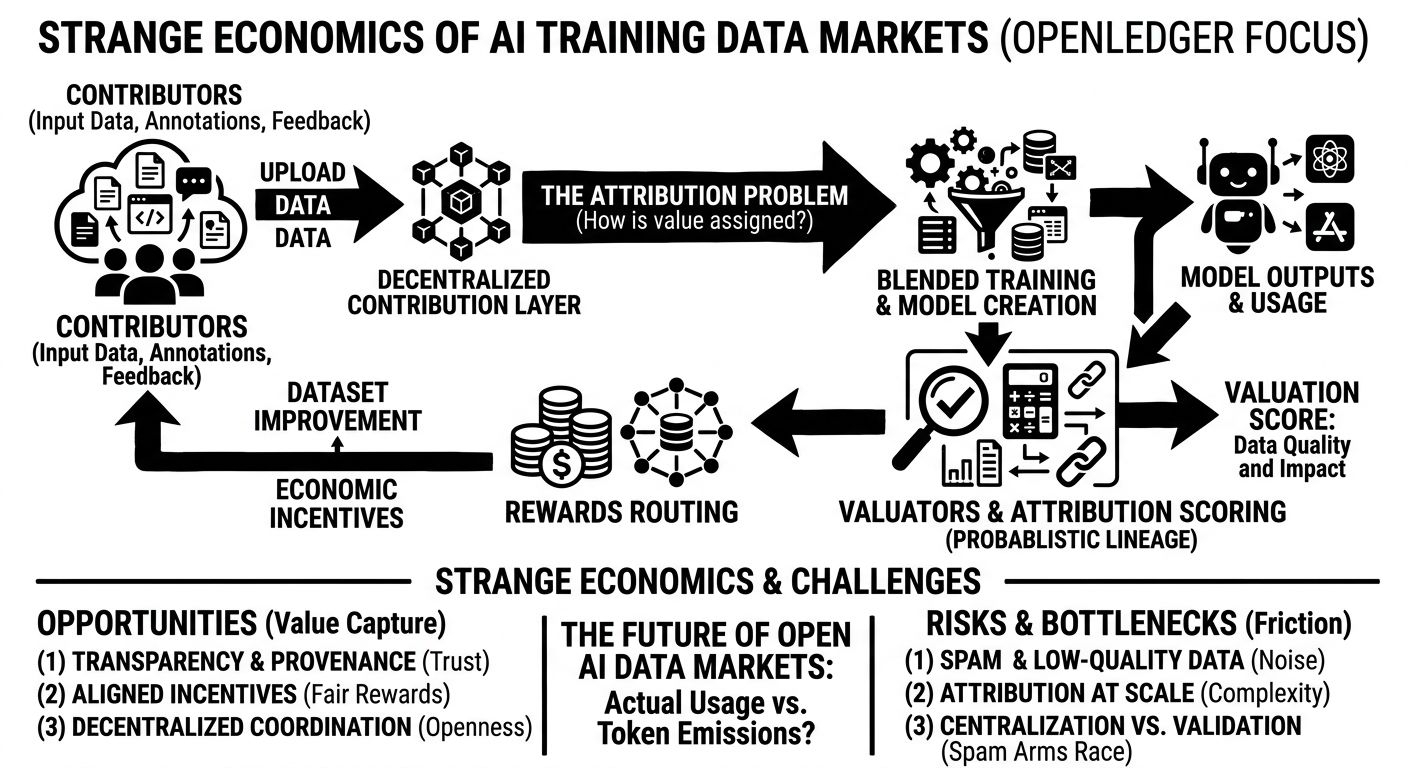
what caught my attention is that openledger isn’t really centered on model creation itself. the protocol seems more focused on attribution, provenance, and coordinating economic incentives around training data and model usage. basically: if data becomes one of the most valuable inputs in ai systems, can a network track where that value came from and distribute rewards accordingly?
that’s a much harder problem than decentralized inference or compute markets.
the decentralized contribution layer is the clearest example. contributors can supposedly upload datasets, annotations, structured domain knowledge, maybe even feedback loops tied to model outputs. instead of users passively improving closed systems for free, the protocol tries to turn contribution into something measurable and economically visible.
in theory, i get the appeal. imagine contributors providing multilingual legal documents that improve a compliance model operating across emerging markets. if those datasets materially improve accuracy for niche regulatory tasks, contributors should probably capture some downstream value instead of disappearing into the pipeline.
but then the architecture immediately runs into the attribution problem.
and this is the part i keep thinking about because ai systems don’t preserve clean lineage very well. once datasets are blended, transformed, fine-tuned, distilled, or mixed with synthetic augmentation, assigning contribution value becomes probabilistic rather than exact.
openledger seems to approach this through validators and attribution scoring systems tied to downstream model usage. contributors whose data improves outputs receive rewards through the network. conceptually, that’s one of the more coherent approaches i’ve seen in decentralized ai infrastructure.
still, i’m uncertain how trustworthy attribution remains at scale.
if thousands of contributors influence a model indirectly over multiple retraining cycles, does the protocol actually know who created useful signal versus noise? maybe approximately. maybe approximation is enough economically. but contributors still need confidence that the scoring system isn’t arbitrary or gameable.
the marketplace dynamics are interesting too because the protocol assumes future demand for transparent and attributable ai data systems. honestly, that assumption might be reasonable. companies dealing with licensing pressure or regulatory scrutiny probably will care more about provenance over time.
but there’s still a gap between “valuable in theory” and “operationally adopted.”
centralized systems remain easier to optimize because they control the entire stack — compute, deployment, tooling, feedback loops. decentralized systems usually compete through openness and composability, but those advantages take time to compound and only matter if enough participants actually care about shared coordination.
the token incentive layer feels necessary but fragile.
without emissions or rewards, contributors probably don’t supply valuable datasets before real marketplace demand exists. but if token incentives dominate activity for too long, the network risks attracting behavior optimized for extraction rather than utility.
spam feels like an unavoidable pressure point. duplicated public datasets, low-quality synthetic outputs, automated annotation farms — all economically rational if rewards are easier to earn than validation is to enforce. then validators become increasingly important, which introduces another coordination problem around quality control and potential centralization.
and honestly, i’m still unclear on who ultimately captures most of the value if the system works. contributors? validators? model operators? token holders? open coordination systems often begin with alignment narratives, but economics usually consolidate somewhere eventually.
still, compared to a lot of ai-related crypto infrastructure, openledger at least seems focused on a real bottleneck around provenance and incentive routing. that feels more grounded than projects treating decentralization itself as the product.
watching:
- ratio of real model demand versus incentive-driven activity
- attribution reliability across derivative and fine-tuned models
- validator effectiveness against spam submissions
- whether contributor rewards eventually come from actual usage rather than emissions
not really sure where i land yet. the architecture makes sense intellectually. i’m just uncertain whether open ai data markets mature quickly enough to sustain the coordination system underneath them.