A few years ago, whenever people talked about digital infrastructure, the conversation usually drifted toward scale. Faster networks. Bigger clouds. More compute. The assumption was simple enough: if a system can process more, it becomes more valuable. AI inherited that same logic almost automatically. Bigger models meant progress. More GPUs meant advantage. Markets still trade that story because it is easy to understand.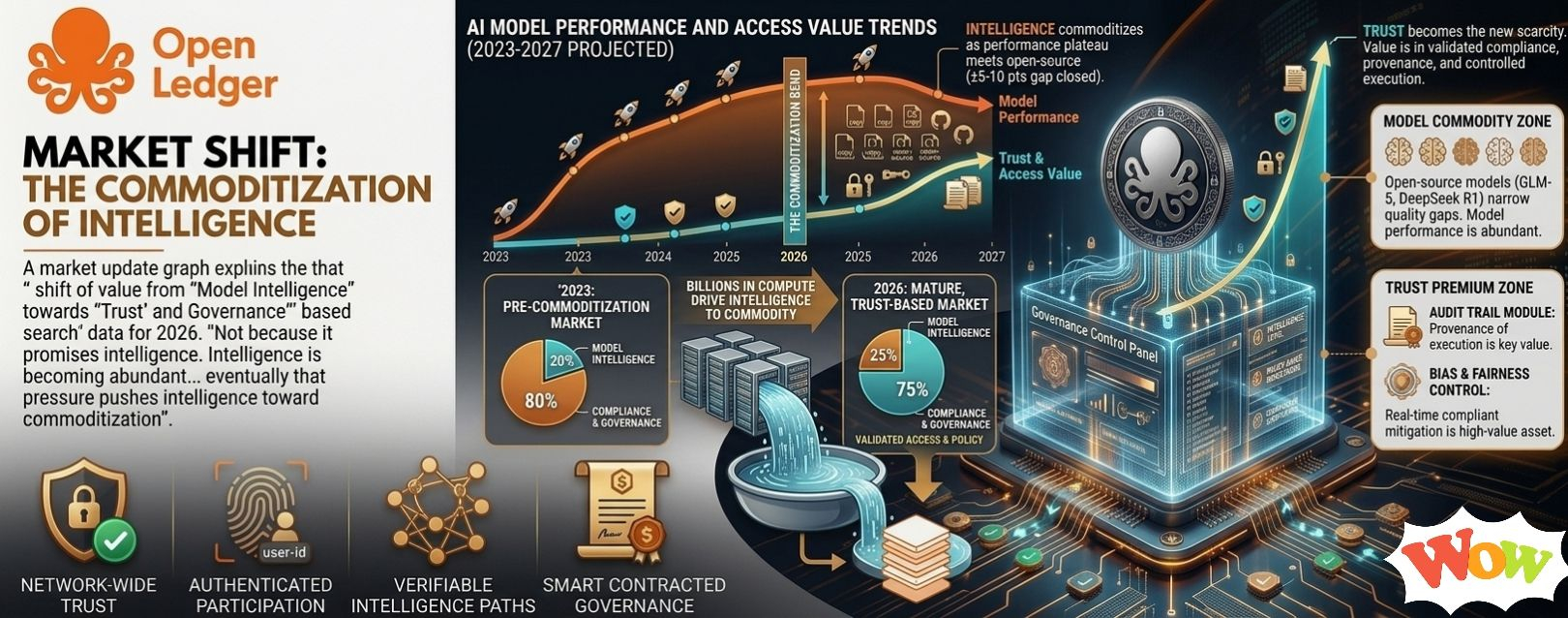
But practical systems do not always reward raw capacity the way speculative narratives do.
I keep thinking about something much less glamorous. Access control.
Not in the obvious software sense. More in the economic sense. Who gets trusted. Who gets allowed close to sensitive workflows. Who can meaningfully participate when outcomes actually matter.
That feels increasingly important, and I suspect the market is still underpricing it.
OpenLedger gets discussed like another AI marketplace. Contributors provide data. Builders consume intelligence resources. Tokens coordinate incentives. Clean story. Familiar story too. Crypto loves familiar stories because they slot neatly into old valuation habits.
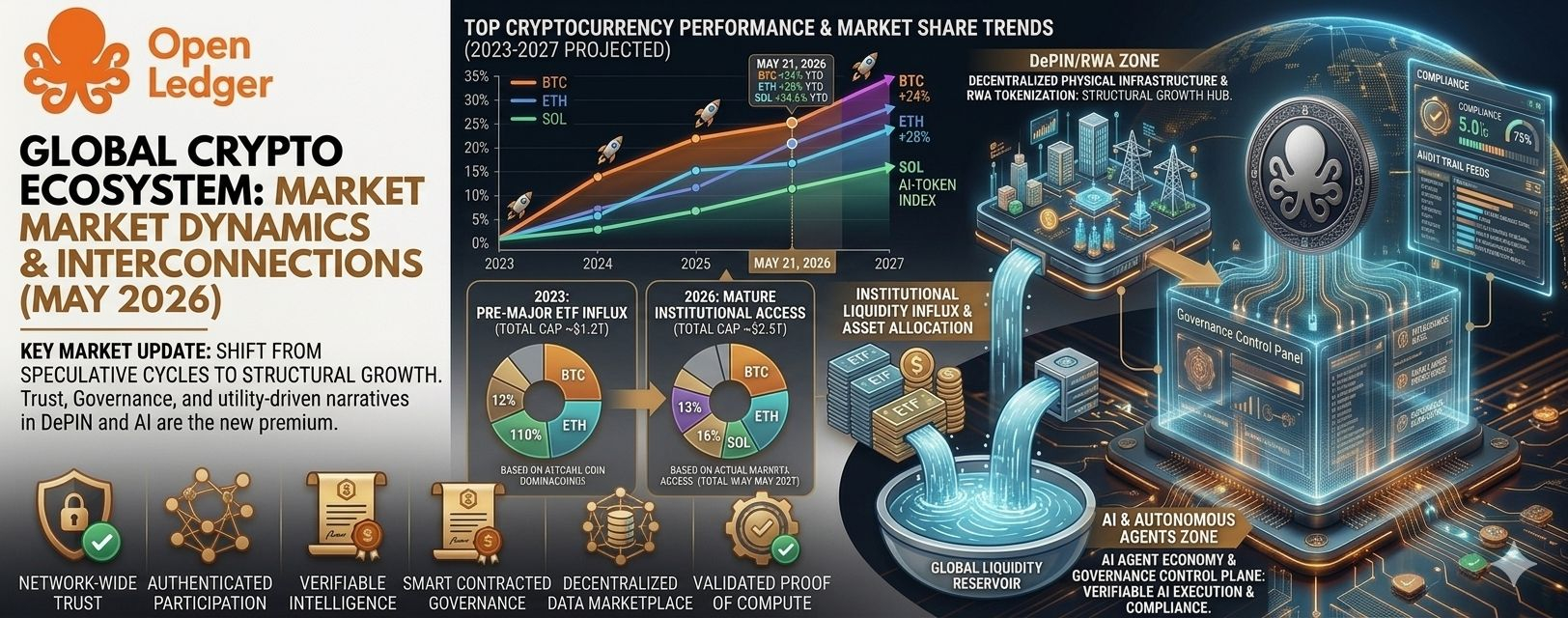
And yet, the current market still seems to be valuing projects mostly around hype cycles, trading narratives, and short-term attention. Meanwhile, AI infrastructure spending keeps accelerating globally, while enterprise conversations are shifting toward transparency, attribution, compliance, and control. That disconnect feels important.
Still, the more I look at what real AI adoption problems actually look like, the less convinced I am that “marketplace” is the right mental model.
The harder problem may not be matching supply with demand.
It may be deciding who qualifies to supply anything in the first place.
That sounds subtle, maybe even semantic, until you move outside consumer AI.
If someone uses an image generator to make profile pictures, mistakes are annoying. Maybe funny. Nobody opens a compliance review because an anime portrait had six fingers.
But if an AI system helps route insurance approvals, flags suspicious payments, assists legal review, screens enterprise documents, or shapes customer access decisions, the tone changes fast.
Now everyone wants boring answers.
Where did this data come from?
Who trained this model?
Can we trace why the output happened?
Was the underlying source licensed?
Who becomes accountable if this breaks?
Those are not technical curiosity questions. They are operational survival questions.
And honestly, crypto people sometimes underestimate how much large organizations care about these details. Engineers may love open experimentation. Legal departments do not.
This is where OpenLedger starts looking different to me.
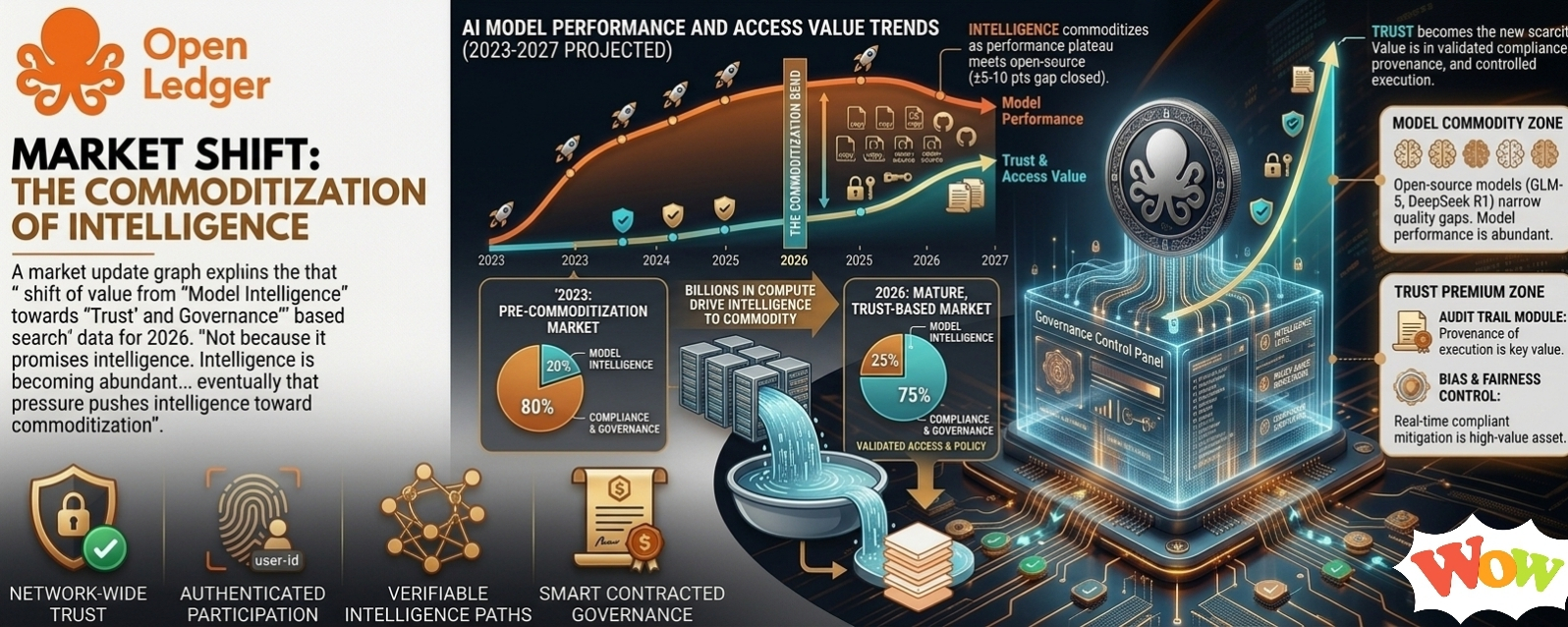
Not because it promises intelligence.
Intelligence is becoming abundant, or at least less scarce than people assumed. Model performance keeps improving across the market. Open-source models keep narrowing quality gaps faster than expected. The industry is pouring billions into compute and infrastructure, and eventually that pressure pushes intelligence toward commoditization.
But trust does not scale the same way.
That is slower. Messier.
If OpenLedger is simply paying contributors for useful data, fine. That is understandable. But plenty of token systems have tried reward-based contribution markets before. Most struggle because paying people to show up is not the same thing as creating organic demand.
Incentive loops can manufacture activity. They do not automatically create necessity.
The more interesting possibility is that OpenLedger is not really pricing contribution itself.
It might be pricing eligibility.
That distinction matters more than it sounds.
Take two datasets. One comes from broadly scraped public sources with uncertain ownership history. The other comes from verified contributors with explicit rights, documented provenance, and known usage conditions.
Technically, both may help train a model.
Economically, they are not interchangeable.
One carries uncertainty that becomes expensive later.
The other reduces friction before problems emerge.
That difference is where value starts accumulating.
Same story with AI agents.
Everyone talks about autonomous agents like deployment is just around the corner. Maybe it is. But if machine agents begin handling financial workflows, contract interactions, internal operations, or external decision support, capability alone will not be enough.
No serious operator wants unknown agents touching sensitive systems simply because they appear competent.
Competence without trust creates liability.
So what becomes scarce?
Permission.
Trusted permission, specifically.
That is a very different infrastructure layer than the market seems to be discussing.
I think this happens in almost every system eventually. Open environments start idealistic. Broad participation sounds efficient. Then scale introduces noise, abuse, uncertainty, bad actors, and hidden costs. Suddenly filtering becomes the real product.
Payments did this.
Cloud infrastructure did this.
Identity systems did this.
Even social platforms, despite all the rhetoric around openness, quietly built ranking, trust, and visibility hierarchies.
AI probably follows the same path.
OpenLedger’s attribution architecture matters more under that lens. Attribution sounds like a rewards mechanism at first. A way to pay contributors fairly.
Maybe.
But attribution can also function as permission infrastructure.
A record of who contributed what. Under what conditions. With what history. With what trust profile.
That changes system behavior.
Instead of every participant being treated equally by default, networks begin assigning differentiated economic credibility.
Some people will hate that framing because it sounds less decentralized.
And to be fair, that concern is valid.
Permission markets can become gatekeeping systems surprisingly fast. Once economic value attaches to trust status, governance becomes political. Who decides what counts as trusted? Who gets excluded? Can reputation be manipulated? Does the token become infrastructure, or just a toll booth?
These are not minor risks.
There is another problem too. Enterprise adoption does not happen because infrastructure sounds elegant in crypto discussions.
It happens when operational pain becomes unbearable.
That threshold may take longer than token markets expect.
Plenty of companies will choose conventional AI vendors instead of tokenized coordination layers simply because procurement teams understand traditional contracts better than protocol economics.
And even if OpenLedger solves meaningful infrastructure problems, that still does not guarantee $OPEN captures durable value.
Crypto regularly gets this wrong.
Useful protocol does not automatically mean valuable token.
Still, I cannot shake the feeling that the market is asking the wrong question.
People keep asking whether OpenLedger can become a successful AI marketplace.
That feels like yesterday’s framing.
The more relevant question might be whether AI systems are entering a phase where trusted access becomes more economically important than raw intelligence supply.
Because if that happens, the valuable layer is no longer compute.
It is controlled participation.
And weirdly, those tend to become some of the stickiest infrastructure businesses once markets mature.
