
I see OpenLedger (OPEN) as a protocol attempting to sit at the intersection of AI infrastructure and blockchain-based coordination of data, models, and autonomous agents. In my assessment of OpenLedger (OPEN), the core thesis appears to be that valuable AI inputs—datasets, trained models, and agent outputs—remain structurally under-monetized in centralized systems, and that a decentralized ledger could theoretically reprice and redistribute that value. I am skeptical of whether OpenLedger (OPEN) is addressing a genuinely unsolved technical constraint or instead reframing an already competitive problem space that includes data marketplaces, decentralized storage systems, and AI compute networks. The existence of OpenLedger (OPEN) makes conceptual sense in a world where provenance and attribution matter, but I notice that the actual demand for on-chain data licensing at scale remains unproven outside of niche ecosystems.
When I break down OpenLedger (OPEN) through an economic lens, I see a system that likely depends on heavy early-stage incentives to bootstrap participation. In OpenLedger (OPEN), the “faucets” appear to be emissions-driven rewards for data contributors, liquidity incentives for token holders, and ecosystem grants intended to attract builders and early adopters. These faucets are typical for emerging protocols, but in OpenLedger (OPEN) they raise concerns about supply expansion that is not immediately matched by organic fee generation. The “sinks” in OpenLedger (OPEN), such as staking requirements, protocol usage fees, or model access payments, would need to be strong and recurring to offset inflation, yet I do not see clear evidence that these sinks are structurally dominant rather than aspirational. This creates a potential imbalance in OpenLedger (OPEN), where token velocity is more influenced by issuance than by sustained demand, which in turn risks weakening long-term economic stability.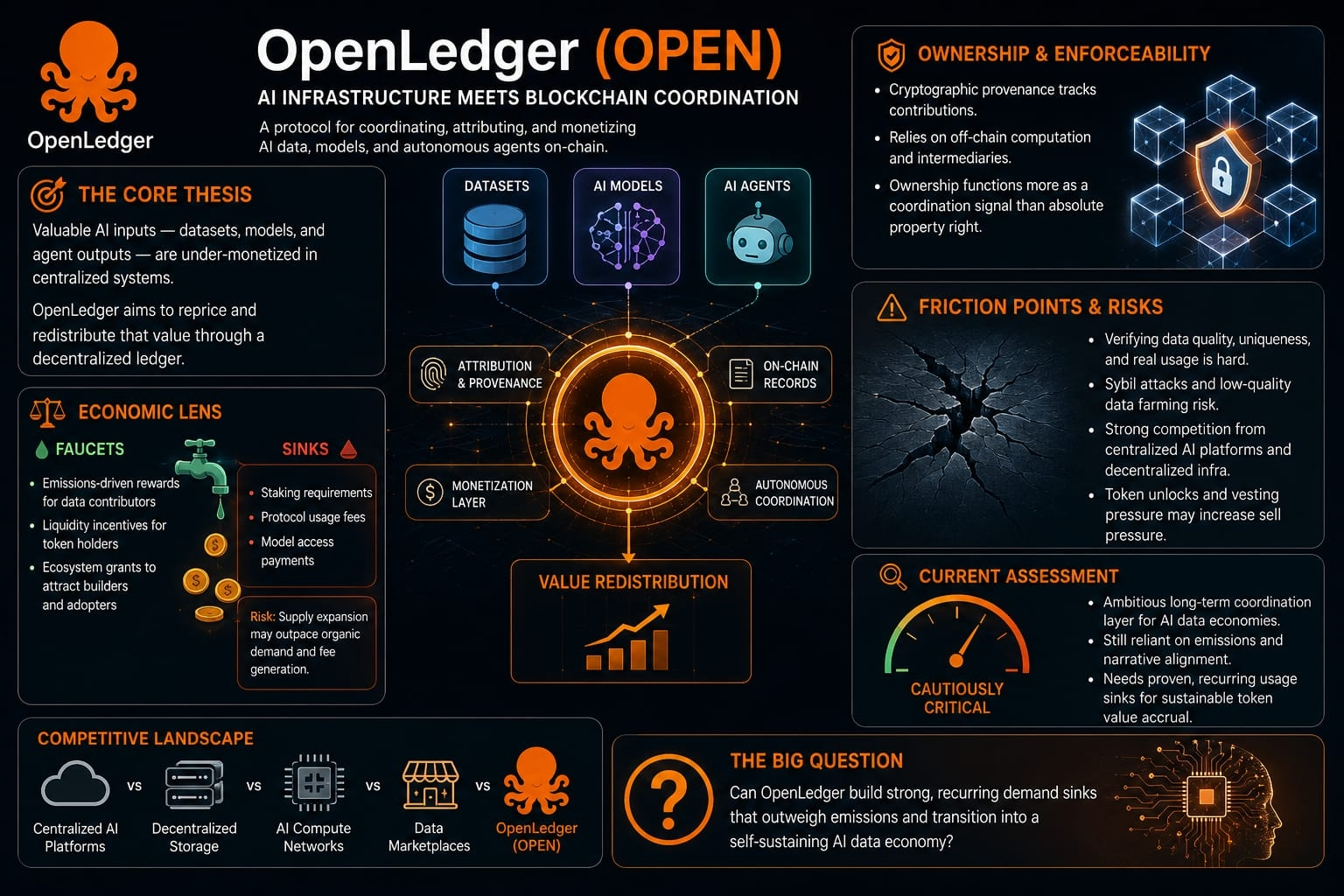
From a coordination and ownership perspective, OpenLedger (OPEN) presents an ambitious narrative around user sovereignty over data, models, and agent-derived outputs. In practice, however, I notice that OpenLedger (OPEN) must rely on layered verification systems, off-chain computation, and intermediaries to make attribution meaningful and enforceable. This introduces a gap between the concept of ownership and its real enforceability inside OpenLedger (OPEN), especially when data is transformed, aggregated, or used in machine learning pipelines where lineage becomes probabilistic rather than absolute. Even if OpenLedger (OPEN) implements cryptographic provenance tracking, I remain skeptical that this alone translates into enforceable economic rights without relying on external legal or centralized arbitration frameworks. As a result, ownership in OpenLedger (OPEN) risks functioning more as a coordination signal than as a fully realized property regime.
I also see several friction points and structural risks in OpenLedger (OPEN) that could affect long-term viability. One major issue is verification: OpenLedger (OPEN) must determine whether contributed data is unique, high-quality, and actually used in downstream AI processes, which is inherently difficult to validate without introducing trusted intermediaries. This creates a potential attack surface for Sybil behavior or low-quality data farming, especially if incentives remain strong in OpenLedger (OPEN) while verification costs remain low. I also observe that OpenLedger (OPEN) operates in a highly competitive macro environment where centralized AI platforms already control distribution, and decentralized alternatives are competing for both compute and data layers. Without clear dominance in either niche, OpenLedger (OPEN) risks being squeezed between infrastructure-heavy competitors and application-layer AI systems. I also remain cautious about token unlock dynamics in OpenLedger (OPEN), as any significant future vesting pressure without matching demand sinks could introduce sustained sell pressure.
My final assessment of OpenLedger (OPEN) is cautiously critical rather than dismissive. I recognize that OpenLedger (OPEN) is attempting to build a long-term coordination layer for AI data economies, which is a legitimate and forward-looking design goal. However, I do not yet see strong evidence that OpenLedger (OPEN) has resolved the fundamental economic tension between incentive-driven growth and sustainable demand generation. The system still appears to rely heavily on early emissions and narrative alignment rather than proven, recurring usage sinks that would justify durable token value accrual. For that reason, I currently view OpenLedger (OPEN) as an early experimental coordination system with meaningful conceptual ambition, but one that still needs to demonstrate that its economic loops can survive beyond bootstrap incentives and transition into self-sustaining market demand.