I’ve been spending late nights reading AI whitepapers, testing decentralized data systems, and watching how these new networks actually behave under pressure. And honestly, one question keeps following me around no matter how deep I go into the research: when millions of people contribute knowledge to train AI, who really owns the value created afterward?
That question feels uncomfortable because most people still focus only on model performance. Faster inference. Bigger parameter counts. Better benchmarks. But beneath all that noise, a deeper economic shift is happening. AI is becoming a data economy, and the people supplying the raw intelligence are finally starting to ask whether the system will remember them at all.
As someone who has traded through multiple crypto cycles, I’ve seen this pattern before. Infrastructure narratives usually look boring at first. Then suddenly they become the foundation everything else depends on. That’s partly why projects like caught my attention during my research this year.
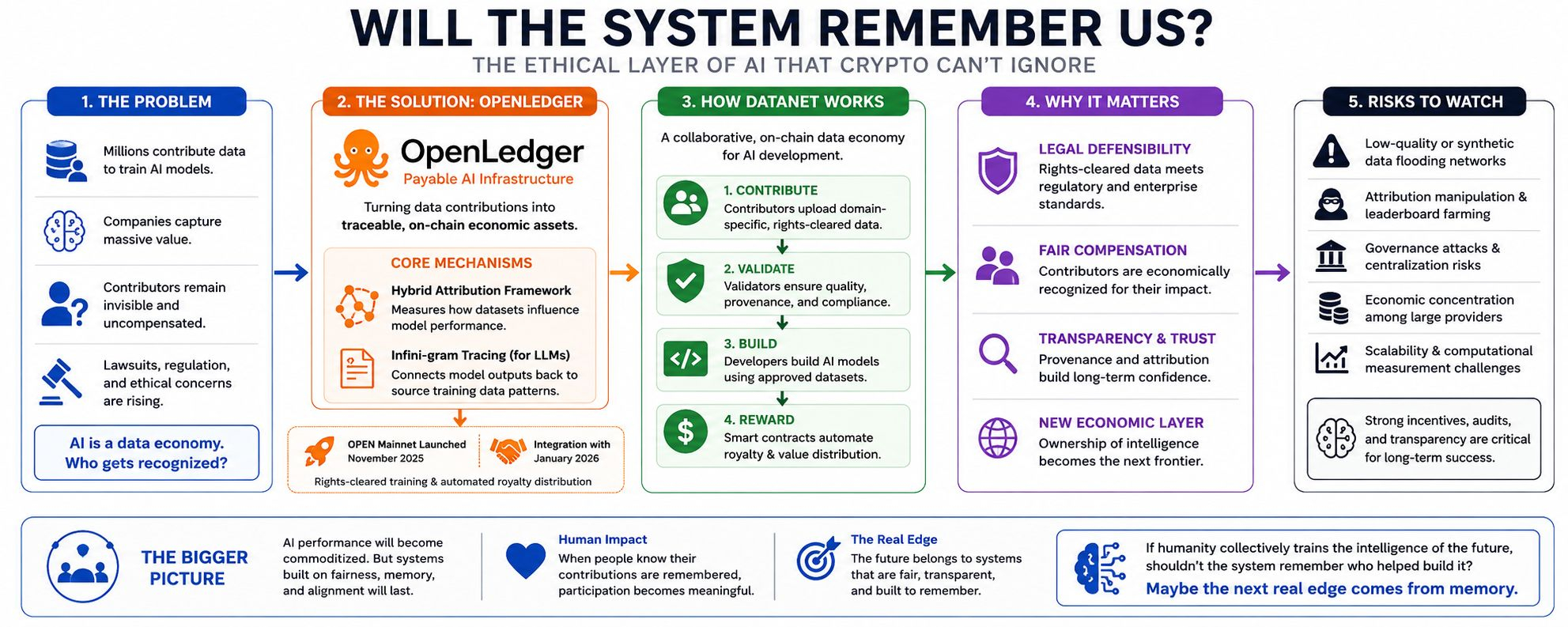
The idea behind the network sounds simple on paper but becomes much bigger once you think through the implications. Instead of treating datasets like invisible fuel for AI companies, OpenLedger is trying to turn data contributions into traceable on-chain economic assets. Not just “data used.” Data attributed. Data measured. Data rewarded.
Their OPEN Mainnet officially launched in November 2025, moving the protocol from experimental infrastructure into a live economic network. Since then, the ecosystem has been building around something they call “Payable AI.” At first, I thought it sounded like another marketing phrase. Crypto is full of those. But after digging through the whitepaper and developer documentation, the mechanics are actually more interesting than the branding.
The system uses a hybrid attribution framework to estimate how much specific datasets contribute to model performance. For smaller specialized models, the protocol relies on gradient-based attribution methods. In simple language, the network measures how model performance changes if certain data disappears. For larger language models, the architecture uses Infini-gram tracing, a suffix-array-based approach designed to connect generated outputs back toward source training data patterns.
No, it’s not mathematically perfect. And honestly, anyone claiming “perfect attribution” in trillion-token AI systems is oversimplifying reality. But the important thing is that the industry is finally moving toward measurable provenance instead of blind extraction.
That shift matters more than many traders realize.
Throughout 2024 and 2025, lawsuits over AI training data accelerated globally. Media companies, artists, publishers, and software communities increasingly challenged how models were trained without attribution or compensation. Regulators also started asking harder questions around licensing and verifiable provenance. Suddenly the conversation stopped being only technical. It became economic and legal.
That’s where crypto infrastructure enters the picture.
OpenLedger’s DataNet model attempts to create collaborative on-chain datasets where contributors, validators, and developers interact inside one transparent economic layer. Contributors upload domain-specific data. Developers build specialized AI systems on top. Smart contracts help automate how value moves afterward.
Then in January 2026, OpenLedger expanded the model further through its integration with , focusing on rights-cleared AI training and automated royalty distribution. That partnership caught attention because it pushed the discussion beyond theory. Enterprises in finance, healthcare, and legal technology increasingly need datasets that are not only useful, but legally defensible. That changes everything.
I think many traders still underestimate how important this trend could become.
For years, crypto focused heavily on ownership of money and digital assets. AI may force the industry into something even bigger: ownership of intelligence itself. Who owns the data? Who owns the outputs? Who gets compensated when models generate billions in value from human contribution?
And yes… there are risks everywhere here.
Low-quality synthetic data flooding networks. Attribution manipulation. Leaderboard farming. Governance attacks. Economic concentration among large dataset providers. I’ve personally tested enough AI tooling now to know that bad incentives can destroy promising ecosystems very quickly if validation layers fail.
There’s also the scalability problem. Measuring contribution across massive AI systems is computationally difficult. Over time, independent audits and transparent network metrics will matter far more than whitepaper promises. Infrastructure-first projects survive only when real-world usage validates the theory.
Still, something about this movement feels different to me compared to previous AI hype cycles.
When contributors know their work can be tracked and economically recognized, participation changes psychologically. People stop feeling like disposable inputs feeding invisible systems. The relationship becomes more cooperative. More accountable. Maybe even more human.
And honestly, that might become the real competitive advantage over the next decade.
Because eventually, AI performance alone will become commoditized. Faster models will always appear. Cheaper inference will always arrive. But trust? Transparent provenance? Fair economic alignment? Those things are much harder to replicate once users decide which systems deserve long-term participation.
I don’t think the future AI economy will belong only to the smartest models. I think it will belong to the systems people believe are fair.
That’s the deeper layer I keep coming back to after months of research and experimentation. Crypto originally promised ownership without middlemen. AI now forces us to ask a harder philosophical question: if humanity collectively trains the intelligence of the future, should the system remember who helped build it?
Maybe the next real edge in this market won’t come from speed alone.
Maybe it comes from memory.
