there’s a question nobody is asking about OpenLedger’s incentive design. and I think it’s the only question that actually matters.
I spent a long time thinking about why most decentralized data economies fail. not at the architecture level — at the behavioral level. the answer is almost always the same: the incentive to contribute and the incentive to stay contributed are different incentives. most protocols solve the first one and ignore the second entirely.
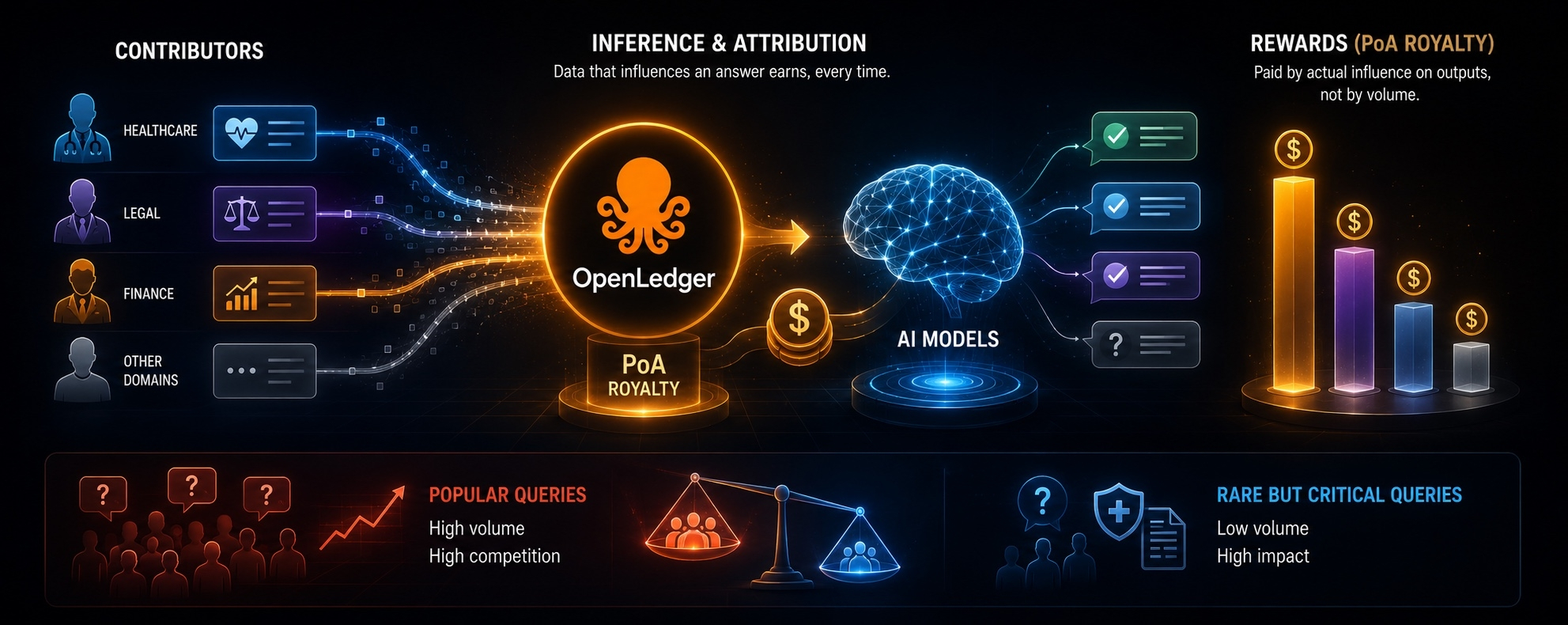
OpenLedger’s royalty model is the most serious attempt I’ve seen at solving both simultaneously. data earns every time it influences an inference — not once at upload, not proportionally to volume submitted, but proportionally to how much your specific contribution changed a specific answer. the economic logic is clean. contribute something models actually need, earn every time they need it.
but the longer I sit with this, the more I notice a tension the design hasn’t fully resolved.
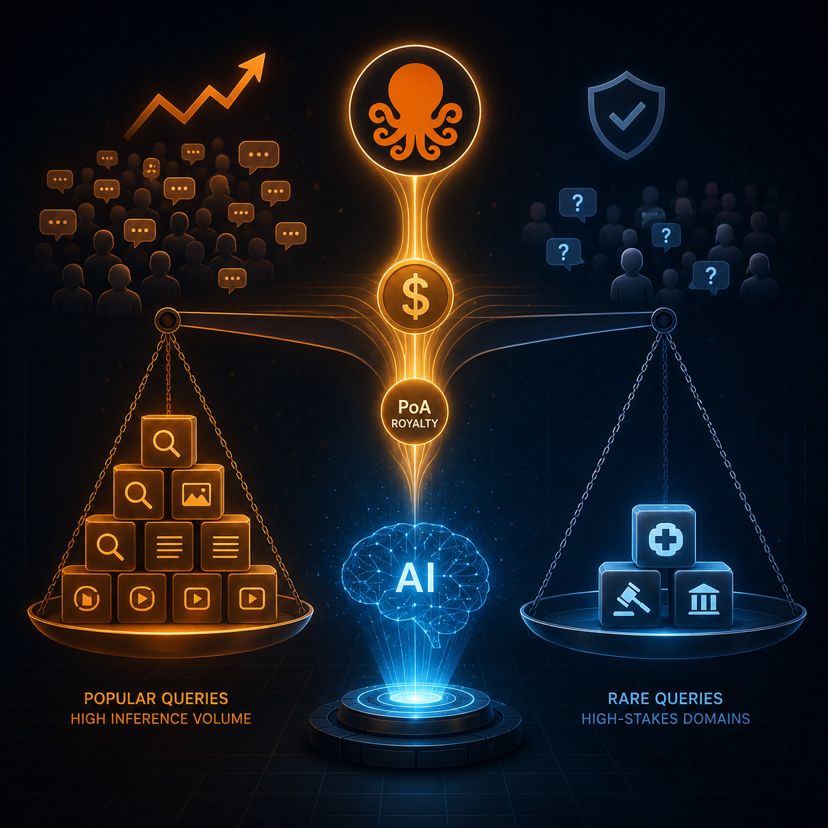
PoA rewards influence on actual outputs. influence is highest when a model consistently reaches for your data when answering a specific type of question. once contributors understand this — and the sophisticated ones will, quickly — the rational strategy becomes identifying which query types generate the most inference volume and curating data specifically to maximize influence on those. not gaming the system in a crude sense. the system working exactly as designed.
the problem is what that optimization does to coverage.
in healthcare, legal, and financial domains — the use cases where attribution-based data provenance matters most — the most important questions are often the least frequently asked. rare disease diagnoses. edge case contract interpretations. unusual regulatory scenarios. if PoA rewards route disproportionately toward high-volume query types, the domains where provenance matters most may be precisely where the incentive structure creates the least coverage.
this is a subtle failure mode. not a scam, not a technical flaw — just emergent behavior from rational contributors responding to a well-designed incentive. the network gets very good at what’s popular. potentially underinvested in what’s rare but critical.
unless OpenLedger introduces counter-forces at the protocol level. subsidies for low-volume Datanets in high-stakes domains. reputation weighting that distinguishes contributors who maintain coverage of rare queries from those who optimize purely for inference volume. scarcity premiums for domains where quality data is genuinely hard to source. protocol-directed incentives that treat coverage as a public good rather than leaving it entirely to market forces.
none of these mechanisms exist publicly in the current design. maybe they’re planned. maybe the team has thought about this more carefully than the public documentation suggests. or maybe the coverage problem doesn’t manifest until the network reaches a scale where query concentration becomes visible in the data.
that’s what connects this to September. the unlock doesn’t pause for any of this. 33.29% of supply enters the market on a schedule built around vesting timelines, not ecosystem readiness. the incentive design question and the supply pressure question are running on separate clocks — and September is where those clocks converge.
the metric I’d watch before then isn’t price. it’s active Datanets with real inference volume in the domains that matter most — legal, medical, financial edge cases. if those numbers are growing alongside general-purpose Datanets, the coverage problem is self-correcting. if they’re flat while general-purpose Datanets grow, the royalty model has a structural gap nobody is talking about yet.
nobody has published that breakdown publicly. that silence is the most interesting data point I have right now.
what happens to PoA reward distribution when contributors start optimizing specifically for influence scores rather than for coverage? 👇