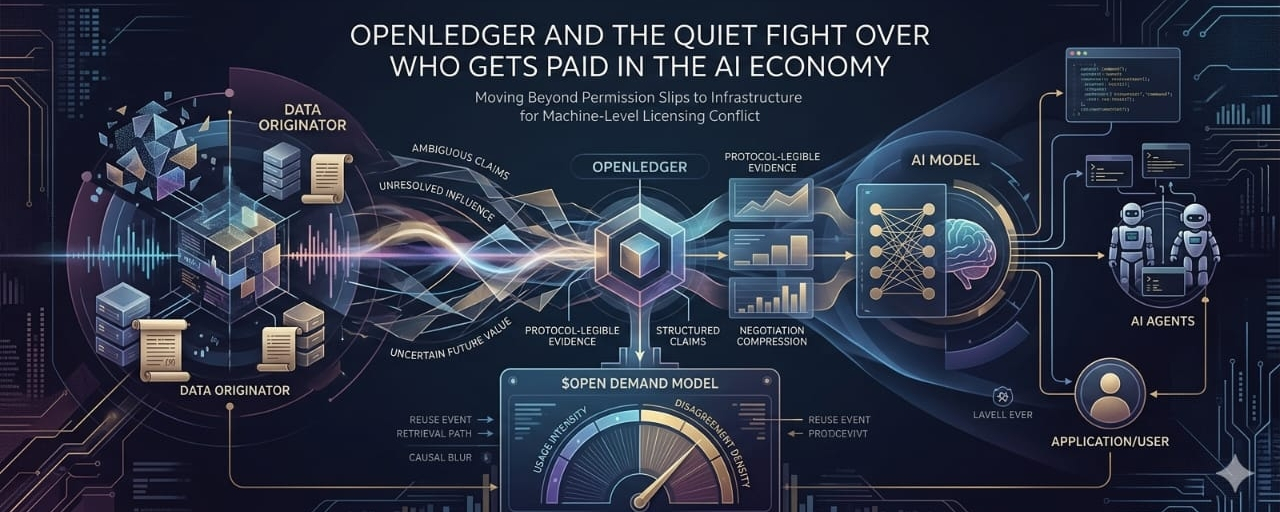
I used to think AI licensing would stay fairly simple. Maybe not easy, but simple in shape. A company owns data, a model wants access, both sides agree on terms, and some contract or API rule decides what is allowed. That was the obvious version in my head. But the more I look at what OpenLedger is trying to build, the less I think this future is really about permission slips. It feels much more like something deeper. Not just who can access what, but how machines, agents, data owners, model builders, and applications negotiate when value becomes unclear after the fact. That is where the real tension begins, because AI does not create clean economic lines. It absorbs, blends, retrieves, reshapes, remembers, forgets, and reuses context in ways that make simple ownership language feel too weak for what is coming.
The real issue may not be access. Access is easy to understand. Either a system can use something or it cannot. But once AI agents start interacting with proprietary data, external tools, inference services, and other machine systems in real time, the harder question becomes pricing. What exactly is being priced when an AI uses a dataset? Is it the original data? The temporary access? The influence that data had on model behavior? The commercial value created later? The right to reuse the output? The liability if something harmful happens downstream? None of these questions behave like fixed permissions. They behave like ongoing negotiations around uncertain future value. That is why OpenLedger starts to look less like a basic data coordination layer and more like infrastructure for machine-level licensing conflict before it ever reaches a courtroom.
And I do not mean conflict in the loud legal sense. I mean the quieter kind of conflict that happens whenever two systems have partial claims and no perfect way to prove the full truth. A data contributor may say their input shaped a model’s behavior. A model operator may say that influence is hard to isolate. An AI agent may only want short-term access with limited downstream use. Another party may want recurring compensation if future outputs keep creating value from earlier inputs. Everyone has a piece of the story, but nobody has the full picture. In that kind of environment, the winning infrastructure is not necessarily the one that reveals perfect truth. It may simply be the one that makes enough of the disagreement visible, structured, and negotiable.
That is the part that makes OpenLedger interesting to me. Maybe the product is not attribution in the romantic way people usually describe it. Maybe the real product is negotiation compression. It takes messy, blurry, machine-generated claims and makes them structured enough that different actors can respond to them. Not perfectly. Not completely. But enough for a market to form around them. Markets do not need perfect truth to function. They need shared rules strong enough for disagreement to become tradable. That is a very different way to think about AI licensing. It turns licensing from a static agreement into a living economic process where value, rights, and compensation keep adjusting as usage evolves.
This is also why creator ranking systems keep coming to mind. On the surface, those systems reward influence, but they do not really measure total influence. They measure the evidence of influence that becomes visible to the system. Engagement, freshness, relevance, visibility, retention, signals that survived the ranking logic. Not the entire truth of someone’s impact. Only the part that became legible enough to score. AI licensing may follow the same pattern. It may not reward what was absolutely true. It may reward what survived protocol interpretation. The system decides based on what it was allowed to see, and that sentence feels more important the longer I sit with it.
Because once AI systems become economically active, causality gets extremely blurry. A model trained on blended sources might produce something valuable months or years later. So what should be priced? The original contribution? The inference event? The retrieval path? The memory that stayed inside the system? The agent chain that turned one output into another? The application that finally captured the user value? The old ownership model assumes clean object boundaries, but AI systems rarely behave that cleanly. Weights compress origins. Fine-tuning changes behavior. Agents call tools, rewrite prompts, cache context, route decisions, and build on previous outputs. Somewhere inside that flow, economic entitlement becomes unstable. Not meaningless, but unstable.
That instability may be exactly where $OPEN becomes more interesting. If OpenLedger sits inside the loop where machine actors negotiate rights, claims, access, compensation, and evidence, then token demand may not simply reflect AI usage in a basic way. It may reflect how often AI systems run into ambiguity that needs to be priced. That is a very different demand model. It is not only about more data, more agents, or more applications. It is about disagreement density. The more machine economies create unresolved claims around ownership, influence, reuse, and value, the more important the negotiation layer becomes.
This sounds strange at first, but it is not that different from older infrastructure patterns. Ports became valuable because trade needed coordination. Exchanges became valuable because buyers and sellers rarely agree naturally. Clearing systems became valuable because trust does not scale by itself. Maybe AI licensing develops the same shape. Not because machines need prettier contracts, but because they will create too many ambiguous reuse events for humans to manage manually. In that kind of world, the layer that structures disagreement may become more valuable than the raw asset being disputed.
But there is one uncomfortable part that should not be ignored. Whoever defines the evidence schema quietly defines the market. If OpenLedger or any similar protocol decides what counts as recognizable proof, then it is not just neutral plumbing. It shapes which claims can be made, which ones can be challenged, which ones can be scored, and which ones disappear before negotiation even begins. That is where infrastructure becomes governance without announcing itself as governance. A contribution that mattered but was never properly emitted into the system may effectively become invisible. A licensing claim that is socially true but not protocol-legible may become economically dead.
That boundary is where the whole story gets serious. Because once machine systems begin treating protocol-visible evidence as negotiation reality, absence becomes powerful. Not because something was disproven, but because it never survived formatting. Before anything is decided, most of the complexity may already be missing. That does not mean the infrastructure is broken. Simplification is necessary for markets to work. But it does mean the design choices matter more than they first appear.
So when I look at OpenLedger now, I do not only see a data ownership story. I do not even see only an attribution story. I see a possible negotiation layer for contested machine reality. A place where AI agents, data providers, model operators, and applications may eventually argue through structured evidence instead of human paperwork. And if that layer hardens, everything downstream may start behaving as if the visible version of reality was the complete version. That is the part I cannot stop thinking about, because the future of AI licensing may not be decided by who owns the data first. It may be decided by who defines what becomes legible enough to negotiate at all.
