Avevo una cartella segnalibri chiamata “Tool AI da riprovare”.
Sembra molto organizzato. In realtà, somiglia più a un cimitero. Ho salvato un sacco di tool, agent, chatbot, plugin perché quando li ho lanciati sembravano interessanti. Demo belle. Thread di analisi lunghi. Ce n'è anche uno che mi ha fatto pensare: “Sì, questo probabilmente lo userò spesso.”
Poi non li ho più riaperti.
Non è che siano rotti o non funzionino bene. È molto più semplice: non sono abbastanza essenziali per entrare nella mia routine.
Quando leggo di OpenLedger, quella sensazione torna in modo più serio.
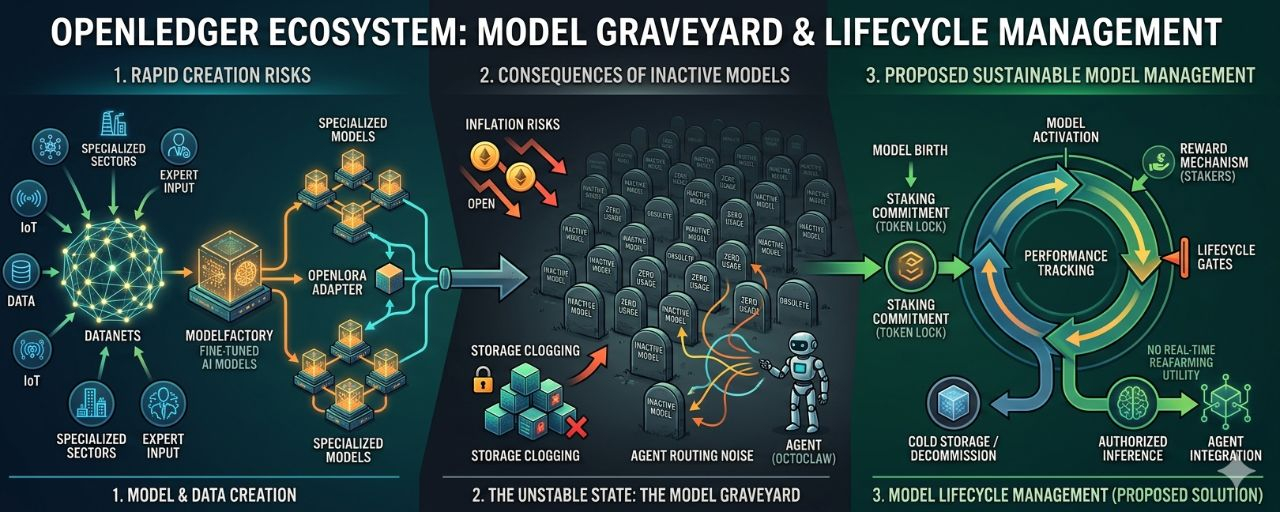
OpenLedger sta costruendo un ecosistema per modelli AI specializzati: ci sono Datanets per raccogliere dati specifici, ModelFactory per fare fine-tuning, OpenLoRA per servire più modelli in modo più efficace, Proof of Attribution per riconoscere i contributi, e inferenza a pagamento per generare ricavi dai modelli. Questo è un pipeline molto ragionevole.
Ma proprio perché quel pipeline è ragionevole, il rischio che ne deriva è ancora più spaventoso.
Se creare modelli diventa più facile, se i dati vengono raccolti più rapidamente, se ogni comunità può avviare un modello specializzato, allora la domanda non è più "ci sono abbastanza modelli?"
La domanda è: quanti di questi modelli meritano davvero di esistere?
Chiamo questo problema il Cimitero dei Modelli.
Un cimitero di modelli non è solo un luogo con molti modelli che nessuno usa. Se fosse solo così, sarebbe piuttosto innocuo. Il peggio è che il dashboard è un po' brutto, alcuni progetti vengono dimenticati e alcune persone perdono tempo.
Ma in una blockchain AI come OpenLedger, i modelli morti non rimangono fermi.
Questo comporta dei costi.
Il primo costo è l'inflazione dell'incentivo. Se il sistema continua a distribuire ricompense per troppi modelli che non hanno dimostrato una vera domanda, il token sarà risucchiato nel mantenere un'offerta falsa. I contributor vedono le ricompense, quindi continuano a generare dati, modelli e attività. Ma quell'attività non necessariamente genera inferenze genuine. Quando le ricompense si distaccano troppo dalla domanda, il token non è più un segnale di valore. Diventa carburante per mantenere l'illusione che l'ecosistema stia crescendo.
Il secondo costo è la congestione dello Hot Storage. Un modello che nessuno usa può comunque occupare metadata, cronologia delle versioni, adapter, tracce di attribuzione, stato di hosting, e vari strati di dati necessari per l'inferenza. Non tutto dovrebbe essere mantenuto in uno stato caldo solo perché è stato lanciato. Se ogni modello viene trattato come un asset vivo, il sistema dovrà presto affrontare i costi di asset morti.
Il terzo costo è quello che considero più pericoloso: il rumore nell'Agent Routing.
Il futuro di OpenLedger non è solo utenti che scelgono manualmente modelli. Il progetto ha introdotto OctoClaw come un livello di agenti che possono costruire, automatizzare ed eseguire flussi di lavoro in tempo reale. Questo rende la questione dei modelli morti ancora più seria. Un agente non può operare basandosi su sensazioni. Deve chiamare modelli, scegliere adapter, accedere a dati, chiamare strumenti e decidere quali fonti sono affidabili in ogni contesto.
Quando l'ecosistema è inondato da un cimitero di modelli, attori come OctoClaw possono essere attratti da segnali fuorvianti: un adapter che un tempo aveva dati belli, un modello che aveva un'alta attribuzione ma la sua utilità è morta, una vecchia fonte di dati ancora nella hot path perché nessuno ha il coraggio di declassarla.
A quel punto, il problema non è più "questo modello non lo usa nessuno".
Il problema è che un modello morto può comunque intromettersi nel processo decisionale di un agente in esecuzione.
Quindi, se si dice semplicemente "crea un modello quando c'è abbastanza domanda", è ancora un po' blando. OpenLedger ha bisogno di un meccanismo più robusto per gestire il ciclo di vita economico dei modelli.
Un modello non dovrebbe avere solo una data di nascita. Deve avere una durata, un obbligo di mantenimento, un segnale di vita, e un meccanismo per auto-seppellirsi se non continua a generare valore.
Il modo di procedere potrebbe iniziare con lo staking.
Se una comunità crede che un modello specializzato abbia davvero domanda, non solo deve votare o contribuire con dati. Devono fare stake $OPEN su quella tesi. Lo stake qui non è solo denaro. È un impegno che questo modello merita di occupare spazio di archiviazione, attenzione al routing, sforzo di validazione e budget di ricompensa dell'ecosistema.
Dopo, i modelli devono dimostrare di essere vivi con dati di utilizzo reali: inferenze pagate, utilizzo ripetuto, retention dopo l'incentivo, completamento di task, validazione del dominio, e capacità di essere scelti nuovamente da sistemi come OctoClaw per l'efficacia reale e non per il rumore.
Se il modello funziona, staker e contributor vengono premiati. Se non funziona, lo stake viene slashing in parte. Il modello viene declassato nel routing, spostato in cold storage, o perde il diritto a ricompense ampliate per liberare risorse per agenti e flussi di lavoro che stanno ancora generando valore reale.
In parole povere: l'ecosistema OpenLedger ha bisogno di un modo per fare in modo che i modelli morti paghino per le loro stesse esequie.
Certo, questo meccanismo non è perfetto. Lo staking può mettere a rischio le idee più piccole, perché non hanno abbastanza capitale per dimostrare la domanda presto. Il slashing può rendere la comunità riluttante a sperimentare. Alcuni modelli specializzati con bassa utilizzo ma alto valore potrebbero essere valutati erroneamente se la metrica è troppo grezza.
Ma non avere una gestione del ciclo di vita è ancora più pericoloso.
Perché in quel caso OpenLedger potrebbe creare qualcosa che molte ecosistemi Web3 hanno già sperimentato: una città illuminata in superficie, ma all'interno piena di case abbandonate. Molti modelli. Molte attività. Molta attribuzione. Ma gli agenti non sanno a chi credere, i token vengono risucchiati per mantenere qualcosa che non è più vivo, e lo spazio di archiviazione diventa un magazzino di ricordi di esperimenti che nessuno ha il coraggio di cancellare.
Una blockchain AI non può semplicemente chiedere come generare più modelli.
Deve avere il coraggio di chiedere quali modelli dovrebbero essere mantenuti, quali dovrebbero essere declassati e quali dovrebbero morire.
Se @OpenLedger vuole diventare l'infrastruttura per veri modelli AI specializzati, questa è una domanda da cui non si può scappare: il progetto sta costruendo un'economia di modelli vivi, o sta finanziando un cimitero di modelli che sanno solo spendere token?