I'll be honest the more time I spend with OpenLedger's architecture, the more one idea keeps coming back to me.
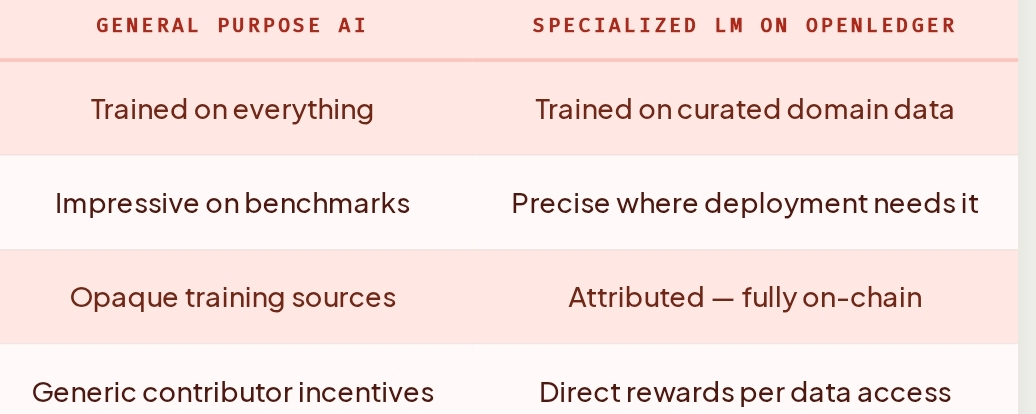
General purpose AI is impressive. But impressive and useful are not always the same thing.
I've been thinking about this for a while, watching how AI gets depl0yed in the real world versus how it gets discussed in research papers. The gap between the two is larger than most people admit. A model that performs brilliantly on benchmarks Can still fail consistently in a specific domain not because it is not powerful enough, but because power and precision are fundamentally different things.
OpenLedger is built around a different assumption. Instead of chasing scale, it optimizes for Specialization. Specialized Language Models SLMs are purpose built for specific domains. Smaller, more focused, trained on curated data with verified provenance. And in practice, they outperform general purpose giants on the tasks that actually matter within their domain.
What I find Genuinely compelling about this approach is what it does to the quality of the underlying data.
When contributors know their datasets are being used to train a specific, high value model and when they are compensated automatically every time that data gets accessed they approach contribution differently. A medical researcher building a clinical dataset for an SLM on OpenLedger has a direct financial reason to make that dataset accurate, well documented, and carefully curated. The incentive structure points toward quality in a way that centralized data collection simply cannot replicate.

The Auditability piece matters more than it first appears. An SLM trained on attributed, 0n chain data can tell you exactly what it learned from and why it behaves the way it does. For regulated industries healthcare, legal, financial services that traceability is not just a nice feature. It is increasingly what deployment actually requires.
What Open Ledger has built is an infrastructure where specialization and attribution work together. The models are more precise because the data is more intentional. The data is more intentional because the contributors are more invested. And the contributors are more invested because their work is visible, traceable, and economically meaningful.
That feedback loop is quiet. But it compounds in ways that matter over time.
I think the projects that will define AI's next chapter are not the ones with the biggest models. They are the ones that figured out how to make every layer of the system data, models, contributors, users genuinely aligned. OpenLedger is one of the few I have come across that seems to be building toward that alignment deliberately.
That is why I keep coming back to it.