Ecco una versione più umana, naturale e riflessiva — meno tecnica, più simile a una vera osservazione e curiosità:
A volte mi fermo e penso a questo per un momento… 🤔
Parliamo così tanto di proprietà dei dati, attribuzione dell'AI e ricompense giuste.
Ma stiamo davvero creando qualcosa di nuovo?
O stiamo solo trovando modi più intelligenti per affrontare un vecchio problema?
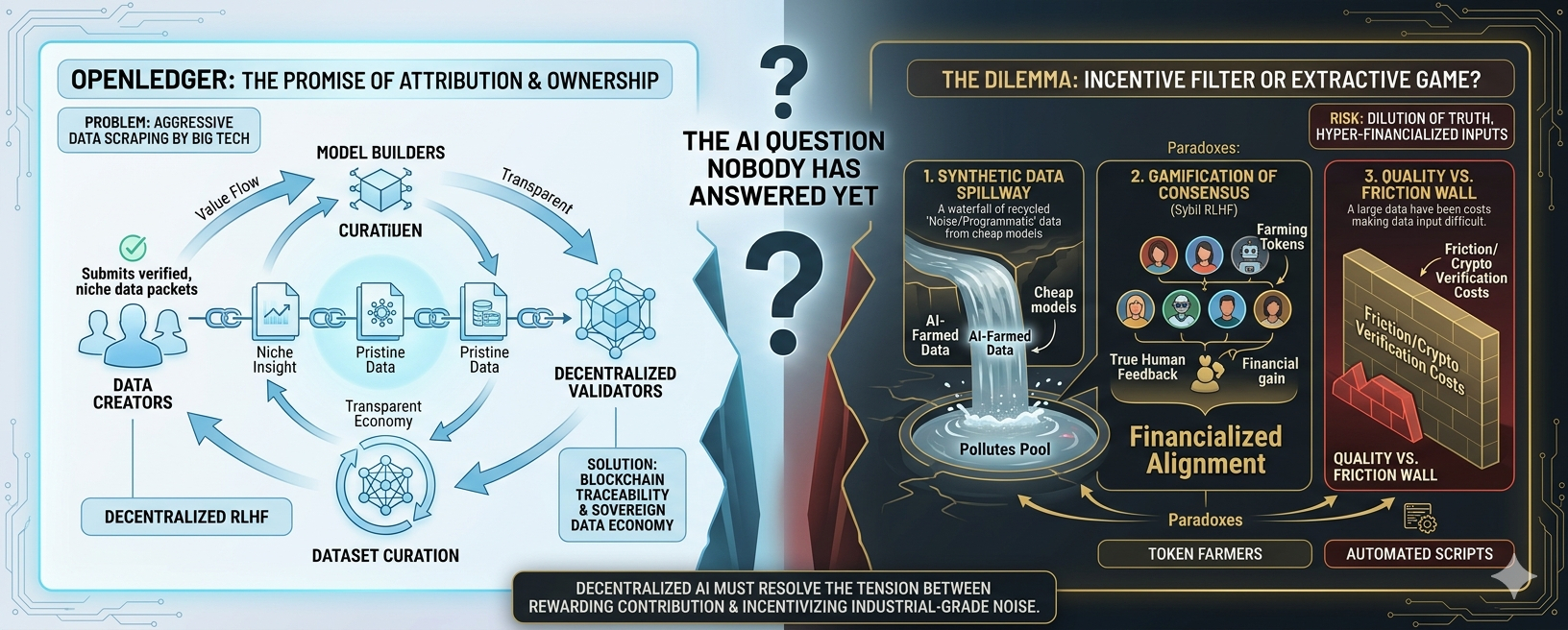
Questa domanda torna sempre a trovarmi quando guardo OpenLedger e l'idea dietro il Proof of Attribution (PoA).
Il concetto sembra semplice:
Se qualcuno contribuisce dati,
e quei dati aiutano a creare valore,
allora dovrebbero ricevere parte di quel valore.
Ha senso.
Ma poi inizio a pensare…
L'impatto dei dati può davvero essere misurato così chiaramente?
Un pezzo di dati può essere ignorato in un modello e diventare estremamente prezioso in un altro.
Quindi cosa stiamo esattamente premiando?
L'ammontare?
La qualità?
Il tempismo?
L'influenza reale?
Quello che rende OpenLedger interessante per me è che stanno almeno cercando di rendere tutto questo visibile.
Tracciare il contributo.
Verificare l'attività.
Misurare l'influenza continuamente.
Quasi come se l'IA funzionasse con telemetria live invece di assunzioni.
Ma c'è anche qualcosa di affascinante qui—
più un sistema diventa trasparente,
più gli incentivi diventano complicati.
Perché una volta che le ricompense entrano in gioco,
le persone smettono di pensare solo al contributo…
iniziano a ottimizzare per i risultati.
Forse è per questo che non vedo OpenLedger come una soluzione finita.
Lo vedo più come un esperimento in evoluzione.
Un luogo dove IA, blockchain e governance dei dati cercano di trovare un equilibrio insieme.
Non perfetto.
Non completo.
Solo qualcosa che viene costruito in pubblico.
E onestamente… forse è questo che rende interessante da seguire 🚀Title:
OpenLedger e la domanda a cui continuo a tornare