OpenLedger potrebbe stare costruendo la parte dell'economia AI che nessuno vuole veramente guardare a lungo.
La traccia dei soldi.
Non è la demo pulita. Non è l'interfaccia dell'agente con l'UI fluida e le grandi promesse. Non è un altro thread ordinato su come l'AI e le crypto finalmente si capiranno in questo ciclo. Ho visto abbastanza di quelle narrazioni riciclate fino a che non rimane altro che rumore. La maggior parte di esse inizia con un linguaggio enorme, attira attenzione, tira dentro liquidità, e poi lentamente si riduce al solito vecchio problema: nessuno può spiegare dove dovrebbe stabilirsi il vero valore.
OpenLedger sta almeno puntando a una vera ferita.
L'AI crea valore da molto lavoro invisibile. Dati. Modelli. Prompt. Ottimizzazione. Testing. Feedback. Lavoro comunitario. Giudizio umano. Tutto viene spinto nella macchina, mescolato, compresso e poi l'output finale esce pulito. Qualcuno lo monetizza. Qualcuno ottiene il guadagno.
La maggior parte dei contributori svanisce.
Quella è la parte a cui OpenLedger sembra tenere. Non in un modo carino "gli utenti possiedono i loro dati". Quella linea è stata battuta a morte. Intendo in un senso più duro e finanziario. Se l'AI crea qualcosa di valore, OpenLedger sta chiedendo chi ha realmente aiutato a crearla, come quel contributo viene tracciato e se le ricompense possono muoversi all'indietro attraverso il sistema invece di solo in alto verso la piattaforma che si trova sopra.
Suona noioso.
Buono.
Molte delle cose che contano davvero nel crypto suonano noiose prima di diventare ovvie. Regolamento. Indicizzazione. Instradamento della liquidità. Verifica. Progettazione degli incentivi. Nessuno vuole parlare della tubazione quando il mercato sta inseguendo qualsiasi cosa brillante che si è appena mossa del 40%. Ma la tubazione è di solito dove i progetti diventano infrastruttura o marciscono silenziosamente.
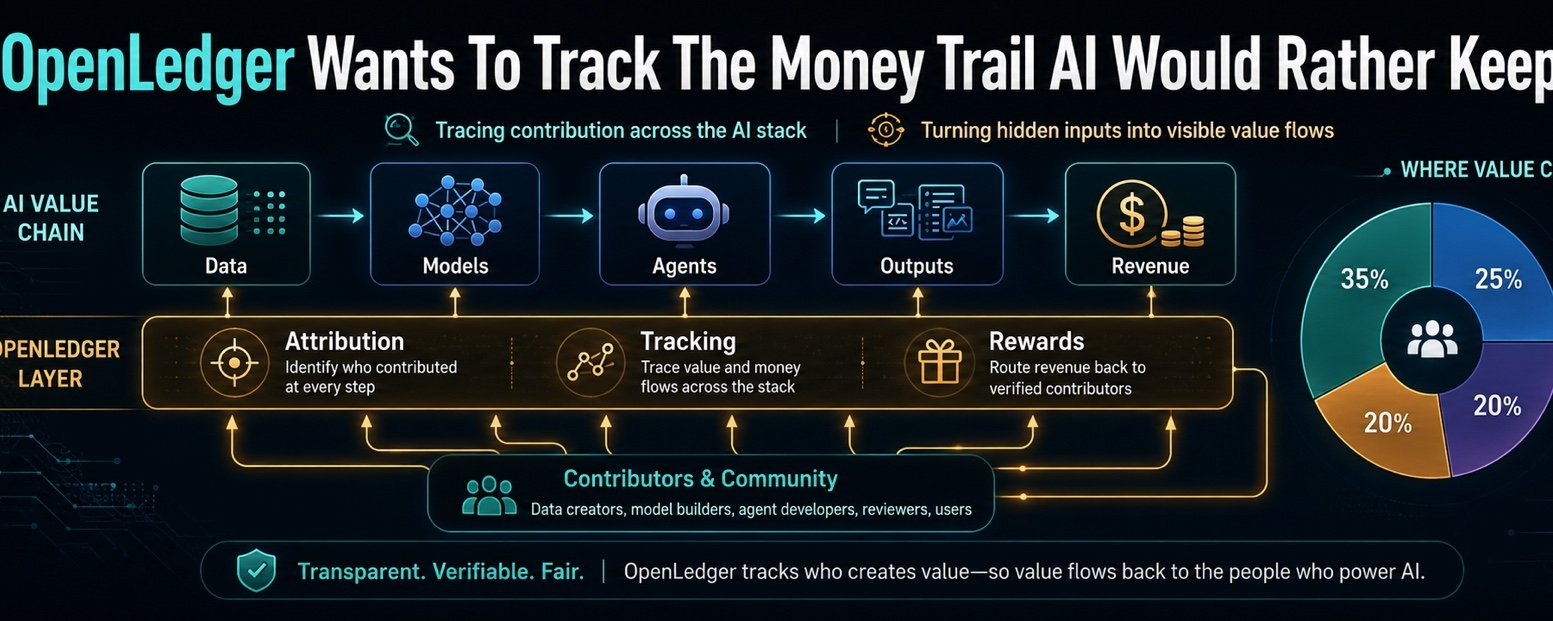
L'idea centrale di OpenLedger è l'attribuzione. Se un modello produce un output, o se un agente AI compie un'azione, il sistema dovrebbe essere in grado di registrare cosa ha contribuito a plasmare quel risultato. Quali dati contavano. Quale modello era coinvolto. Quale contributore ha aggiunto qualcosa di utile. Quale parte dello stack merita una quota se esce del denaro dall'altra parte.
Frase semplice. Problema brutale.
Perché l'AI non è pulita. Un output può essere influenzato da migliaia di input. Un'azione utile di un agente potrebbe dipendere da un dataset, un modello, un flusso di lavoro, una struttura di prompt, una chiamata a uno strumento e qualche lavoro umano precedente che nessuno ha valutato correttamente quando è entrato per la prima volta nel sistema. Una volta che inizi a chiedere chi merita credito, non ottieni equità immediatamente.
Ottieni attrito.
Ottieni discussioni.
Ottieni persone che fissano il tavolo dei pagamenti e si rendono conto che la macchina ha valutato il loro lavoro meno di quanto abbiano fatto loro.
È lì che comincio a prestare attenzione. Non perché OpenLedger abbia risolto tutto questo. Dubito che chiunque l'abbia fatto. Sto cercando il momento in cui questo si rompe realmente, perché è lì che il progetto diventa reale o viene esposto. L'attribuzione è facile da descrivere quando tutti sono ancora entusiasti. Diventa brutta quando le ricompense sono attive, i contributori non sono d'accordo e il sistema deve difendere i propri calcoli.
L'angolo dell'agente AI rende tutto più pesante.
Un normale modello AI ti dà una risposta. Un agente fa qualcosa. Quella piccola differenza crea molti problemi. Una volta che gli agenti iniziano a ricercare, creare, negoziare, automatizzare, spendere, instradare compiti e toccare l'attività on-chain, la domanda non è più solo "cosa ha generato questo?" Diventa "chi l'ha autorizzato, cosa ha usato, chi viene pagato e chi subisce il colpo se qualcosa va storto?"
Il crypto ama l'autonomia fino a quando l'autonomia crea responsabilità.
Ho visto questo schema prima. Il mercato si ubriaca prima sul concetto. Agenti autonomi, economie auto-gestite, lavoratori AI, pagamenti macchina a macchina, tutto ciò. Poi le domande noiose arrivano in ritardo e rovinano la festa. Permessi. Tracce di audit. Esecuzione scadente. Incentivi sbagliati. Sfruttamenti. Pressioni legali. Utenti che fingono di aver capito il rischio dopo il fatto.
OpenLedger è interessante perché è più vicino a quelle domande noiose che alla festa.
Sembra meno un progetto che cerca di rendere l'AI più cool e più un progetto che cerca di dare all'AI una memoria finanziaria. Un registro di ciò che è stato utilizzato. Un registro di chi ha contribuito. Un registro del perché le ricompense si sono mosse. Un registro di cosa ha fatto un agente prima che tutti inizino a discutere il risultato.
Non è una piccola cosa.
Ma ecco la cosa. Un buon problema non rende automaticamente un buon token. Il crypto continua a dimenticarlo, di solito di proposito. Un progetto può essere direzionalmente corretto e comunque essere un attivo terribile per lungo tempo. Forse per sempre. Il mercato non premia la complessità solo perché è reale. Premia il tempismo, la liquidità, le emissioni, l'attenzione e la chiara cattura di valore.
È lì che rimango cauto.
OpenLedger può costruire qualcosa di utile e ancora lottare se il token non è legato abbastanza strettamente alla domanda reale. Se l'uso avviene da qualche parte nello stack ma il token si trova solo vicino come un logo, allora i possessori stanno semplicemente scommettendo che il mercato sarà generoso in seguito. Ho visto quel trade. Di solito inizia con convinzione e finisce con persone che spiegano i programmi di sblocco su Telegram alle 3 del mattino.
La vera prova, però, non è se l'idea sembri importante. Lo è.
La prova è se OpenLedger può rendere l'attribuzione credibile quando il sistema ha veri soldi che fluiscono attraverso di esso. Non attività da dashboard. Non numeri di campagna. Non rumore morbido dell'ecosistema. Uso reale. Contributori reali. Controversie reali. Pagamenti reali per cui le persone si preoccupano abbastanza da combattere.
È allora che scopriamo di cosa si tratta.
Perché l'attribuzione non è una caratteristica morale pacifica. È un coltello. Taglia il valore e dice a tutti quale pezzo ricevono. Alcune persone si sentiranno viste. Altri si sentiranno derubati. Un sistema che afferma di premiare il contributo deve sopravvivere all'ira delle persone che pensano di essere state misurate male.
E forse questo è il costo nascosto della visione di OpenLedger.
Se funziona, non rende l'economia AI più fluida. Potrebbe renderla più onesta, che è diverso e probabilmente più doloroso. Porta il lavoro nascosto nel layer contabile. Rende la catena del valore meno sfocata. Trasforma il contributo vago in numeri. I numeri creano conflitti.
Tuttavia, l'alternativa è peggiore.
L'attuale economia AI si basa troppo comodamente su input invisibili. I dati entrano. Il lavoro umano entra. La conoscenza della comunità entra. L'output esce marchiato, monetizzato e rifinito. Tutti applaudono all'interfaccia mentre la storia di origine viene sepolta da qualche parte sotto i pesi del modello.
OpenLedger sta cercando di scavare in quel livello sepolto.
Non so se il mercato ha pazienza per questo. La maggior parte dei giorni, non ce l'ha. Il mercato vuole velocità, meme, liquidità e una ragione per credere che la prossima candela correggerà l'ultimo errore. L'infrastruttura richiede tempo. L'attribuzione richiede ancora più tempo. E i mercati dei token sono terribili nell'attendere a meno che non ci sia rendimento, hype o paura a tenerli in posizione.
Quella discrepanza sarà una lotta.
OpenLedger potrebbe essere in anticipo. Potrebbe essere troppo complicato per l'attenzione al dettaglio. Potrebbe costruire le ferrovie prima che abbastanza persone ammettano di averne bisogno. Potrebbe anche scoprire che i grandi attori dell'AI preferiscono contabilità privata, accordi sui dati privati e controllo privato su qualsiasi cosa aperta o tracciabile. Questo non mi shockerebbe. I più grandi attori raramente scelgono la trasparenza a meno che la pressione non li costringa a farlo.
Quindi non sto trattando OpenLedger come un vincitore pulito.
Lo sto trattando come una domanda seria avvolta in una struttura di mercato rischiosa.
La domanda seria è questa: se l'AI continua a generare valore da milioni di input invisibili, per quanto tempo l'industria può evitare di mostrare la ricevuta?
Perché alla fine qualcuno chiederà chi ha reso la macchina utile.
E forse la risposta scomoda è che nessuno vuole che il libro mastro venga aperto troppo presto.