Most people have experienced some version of this without naming it. You contribute something useful somewhere online, maybe an idea, a correction, a review, a photo, or even a small answer in a discussion thread, and later you realize the platform kept the value while your role became invisible. That pattern has existed for years. AI just makes it more noticeable because the scale is larger and the reuse is harder to track.
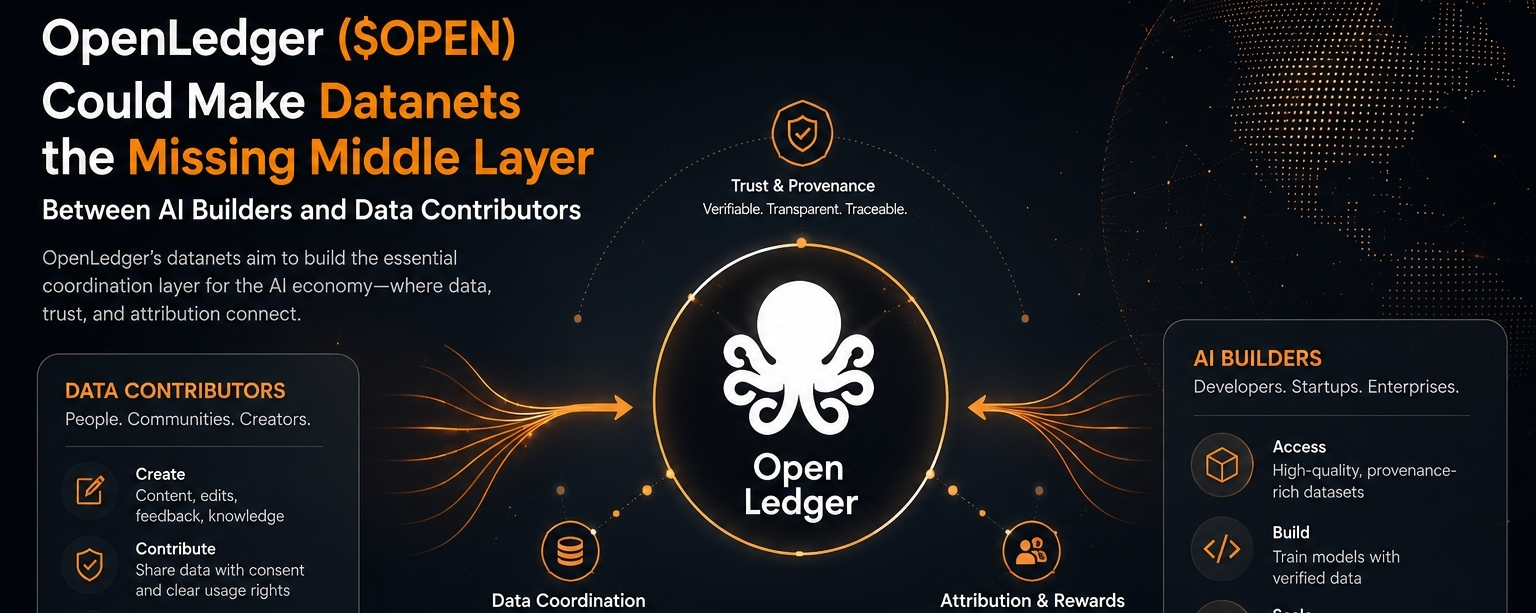
That is partly why OpenLedger’s framing around datanets is interesting to me. Not because “data marketplaces” are a new idea. They are not. We have seen many versions of that concept already, and most struggled because raw data alone is not the hard part. The harder part is coordination. Who contributed what. Whether the contribution was useful. Whether it was allowed to be used. Whether someone should be paid once, repeatedly, or not at all. That messy layer usually gets ignored because infrastructure discussions often focus on compute, meaning processing power, or model performance.
The idea of datanets, at least as it appears here, seems less about simply collecting datasets and more about building an operating layer between AI builders and contributors. That middle layer matters more than people think. AI developers need data, yes, but not just more data. They need data that can be traced, structured, updated, and trusted enough to use in systems where mistakes carry consequences. Contributors, meanwhile, need some reason to participate beyond vague promises.
That missing middle is where many AI systems quietly break.
A lot of people assume the relationship is simple. Builder needs data. Contributor provides data. Payment happens. Done. But reality is heavier. A single useful AI output may depend on thousands of fragmented contributions, edits, corrections, or behavioral signals gathered over time. Attribution becomes messy fast. Provenance, meaning proof of origin, becomes even messier. Once AI models absorb information, the boundaries blur. What exactly are you paying for? The raw input? The transformation? The later commercial use?
This is where OpenLedger’s structure starts to look less like a marketplace and more like coordination infrastructure.
I think that distinction matters because marketplaces solve matching problems. Coordination infrastructure solves trust problems. Those are not the same thing.
On platforms like Binance Square, this difference is easier to understand because visibility itself acts like a reward system. Mindshare rankings, dashboards, performance metrics, and AI-assisted content evaluation shape behavior whether people admit it or not. Creators adapt quickly. Some optimize for originality. Others optimize for speed. Some chase trending narratives because ranking systems reward relevance. Surface activity looks healthy, but the incentive layer underneath can become distorted. AI data ecosystems may face a similar problem. If contribution scoring becomes visible, people may optimize for what gets measured rather than what is actually useful.
That creates a strange tension.
A datanet that rewards quantity may attract noise. One that rewards complexity may become inaccessible. One that rewards only verified expertise may shrink participation too much. Designing incentive systems sounds neat in diagrams. In practice, human behavior turns them into something less predictable.
The token layer adds another complication. If $OPEN becomes part of this coordination system, then its role matters less as a speculative asset and more as an economic permission layer. That could mean access, settlement, contribution rewards, or validation costs depending on how the network evolves. But tokenized coordination systems often face a familiar problem. Early activity can look like genuine usage while actually being reward extraction.
Crypto has taught that lesson enough times.
What I find more interesting is whether datanets could create a different kind of AI relationship altogether. Right now, contributors often behave like disposable inputs. Data goes in, value moves elsewhere. A functioning middle layer could change that by making contribution stateful. Meaning your participation has memory, reputation, or future economic relevance rather than being treated as a one-time event.
That is a stronger idea than simple payment.
Still, memory systems introduce their own problems. Reputation layers can become rigid. Early participants may gain structural advantage. Gaming becomes inevitable. If rewards depend on contribution scoring, some actors will optimize for appearances instead of usefulness. We already see this in social systems. Why would AI coordination be cleaner?
There is also the question of whether AI builders actually want this extra layer.
Speed often beats elegance in technology adoption. If direct private data sourcing remains faster, cheaper, and legally simpler, then a coordination-heavy middle layer may feel like unnecessary friction. Builders say they care about trust until trust slows shipping schedules. That is not cynicism. Just observed behavior.
Then again, regulation and accountability may change those incentives. When AI outputs begin affecting money, identity, compliance, or autonomous decision-making, provenance stops being philosophical. It becomes operational. Knowing where information came from may matter less for curiosity and more for liability.
That changes the economics.
The independent thought I keep returning to is this: OpenLedger may not be trying to make data more valuable. It may be trying to make unstructured contribution less acceptable.
That sounds subtle, but the distinction matters. AI already has plenty of information. Abundance is not the issue. Coordination is.
If datanets become useful, it may not be because they created a better market for data. It may be because they created a system where contributors, builders, and validators can finally interact without pretending trust exists by default.
And even then, I am not sure the clean version survives contact with incentives. Systems built to organize contribution have a habit of eventually teaching people how to perform contribution instead.