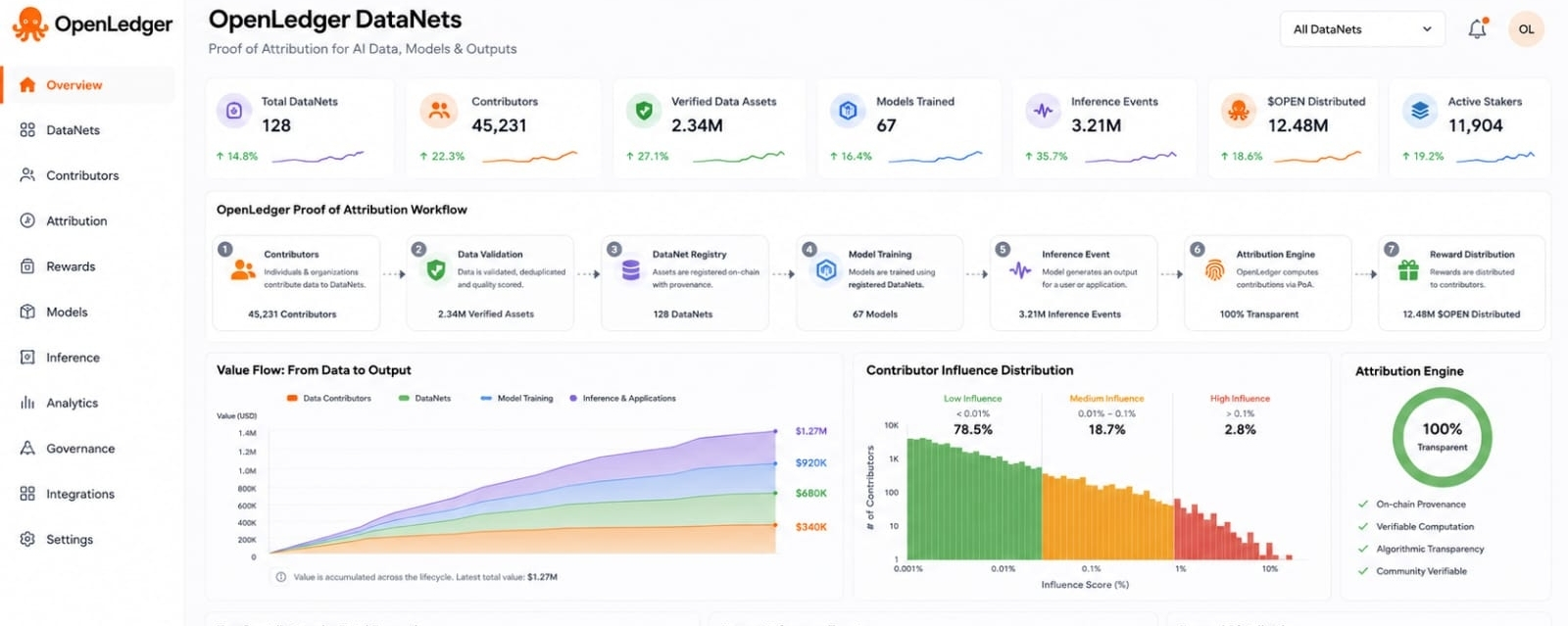
I keep seeing OpenLedger as a project built around one quiet but important shift in AI. My view is that the next stage of AI will not only be about faster models or larger models. It will also be about proving where useful intelligence comes from and giving the right people a visible place in that value chain.
That is why OpenLedger feels interesting to me. It is not trying to describe data as a vague resource that sits behind a model. It treats data as something with history ownership influence and economic weight. The project builds around Proof of Attribution which is the idea that a model output should be traceable back to the data that helped shape it. In plain terms OpenLedger is asking whether an AI answer can carry a reliable record of its origins.
The problem it is trying to solve is easy to recognize. Most AI systems depend on large amounts of data. That data may come from people communities institutions open sources or specialist contributors. Once it is absorbed into a model it usually becomes invisible. The model may become useful. The platform may capture value. The contributor may receive nothing. This creates a weak incentive for people who have strong domain knowledge to share clean and useful data. OpenLedger is trying to make that relationship less one sided.
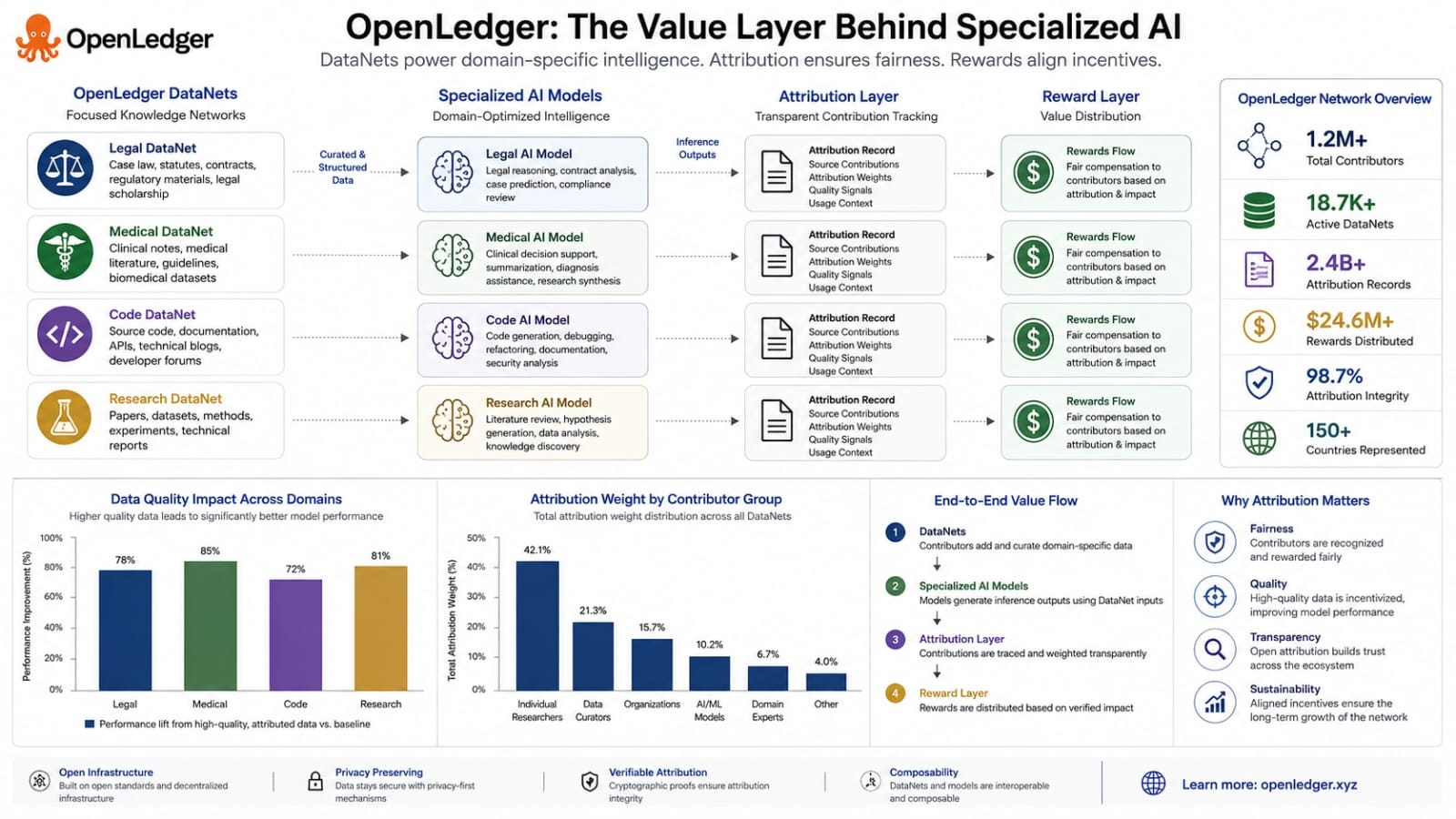
Its core building block is the DataNet. I find this idea practical because it does not treat all data as one giant pile. A DataNet is focused around a domain or task. It can be built for legal contracts. It can be built for medical notes. It can be built for code examples. It can be built for specific question and answer material. The point is that specialized AI needs specialized data and that data becomes more useful when it is structured with provenance from the beginning.
This is where the project becomes more than a storage idea. OpenLedger wants data to be attribution ready before it ever influences a model. When a contributor adds data to a DataNet the contribution can carry metadata such as identity timestamp license status processing history and quality signals. That record matters because the system later needs to know what data was used and how it influenced training or inference. Without that foundation the reward layer would be difficult to trust.

The most important part of the thesis is inference level attribution. I used to think data attribution mostly mattered during training. OpenLedger pushes the question further. What happens when a model is actually used. What happens when someone asks a question and the model produces an answer. If the system can connect that answer back to certain DataNets or data points then reward can be tied to use instead of only upload activity. That changes the logic. A contributor is not only paid for adding data. A contributor may benefit when that data keeps proving useful.
That idea has real market relevance because AI is becoming more specific. Broad models still matter but many serious use cases need narrower systems that understand a field with care. A financial research model needs credible market data. A healthcare assistant needs carefully handled medical information. A developer tool needs strong code examples and reliable documentation. In each case the quality of the dataset may matter as much as the model architecture. OpenLedger is trying to make that quality visible and economically meaningful.
There is also a trust angle that should not be missed. If a model gives an answer in a sensitive field the user may want more than confidence. They may want traceability. They may want to know whether the model was influenced by reliable data or weak data. They may want audit records. They may want licensing clarity. OpenLedger frames this through onchain provenance. The chain is not there only as branding. It is there to create a shared record that can be checked by contributors builders and users.
Still I would not treat the idea as easy. Attribution is hard. A model does not always behave like a simple machine where one answer can be traced to one clean source. Influence can be spread across many data points. Some outputs may be shaped by general patterns rather than direct memory. Some data may be duplicated across different sources. Some contributors may try to game the reward system with low quality material. OpenLedger has to manage all of that if the attribution economy is going to feel credible.
The white paper tries to handle this by using different attribution approaches for different model types. Smaller specialized models can use influence based methods that estimate how training data affects predictions. Larger language models can use token based matching against compressed training data structures to detect relevant spans. I think that flexibility is important because a single attribution method would likely be too rigid. The risk is that users may still need simple explanations. If the system becomes too technical or opaque then the trust benefit becomes harder to feel.
The strongest version of OpenLedger is not one where every contributor simply earns because they uploaded something. The strongest version is one where better data earns more because it creates measurable model value. That is a more disciplined idea. It rewards relevance. It rewards quality. It rewards data that continues to matter during real use. If OpenLedger can make that loop work then DataNets could become living markets for useful knowledge rather than static databases.
For builders the appeal is different. A developer may care about finding high quality specialized datasets with clear provenance. A team may want to train a model and show which DataNets shaped it. An enterprise may care about audit trails and licensing records. A contributor may care about whether their knowledge can generate ongoing rewards. Each participant enters for a different reason yet the system depends on all of them caring about the same thing. Reliable attribution.
In the short term the project has to prove usability. Contributors need to understand how their data is registered. Model builders need to see that DataNets improve training or fine tuning. Users need to see that attribution records are not just technical decoration. The reward system also has to feel meaningful without becoming noisy or easily manipulated. These are practical tests rather than narrative tests.
The long term question is larger. If AI becomes a normal part of work then the hidden labor behind AI will become harder to ignore. People will ask who produced the data. They will ask whether the data was licensed. They will ask whether contributors were paid. They will ask whether outputs can be audited. OpenLedger is positioning itself around that future. It is building for a world where AI value needs a receipt.
My own thesis is that OpenLedger becomes most relevant if specialized AI continues to grow and if provenance becomes a serious requirement rather than a nice feature. The project does not need to prove that every AI output can be perfectly explained. It needs to prove that useful attribution can become reliable enough for rewards trust and model accountability. That is a difficult standard but it is also a meaningful one.
What I like about the idea is that it changes the emotional center of AI infrastructure. Instead of seeing data contributors as background suppliers it makes them part of the system itself. Instead of seeing model outputs as isolated events it treats them as the visible end of a longer value trail. OpenLedger is creative because it gives that trail a structure. It is professional because it connects the structure to incentives and verification. It is relevant because AI is moving toward a world where data quality trust and ownership may matter as much as raw model power.
@OpenLedger #OpenLedger $OPEN $BEAT
