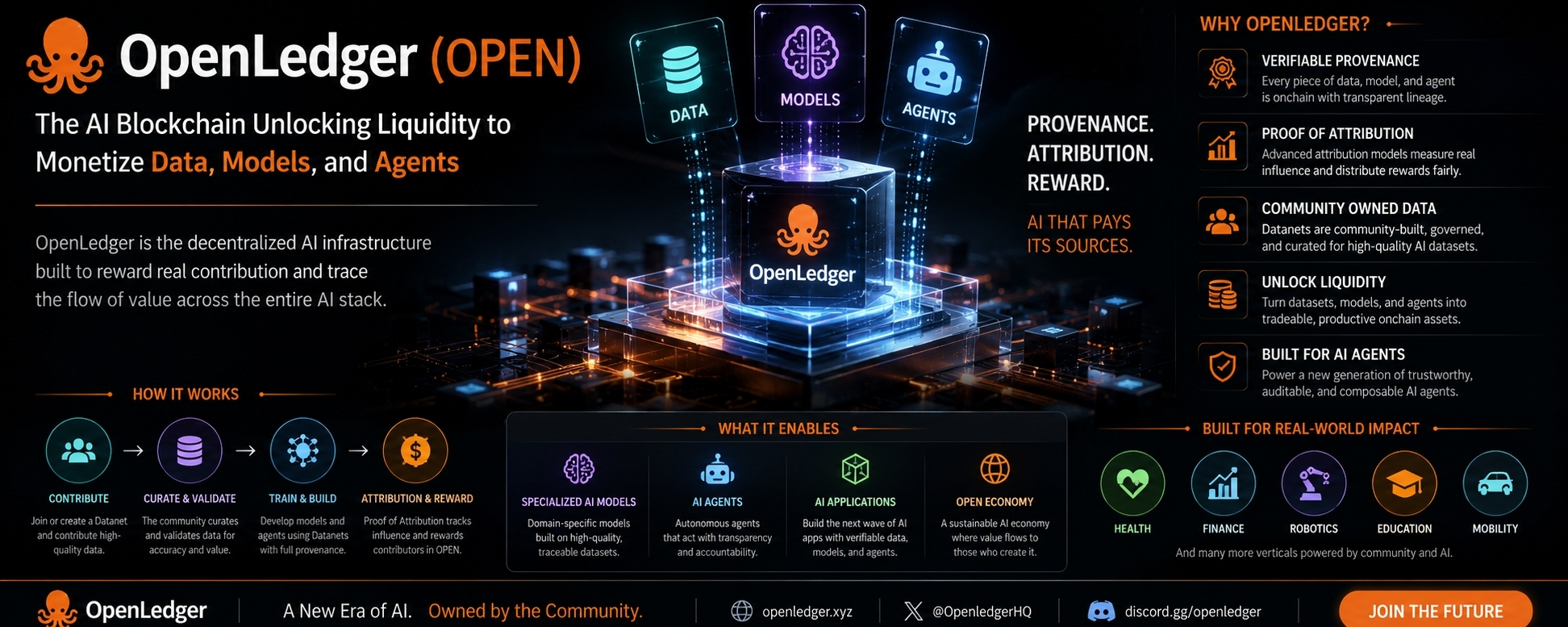
OpenLedger is one of those projects that makes more sense the longer you sit with it. At first glance, the idea sounds technical: an AI blockchain that lets people monetize data, models, and agents. But underneath that language is a much simpler question. If AI is built on human work, why does so much of that work disappear the moment the system starts producing results? OpenLedger is trying to answer that in a more practical way than most projects do. It wants contribution to stay visible, and it wants value to follow that contribution instead of drifting away from it.
That is what makes the project feel a little different. It is not just trying to attach itself to the AI conversation. It is trying to correct something that already feels off about the way AI usually works. Data gets collected, models get trained, outputs get sold or used, and the people behind the original inputs are rarely part of the story anymore. OpenLedger’s whole structure pushes against that habit. It treats data, models, and agents as things that should have provenance, credit, and a clear path for reward.
The Datanet idea is where this starts to feel real. Instead of treating data as a static pile of information, OpenLedger describes Datanets as community-owned collaboration networks. That matters because good data is rarely random. It is usually shaped by people who know the context, the domain, and the difference between useful and useless detail. Framed that way, a Datanet feels less like a database and more like a living shared asset. It can grow, improve, and become more valuable as the right people contribute to it.
The interesting part is that OpenLedger does not lean on vague talk here. Its Proof of Attribution work is trying to make contribution measurable. The paper says the goal is to measure how data affects model inference and reward it accordingly, using different attribution methods for different model sizes. That sounds technical, but the idea behind it is easy to understand: if something helped train or shape a system, that help should not vanish into the background. It should count for something.
That may sound like a small change, but it is actually a big one. A lot of the AI world still runs on hidden labor. The output is visible, polished, and easy to market. The input side is much messier, and usually much less appreciated. OpenLedger is trying to build a system where that imbalance is harder to ignore. If people can trace what they contributed and see that contribution reflected in a real way, the whole model starts to feel more honest.
There is also a more grounded reason the project stands out: it seems to understand where AI is actually heading. The most useful systems are not always the biggest ones. They are often the ones built for a narrow job, with strong data behind them and clear limits around what they are supposed to do. OpenLedger’s ecosystem points in that direction, with an emphasis on verticals like health, finance, robotics, education, and mobility. That is a sensible direction. It suggests the project is thinking about real use, not just broad ambition.
The same logic applies to agents. Once AI starts acting instead of merely answering, trust becomes much more important. You need to know where the system came from, what shaped it, and whether its behavior can be traced back to something reliable. OpenLedger’s framing suggests that provenance is not an optional extra in that world. It is part of the foundation. That makes the project feel less like a slogan and more like a response to a real problem that AI systems are already creating.
None of this means the path will be easy. Projects like this always run into the hard part eventually: getting people to participate, making the incentives hold up, and proving that the system works outside of a neat explanation. OpenLedger still has to show that contributors will care, builders will use it, and the reward structure will make sense when things get messy. Those are not small questions. They are the questions that decide whether a project becomes useful infrastructure or stays an interesting idea.
Even so, there is something refreshing about the way it is being framed. The project is not claiming to solve everything. It is not trying to sound bigger than it is. It is making a narrower case: if AI is going to keep depending on human-created data, then the system should stop pretending that data has no history. That is a fair argument, and probably a necessary one. OpenLedger is basically saying that intelligence should not erase its own source material. It should remember it, value it, and make room for the people who helped build it.
And the fact that the network appears live adds a little more weight to that claim. OpenLedger’s status page shows mainnet services as operational as of May 22, 2026, which means this is not being presented as a far-off concept. It is already running, already maintained, and already being positioned as something that can support real use. That does not guarantee success, but it does make the project feel more concrete than a lot of AI-blockchain narratives out there.
At its best, OpenLedger feels like a quieter kind of ambition. Not loud, not overstyled, not pretending to reinvent the whole world in one move. Just a straightforward attempt to give AI a better memory of where value comes from. That is a modest-sounding goal, but it is also the kind of idea that can matter a lot if it is done well.
