A user gets screened out.
The trace on @OpenLedger says the rule was followed.
Great.
Now try telling the person who got routed lower, delayed, rejected, or priced worse that this should make them feel better.
That is the version of OpenLedger that keeps bothering me. Not whether the AI path executed cleanly. Datanets feeding inputs, models or adapters using them, agents producing outputs, traces showing how the decision got made. Good. Useful. Real problem.
The uglier part starts after the system does exactly what it was told.
Because tracing that a scoring rule was followed is not the same thing as proving that scoring weight deserved to control the route in the first place.
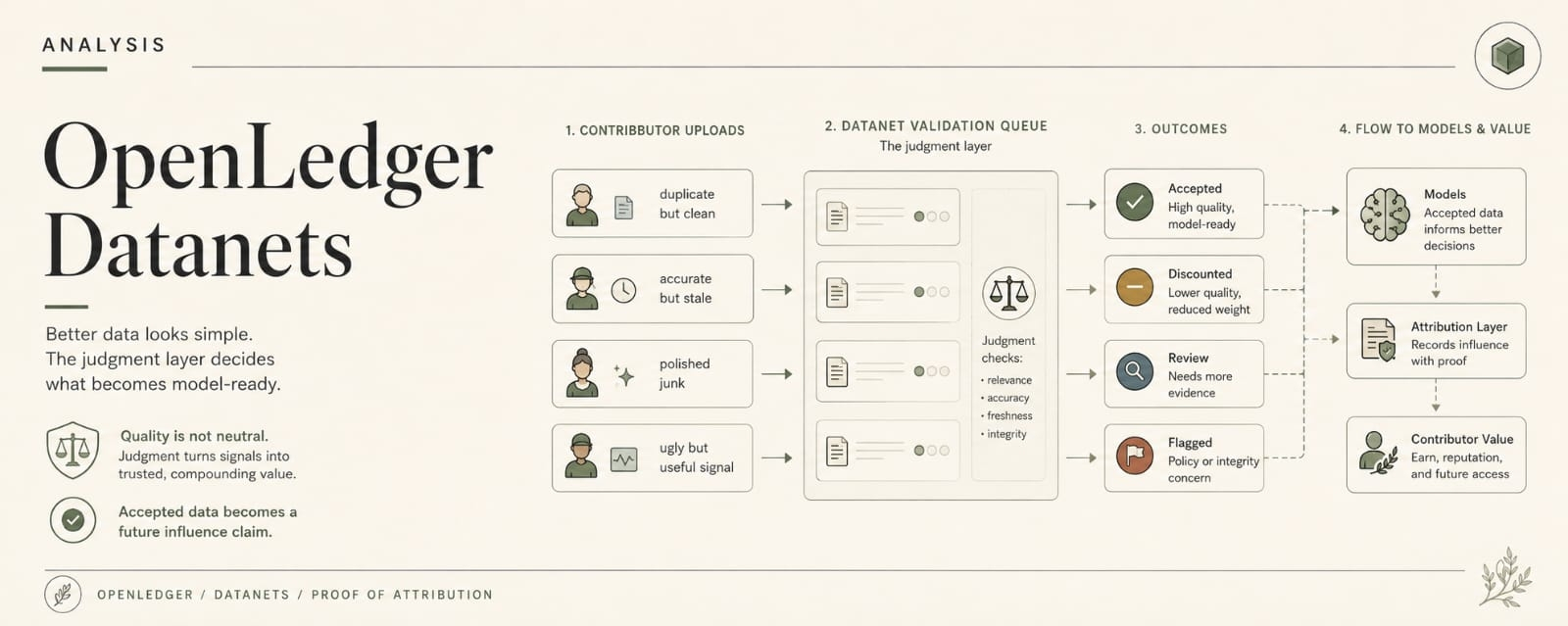
Take an OpenLedger-backed agent workflow. Maybe a trading agent ranks signals before execution. Maybe a marketplace agent scores which model response deserves routing. Maybe a research workflow downranks a source because of some quality weight. Maybe an allocation path only opens once a confidence threshold gets met.
Fine.
One Datanet signal gets a lower source-quality weight. An OpenLoRA adapter still uses it. The agent doesn’t reject the output. It just routes it lower, delays it, or keeps it out of the execution lane. Beautiful little punishment nobody wants to call punishment.
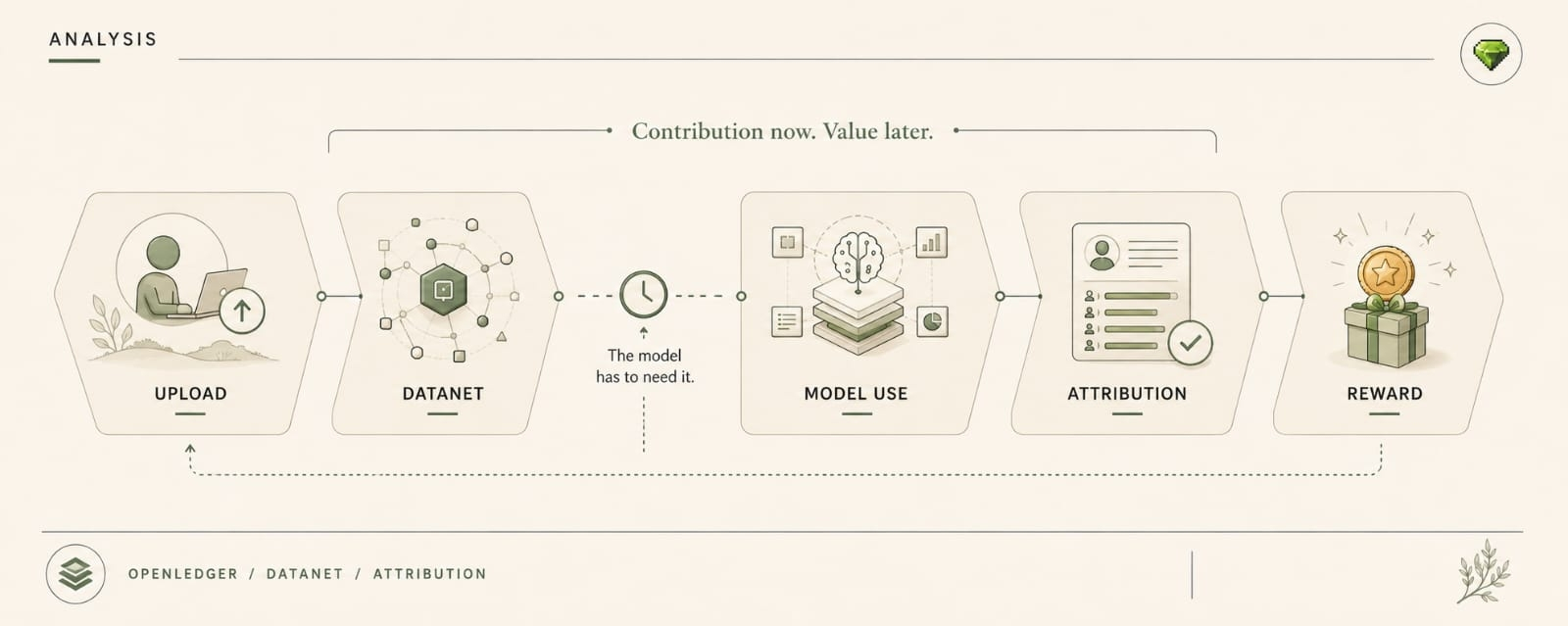
The data path stays legible. The model path can be traced. The agent applies the rule it was given.
Great.
Perfect even.
Now the outcome hits someone real.
They get denied.
Or delayed.
Or routed lower.
Or priced worse.
Or sent into review while another output clears cleanly.
And when they ask why, the answer starts sounding thin very quickly.
Not the system failed.
Worse.
The system worked as designed.
That is where it gets irritating.
Because bad calibration enforced cleanly is still bad calibration. A narrow confidence threshold is still narrow. A dumb weighting is still dumb. A rule that overreacts to one risk signal, or quietly favors one data profile over another, or encodes some internal panic that made sense to the people writing it but feels ridiculous to the people living under it, does not become wise because OpenLedger can trace the path.
It just becomes harder to argue with from the outside.
I've seen enough systems hide behind a clean queue to know how this goes.
That is where it starts smelling bad.
On OpenLedger, ModelFactory can package the workflow correctly. The Datanet source can be valid. OpenLoRA can serve the adapter cleanly. The trace can show the path. None of that tells the user why this scoring weight still gets to decide the queue.
That is the appeal.
It also means bad calibration can hide behind very clean execution.
OpenLedger can show that the agent followed the path.
It can’t prove the scoring rule still deserved that authority.
Sometimes it is not even some grand bias. Worse, honestly. A threshold gets nudged upward after one ugly week. A risk weight meant for edge cases stays in the system because nobody wants to be the person who removes it. I have watched that one survive way past the incident that justified it. A source-quality penalty that made sense during stress quietly becomes permanent model logic.
On OpenLedger that can all stay traceable and still execute perfectly.
That is the ugly little trap.
People hear traceable and relax. Model followed the rule. Agent path intact. Great. But the trace does not tell you whether the rule was fair. Or prudent. Or proportionate. Or calibrated for reality instead of for the internal anxieties of the team that wrote it.
And teams do this all the time. Quietly. A temporary source-quality penalty becomes the default Datanet weight. A confidence threshold raised after a bad trading week keeps governing normal agent runs. An adapter-specific caution quietly becomes marketplace routing logic, and suddenly the workflow is technically clean and substantively rotten.
OpenLedger does not create that tendency.
It just makes it easier to execute, trace, and defend neatly.
That matters more than people like pretending it does.
Because once the rule sits inside an agent workflow, the public fight shifts. Now it is not did the agent apply the rule. Maybe it did. Now the fight is whether the scoring rule itself deserves trust, and that is a much uglier argument when the people outside the system can inspect the path but still cannot tell where prudence ends and institutional paranoia begins.
A product team says the policy worked exactly as intended.
A user says the outcome makes no sense.
A trader says the signal got ranked wrong.
Risk says the threshold is prudent.
Ops, as usual, gets a queue full of people asking for reasons nobody can really give without either exposing too much of the model logic or retreating into the criteria were met.
Nobody really hears that as an answer.
The damage rarely looks dramatic either. That is the annoying part. A clean output gets routed second-tier. A trading signal gets sized down. A marketplace answer loses priority. A contributor’s data still traces, but the agent treats the signal like it came with a warning label.
So no, I do not think OpenLedger’s hard question is just whether AI decisions can be traced cleanly.
They can.
The harder one is what happens when the scoring rule is the thing people no longer trust, and the trace just keeps certifying that the bad rule was applied faithfully.
By then the trace is clean.
The agent acted.
The user still thinks the outcome is nonsense.
And the whole workflow is left defending the fact that a Datanet-fed, adapter-served, traceable agent route punished someone exactly the way it was configured to.