Getting Restructured Out Has No Idea OpenLedger Exists Yet
I have watched the data labeling industry for long enough to have genuine opinions about how badly it has failed the people who make it function. The current model for sourcing human intelligence to train AI systems runs through intermediary platforms that recruit workers in lower-income markets pay them rates that would not survive scrutiny in the countries where the AI products they are training get sold and maintain no persistent record of the expertise those workers demonstrate over years of quality contributions. The workers are disposable by design. The platforms extract the margin. The AI labs get the data. And the people who actually did the cognitive work that made the model useful have nothing to show for it that transfers to the next project or the next employer or the next platform that decides to cut rates.
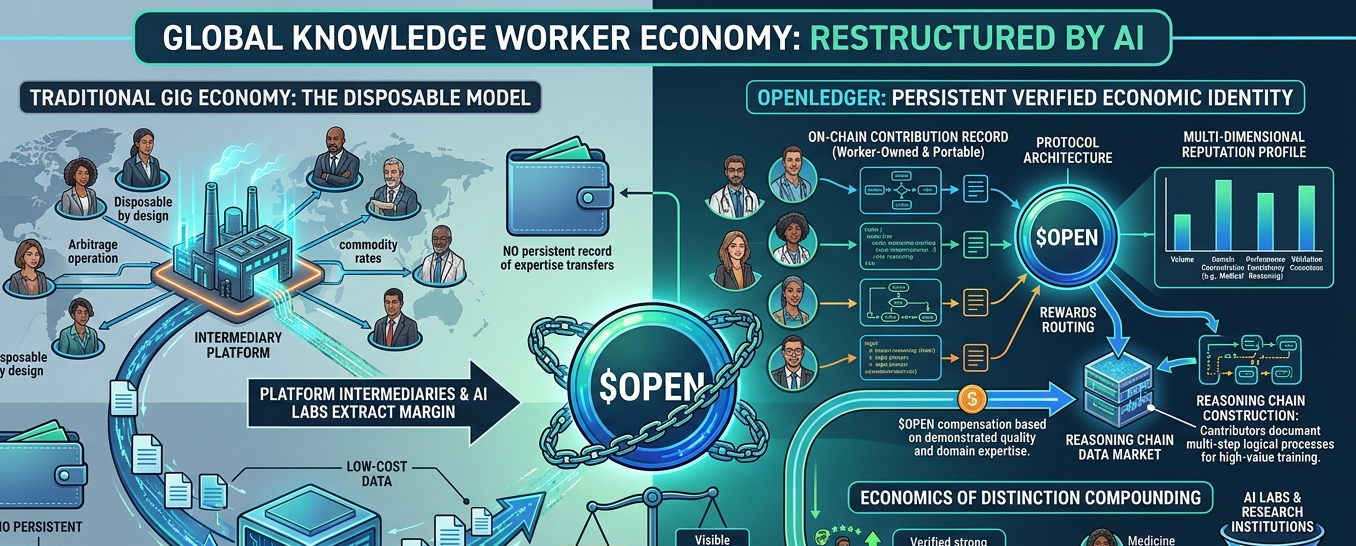
This is the labor economics context I bring to every analysis of what @OpenLedger is building and I think it produces a different read on the protocol value than you get from a purely technical or tokenomic lens. open is not just a mechanism for distributing rewards to data contributors. Its the first serious attempt I have seen at creating a persistent verifiable economic identity for knowledge workers in the AI training supply chain. The on-chain contribution record that a worker builds inside the OpenLedger protocol is owned by that worker not by the platform intermediary that contracted them and it travels with them across every interaction they have within the ecosystem. That portability is not a feature footnote it is a structural departure from every existing model for compensating human intelligence in AI development.
The technical implementation of contributor identity in OpenLedger matters here and I want to be specific about why. Most decentralized reward systems create wallet addresses that accumulate token balances and call that a contributor identity. What OpenLedger is building is more granular than that. The contributor profile aggregates quality scores across multiple submission dimensions over time creating a multidimensional reputation record that captures not just total contribution volume but performance consistency domain concentration and validation consensus rates across specific knowledge categories. That multidimensional record is what distinguishes a contributor who has genuinely mastered a domain from one who has submitted a high volume of mediocre work and the distinction matters enormously to an AI developer trying to source reliable expertise for a specialized training task.
And the economics of that distinction compound in ways that I find genuinely interesting. A contributor who has built strong verified domain reputation inside the OpenLedger protocol doesnt just earn higher rewards on current submissions. They become a preferred fulfillment source when data request contracts arrive for their domain specialty meaning they get first access to higher-value work that pays premium rates. That compounding access mechanism creates real career trajectory inside the protocol for contributors who invest in quality over volume and thats a fundamentally different economic incentive structure than the flat-rate per-task model that dominates every existing data labeling platform. Im not romanticizing this. Its still contingent on token value and network demand. But the structural design is more honest about the relationship between expertise and compensation than anything else currently operating at scale.
My hot take about the gig economy for AI data work is something I have not seen written plainly anywhere. The platforms currently dominating this space are essentially running a sophisticated arbitrage operation where they charge AI labs premium rates for labeled data while paying contributors commodity rates for the labor that produces it and the opacity of that arbitrage is intentional because transparency would reveal margins that no contributor would accept voluntarily if they understood the full picture. OpenLedger makes the economics of that transaction visible on-chain and that visibility is not just philosophically appealing it is structurally corrosive to the intermediary model because it removes the information asymmetry that makes the arbitrage possible in the first place.
But I want to be precise about where the protocol sits technically on the question of task complexity because this determines which segment of the knowledge worker market it can realistically serve in the near term. The contribution types that OpenLedger currently supports range from structured factual data submissions through preference annotation tasks to more complex reasoning chain construction where contributors document multi-step logical processes that serve as training signal for model reasoning capabilities. That complexity range matters because the economics are very different at each level. Simple factual submissions can be produced at volume by contributors with modest domain knowledge. Reasoning chain construction requires contributors who can actually demonstrate the cognitive process being documented and those contributors command significantly higher market rates than generalist annotators in conventional data labeling pipelines.
The reasoning chain data market is where I think $OPEN has its most defensible commercial position and I dont see this discussed with the seriousness it deserves. Modern large language model development is increasingly dependent on high-quality chain of thought training data where human experts document not just answers but the reasoning processes that produce those answers in domains where the reasoning process itself is what the model needs to learn. Sourcing that data through conventional labeling platforms is expensive slow and produces inconsistent quality because the platforms lack any mechanism for verifying that contributors actually possess the domain expertise required to document genuine expert reasoning rather than a plausible-sounding imitation of it. A contributor network where domain expertise is verifiable through accumulated on-chain performance history is a structurally superior sourcing mechanism for exactly this category of high-value training data.
The federation potential of the OpenLedger contributor network is an angle I have been thinking about and havent seen analyzed anywhere. As the protocol scales across contributor geographies and knowledge domains it is implicitly building a distributed network of verified subject matter expertise that no centralized organization could staff or maintain. A research institution trying to source expert annotation for a highly specialized scientific domain doesnt just get a dataset from @OpenLedger it gets access to a contributor pool with documented performance histories in that domain and the ability to route future requests to the specific contributors whose track record most closely matches their quality requirements. Thats closer to how expert consulting networks operate than how data labeling platforms operate and the pricing power that comes with genuine expertise verification is substantially higher than commodity annotation rates.
What I think gets almost completely ignored in retail discussions of $OPEN is the intellectual property dimension of what contributors are actually transferring when they submit to the protocol. The current legal framework for training data rights is genuinely unsettled and litigation in multiple jurisdictions is actively testing the boundaries of what AI labs can use without explicit contributor consent and compensation. OpenLedger creates a documented consent and compensation record for every submission which is exactly the kind of evidence that a contributor would need to demonstrate authorized commercial use of their knowledge contributions if the legal environment shifts in ways that create liability for AI developers who cannot document contributor consent. Im not making a legal prediction. Im noting that the protocol architecture creates a compliance paper trail that has value independent of its technical data quality functions.
I will close with the observation that keeps pulling my attention back to this project. The knowledge worker problem in AI is not a peripheral issue it is a central structural challenge that the industry has been ignoring because ignoring it has been economically convenient for the organizations with the most influence over how the industry describes itself. When that convenience expires whether through regulation litigation or the simple market pressure of diminishing returns from low-quality unlicensed data the infrastructure that was quietly building a better model will matter more than anything currently generating more headlines.