

OpenLedger: Is This Actually Different?
I’ll be honest I rolled my eyes when I first heard about OpenLedger. Another “AI meets blockchain” project. Another white paper full of buzzwords dressed up as innovation. I’ve seen enough of those to know the pattern: decentralized this, autonomous that, a token in the middle, and somehow it’s all worth a billion dollars before a single real user shows up.
So I almost didn’t look deeper. I’m glad I did.
Because buried underneath the jargon is a problem that’s genuinely worth solving and one that barely gets talked about in mainstream AI discourse. Every time you use ChatGPT, Claude, Gemini, or any major AI product, you’re interacting with something that was built on an enormous amount of human-generated content. Books, articles, forum posts, code, medical notes, creative writing — scraped, processed, and fed into training pipelines. The people who created that content? They got nothing. The companies that built on it? They’re now worth hundreds of billions of dollars.
That’s the structural problem OpenLedger is actually trying to address.
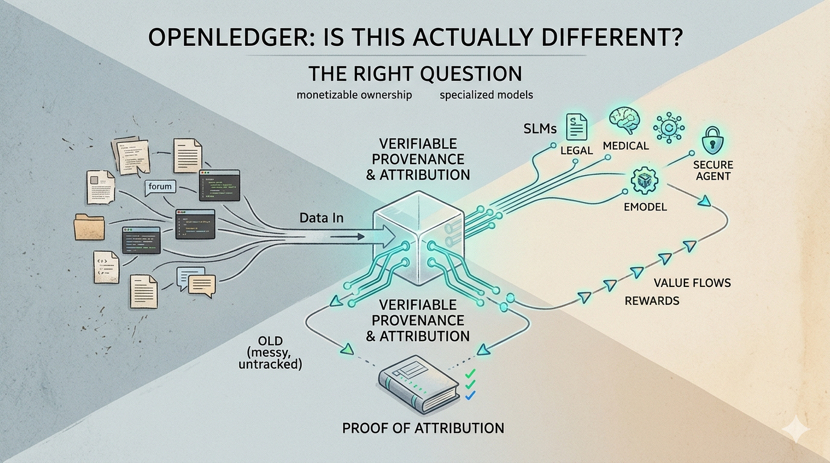
Their core argument is straightforward: if data is the raw material of AI, then data contributors should be treated like suppliers, not free resources. The value chain in AI data in, model out, company profits should be more transparent and more equitably distributed. OpenLedger wants to rebuild that chain on-chain, where contributions are tracked and rewards flow back to the people who made the whole thing possible.
Whether that’s achievable is a different question. But at least it’s the right question.
The technical piece they’ve built around this is called Proof of Attribution. Think of it less like a blockchain consensus mechanism and more like a receipts system for AI training. It records which datasets influenced which models, who contributed what, and how value generated downstream should be allocated back up the chain. If it works the way they describe, it would essentially turn AI training from a black box into something auditable a verifiable record of where a model’s capabilities actually came from.
That’s more ambitious than it sounds. Anyone who’s spent time around ML infrastructure knows how messy data provenance gets even inside a single organization. Doing it at a decentralized scale, across contributors who don’t know each other, with financial stakes attached that’s a genuinely hard engineering and incentives problem.
The rest of their architecture is worth understanding in context. Rather than chasing the “one model to rule them all” approach that dominates the big labs, OpenLedger is oriented around specialized models what they’re calling SLMs, or Specialized Language Models. A focused model trained on verified legal documents or clinical trial data can outperform a general-purpose model on narrow tasks, and it’s cheaper to run. The infrastructure they’re building Datanets for community-owned datasets, ModelFactory for training and deployment, OpenLoRA for lightweight fine-tuning is all designed to support that kind of niche AI economy rather than trying to compete with GPT-4.
There’s also a real-time data access layer through RAG and MCP integrations, which keeps model interactions auditable. And they’re thinking ahead to AI agents systems that can autonomously transact, consume data, and generate revenue on-chain. That’s still more vision than product, but the underlying direction makes sense if you believe AI agents will eventually operate more like economic actors than software features.
The broader context here matters too. A few years ago, blockchain projects tended to optimize for one thing: Ethereum for programmability, Solana for speed, Bitcoin for security and simplicity. OpenLedger is making the case that what AI infrastructure needs is something none of those chains were designed for a way to track and enforce ownership of model contributions at scale. Projects like Bittensor are going after this from a model competition angle.
NEAR has been building toward verifiable AI infrastructure. OpenLedger’s specific bet is on monetizable ownership as the core value proposition.
Whether it’s the right bet, I genuinely don’t know. The execution risks are significant. Getting developers to build on a new chain is hard. Getting data contributors to show up with actually valuable datasets not spam, not low-quality content is harder. Maintaining validator quality while keeping the system decentralized is harder still. And eventually they’ll need enterprises willing to trust a decentralized pipeline for real AI workloads. None of that is a given.
But here’s what stuck with me after going through all of it: most AI tokens I’ve looked at recently are essentially narratives with a token attached. They’re selling a story about automation and agents without a clear answer to why the blockchain part needs to exist at all. OpenLedger at least has a coherent answer to that question. The blockchain isn’t decoration it’s the mechanism for solving the attribution and ownership problem they’ve identified.
That doesn’t mean they’ll pull it off. But it means they’re working on something real. And in this space, that’s rarer than it should be.