I used to think the main problem in AI was simply model quality. My view has changed because the more I look at OpenLedger the more I see a different question forming underneath the surface. What happens when an AI answer becomes useful but nobody can clearly explain which data helped make it useful.
That is where OpenLedger becomes interesting. It is not trying to talk about data as a vague raw material. It treats data as something with memory ownership and measurable influence. In normal AI systems data often disappears after training. It gets absorbed into a model and becomes hard to separate from the final output. OpenLedger is built around the opposite idea. Data should remain connected to the value it helps create even after it has been used by a model.
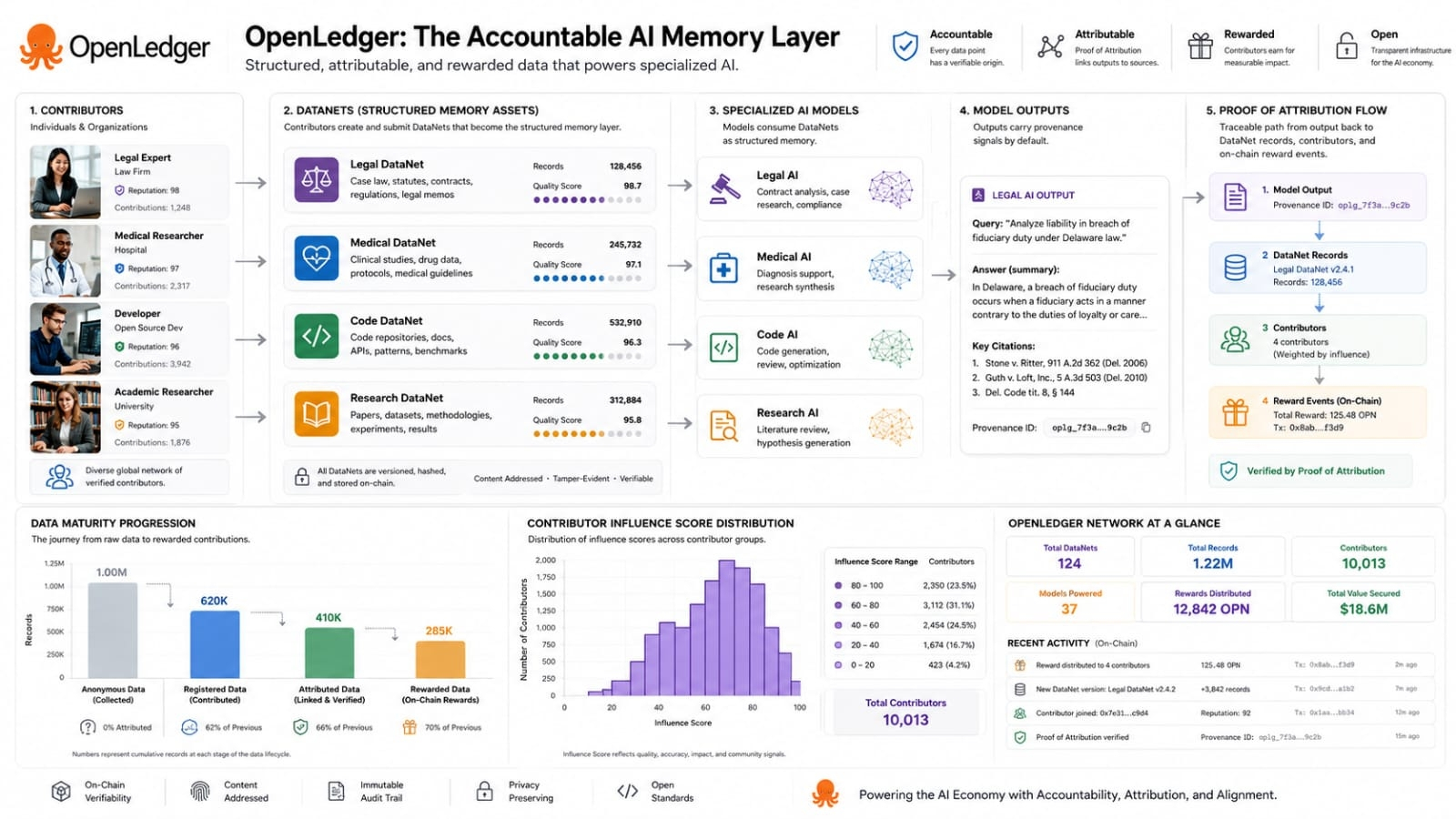
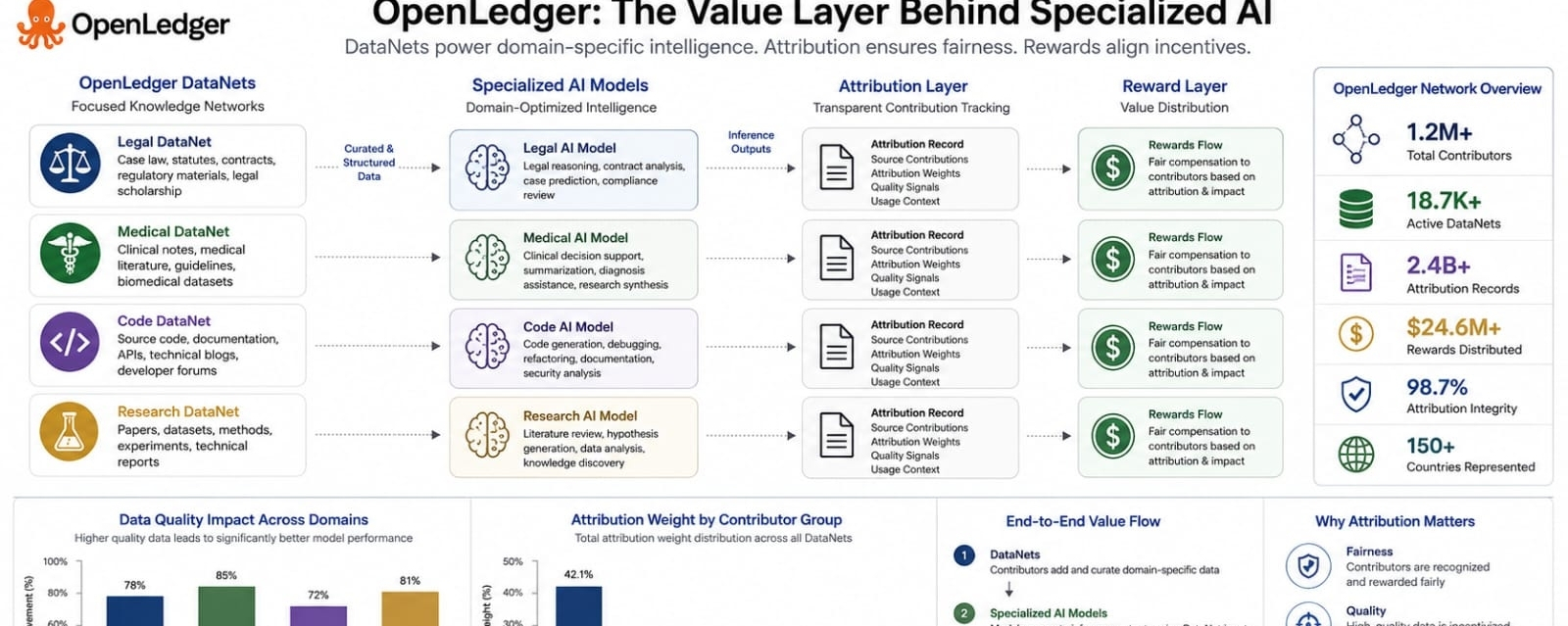
The project does this through DataNets and Proof of Attribution. A DataNet can be understood as a focused pool of knowledge built around a specific area. It is not just a folder of files. It is meant to be a structured source of training material that can be registered tracked and reused. Proof of Attribution is the mechanism that tries to connect model behavior back to those data sources. In plain terms it asks a hard question. When a model gives an answer which data actually mattered.
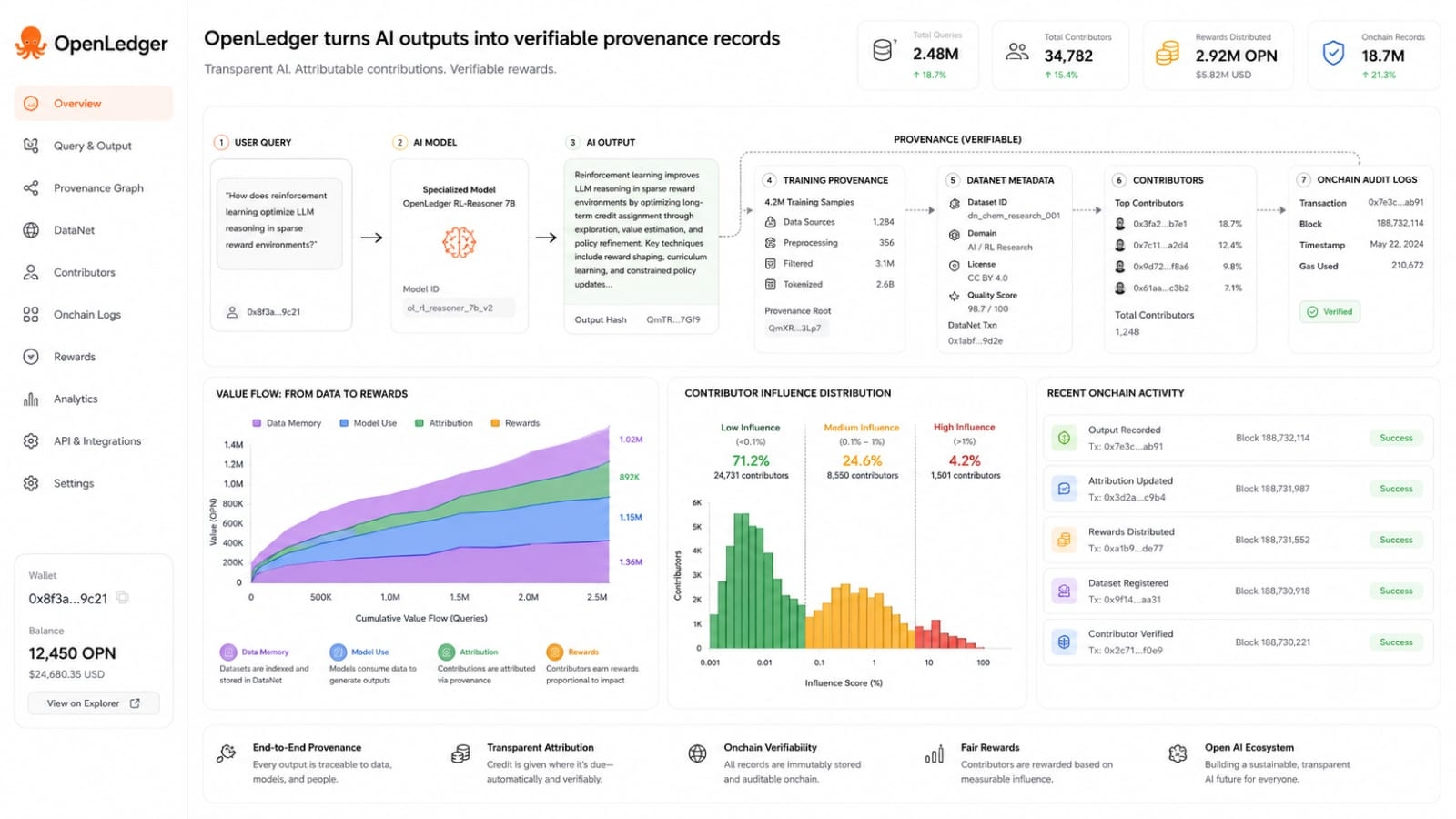
That question sounds simple until you think about how AI works. A model does not usually copy one piece of data and return it in a clean straight line. It absorbs patterns from many examples. Some examples shape the answer directly while others shape it in a softer way. Some influence may come from exact text matches while some may come from broader training effects. OpenLedger’s white paper responds to this by describing different attribution approaches for different model sizes. That detail matters because it shows the project is not pretending that attribution is easy.
The more original part of OpenLedger is not just the payment layer. Rewards are important but they are not the whole thesis. The stronger idea is that AI may need a memory supply chain. A model output should not be treated as a floating answer with no past. It should carry signs of where its knowledge came from and who helped make that knowledge useful. If that becomes normal then AI starts looking less like a black box and more like a system with records.
This matters most in specialized AI. General models can be impressive but serious work often needs narrow knowledge. A healthcare assistant needs carefully maintained medical information. A legal assistant needs strong jurisdiction aware material. A coding assistant needs examples that stay close to current developer practice. These domains do not only need more data. They need data that has context quality and accountability. OpenLedger’s DataNet design fits that problem because it gives communities a way to build focused knowledge layers instead of relying only on broad anonymous datasets.
The short term challenge is adoption. OpenLedger can have a thoughtful architecture and still need to prove that people will use it in a sustained way. Contributors must believe that adding data is worth their time. Model builders must find the attribution process useful rather than burdensome. Users must care enough about provenance to prefer outputs that come with a traceable history. These are not small assumptions. They are social and economic assumptions as much as technical ones.
I find the market logic most useful when it is kept sober. The stronger signals would be active DataNets with real domain depth. They would include models that use those DataNets in actual inference rather than only in theory. They would include reward records that contributors can understand and verify. They would also include builders choosing OpenLedger because attribution improves trust or creates better incentives. Weak signals would be empty datasets vague attribution claims low quality data farming or reward activity that does not seem tied to real model usefulness.
There is also a technical risk that should not be ignored. Attribution needs credibility. If the system cannot explain influence in a way that feels fair then the reward layer becomes fragile. Contributors may question why one dataset received more credit than another. Builders may question whether the added complexity is worth it. Auditors may need clearer evidence than a simple dashboard can provide. OpenLedger’s long term value depends on whether its attribution methods can be trusted across messy real world model behavior.
Still the upside is meaningful because the timing makes sense. AI is moving deeper into workflows where answers are not just entertaining. They are used to support research decisions writing code customer support education and internal business processes. As that happens people naturally start asking where outputs come from. They want better provenance. They want cleaner ownership. They want incentives that do not erase the people who supplied useful knowledge. OpenLedger is building directly around that shift.
My personal thesis is that OpenLedger should be judged less like a simple AI token narrative and more like an attempt to create accounting for machine intelligence. Not accounting in the financial software sense. Accounting in the sense of showing what entered the system what influenced the output and who deserves recognition when value is created. That is a harder story to build but also a more durable one if it works.
In the near term the project needs proof through usage. In the long term the bigger question is whether provenance becomes a default expectation for specialized AI. If AI users begin to demand answers with traceable memory then OpenLedger’s design becomes more relevant. If speed and convenience remain the only things users care about then attribution may stay niche for longer.
What I like about this angle is that it does not require pretending every detail is solved. The uncertainty is part of the story. OpenLedger is making a serious bet that future AI will need visible data lineage and contributor economics. That bet may take time to validate. It may face technical pressure and adoption friction. But the core idea is strong enough to watch closely. AI systems are becoming more powerful and more embedded in daily work. The question is whether their memory will remain invisible or whether projects like OpenLedger can make that memory accountable.
