
I was going through my feed when a notification dropped OpenLedger, something about AI agents coordinating collateral dynamically, pr0tecting loan positions automatically. Smart infrastructure. But it reminded me of a much older problem that this same infrastructure is supposed to fix.
The people whose data makes AI work have never been paid for it.
Everyone talks ab0ut AI democratization. Nobody talks about the people who actually built the datasets that made AI possible and received nothing for it.
This is not a small problem. The AI industry runs on data. Medical REcords, browsing behavior, social media posts, written content, images, conversations. All of it Harvested, cleaned, labeled, and fed into models that generate enormous commercial value. The original COMntributors sit entirely outside the economic equation.
OpenLedger's DATENTS address this at the infrastructure level. Contributors upload structured datasets onchain. Every access event every time that data is used for training or inference triggers an automatic OPEN token payment to the contributor. No intermediary. No platform taking a cut. Direct compensation tied to actual usage.
The mechanism is straightforward. What is genuinely novel is that it makes data contribution economically rational for the first time not as a donation to a platform, but as a productive asset that generates ongoing returns.
I find the framing around contributor rights in crypto tends toward the ideological. Decentralization as a value in itself. Community ownership as a principle. What OpenLedger's model does differently is make contributor compensation a mechanical outcome rather than a stated intention. The smart contract pays. The intention does not matter.
Most platforms that claim to compensate contributors rely on governance decisions, treasury allocations, or discretionary reward programs all dependent on the organization choosing to follow through. Automatic smart contract distribution removes that choice entirely. 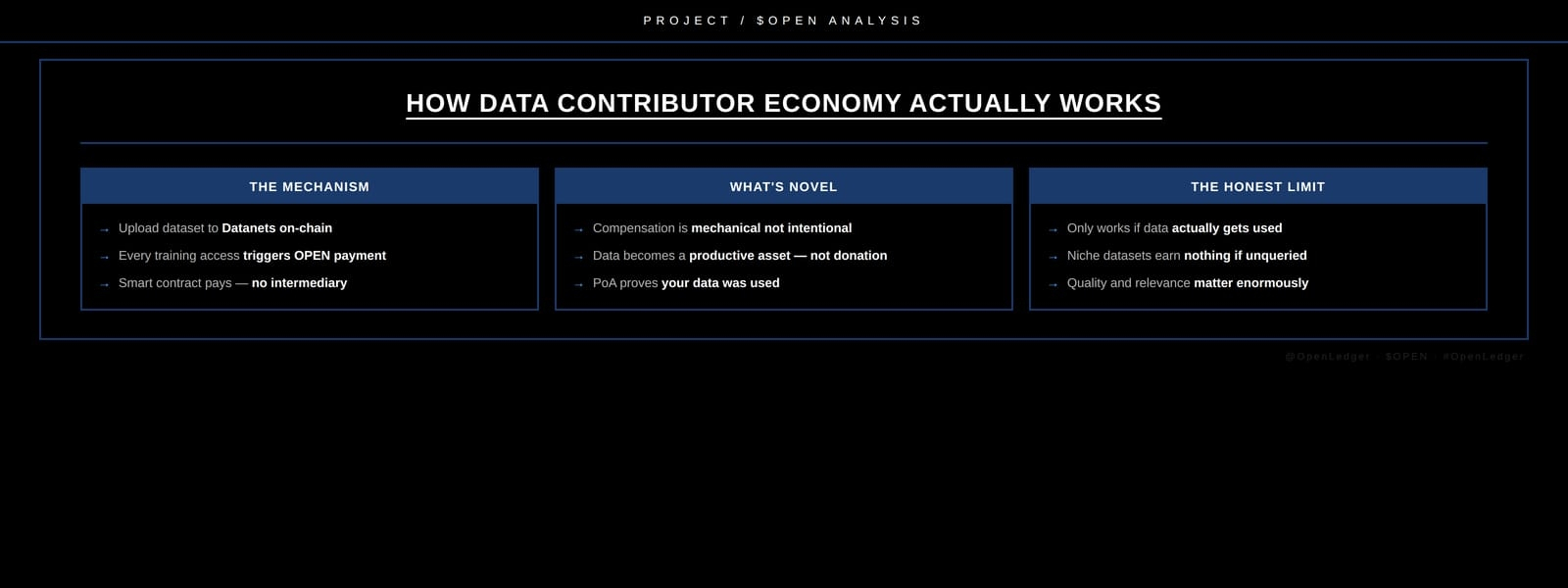
The honest limitation is that this system only works if the data being contributed is actually used. A contributor who uploads a niche dataset that nobody trains on earns nothing regardless of how valuable that dataset might theoretically be. Compensation is usage driven, not contribution driven. Quality and relevance matter enormously.
The 30% community allocation 300 million OPEN is designed to sustain contributor incentives over time. The TGE unlocked a significant portion immediately to bootstrap early participation. The remainder releases linearly over 48 months. The design acknowledges that contributor economies take time to develop.
What I keep thinking about is whether the contributor base that forms in the first twelve months reflects genuine data value creation or reflects people optimizing for reward mechanics rather than data quality.
Those two things produce very different ecosystems twelve months later.
If you were a data contributor what would actually determine whether you trusted a protocol with your datasets for the long term?