The agent was still waiting.
That was stupid part.
Nothing had fired yet on OpenLedger. No inference call. No Datanet lookup. No vault route. No recommendation pushed into the internal channel where everyone pretends they are “just reviewing” while already half-trusting the machine because the dashboard looks expensive.
Just setup.
Provider.
Model.
Datanet.
Tools.
Memory.
Runtime.
Approval rule.
A few dropdowns. A few toggles. A few harmless little permission boxes sitting there like they were not about to decide what the agent could touch, what it could know, what it could forget, and which version of reality it would treat as usable.
I kept staring at that part.
Not the agent.
The room around it.
A small desk, late night, bad coffee, three tabs open because humans apparently enjoy building critical workflows inside browser clutter. A builder is setting up an OpenLedger agent for a treasury-style monitoring job. Nothing dramatic. The agent needs to watch a few market signals, read a project-specific Datanet, compare the data against a fine-tuned model, produce a risk note, then send an action request if exposure crosses the internal threshold.
Simple enough.
That phrase usually means someone is about to hide the dangerous part.
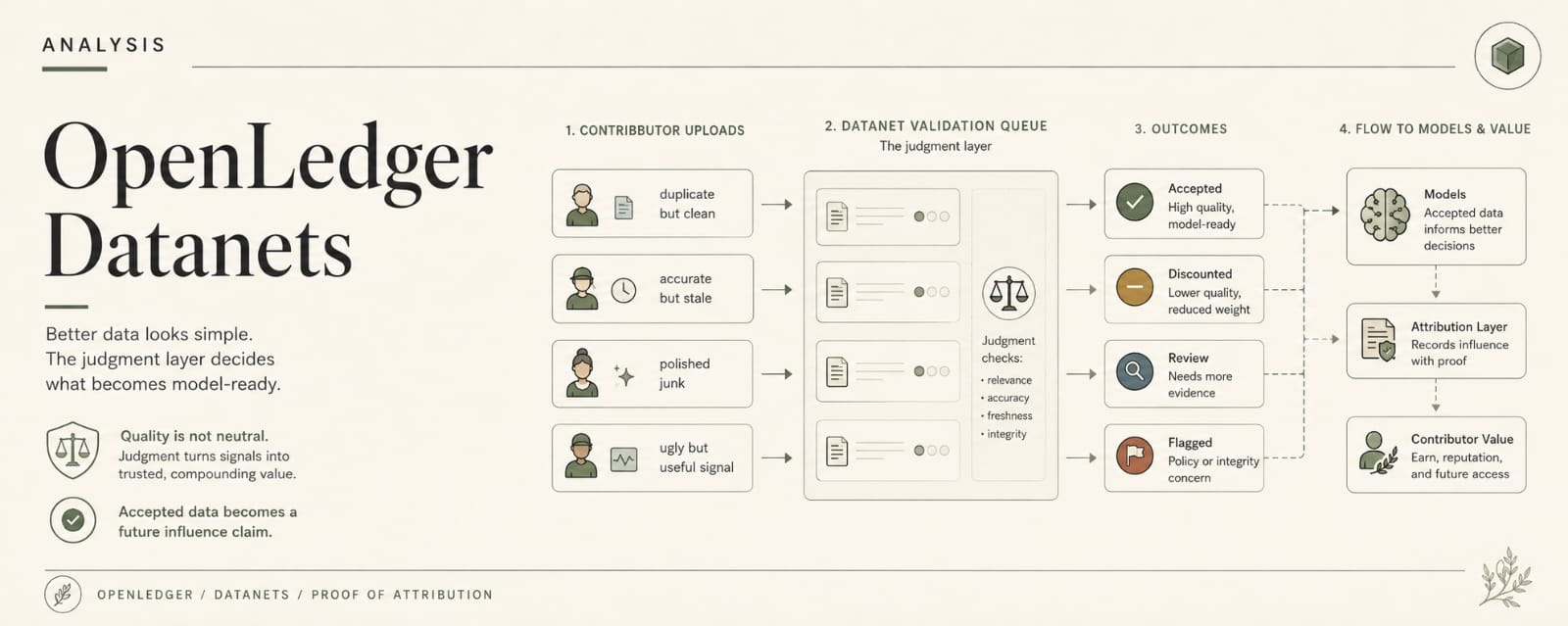
The agent gets attached to a Datanet first. That already decides the data universe. Not “data” in the broad, friendly conference-panel sense. Actual data. The selected contributor pool. The versioned records. The slices that made it through upload and validation. The signals someone thought were clean enough to matter.
Then the model gets picked.
Maybe a general model is too soft for the job. Maybe OpenLoRA or a specialized model from the OpenLedger stack makes more sense because the team needs narrower behavior. Better context. Less generic sludge. Good.
But now the mistake shape changes.
A general model may miss the domain pressure.
A specialized model may over-trust the domain it was shaped around.
A fine-tuned model may sound more confident exactly when it should be sweating.
Useful. Dangerous. Normal Tuesday.
Then tools.
This is where the agent starts looking less autonomous and more domesticated.
Can it query another source if the Datanet signal is stale?
Can it call the vault contract directly?
Can it only draft a recommendation?
Can it check attribution metadata before using a model output?
Can it inspect which dataset influenced the inference?
Can it refuse action if the provenance trail looks thin?
Can it ask for human approval when the model and market feed disagree?
Each answer is a fence.
Nobody calls it a fence because “configuration” sounds cleaner and less guilty.
Fine. Configuration.
The agent still has not moved.
Already, most of the workflow has been governed.
That is what keeps bothering me with OpenLedger agent workflows. The visible action comes late. The real power starts earlier, while everyone is still in setup mode, acting like they are just wiring pipes.
OpenLedger makes data, models, and agents more traceable. That matters. Datanets give the agent a structured supply line instead of some random scraped soup. Proof of Attribution tries to identify which data influenced a model’s inference and route value back to contributors. Model Factory and OpenLoRA make specialized model deployment less like carrying a server rack uphill. AI Studio pushes the whole thing toward usable agents and apps.
Good machinery.
Still machinery.
And machinery has control points.
The agent may feel like the actor, but the setup decides the stage, the doors, the props, the script margins, the budget, and the fire exits.
That is not abstract governance. That is the grubby kind. The kind buried in defaults.
A runtime cap decides whether the agent has enough time to cross-check the signal or just returns the first clean-looking answer. A tool permission decides whether it can verify freshness or stare politely at yesterday’s data like a dead fish on glass. A model selection decides whether the risk note comes back cautious, aggressive, or fake-balanced in that annoying AI way where every sentence sounds like it wants a LinkedIn badge.
Memory makes it worse.
Of course it does.
If the agent remembers yesterday’s failed route, it can avoid repeating the same mistake. If it remembers too much, it may drag stale assumptions into today’s run. If memory is blocked, the system becomes cleaner and dumber. If memory persists, the system becomes smarter and harder to audit.
Pick your inconvenience. Humanity’s greatest product category.
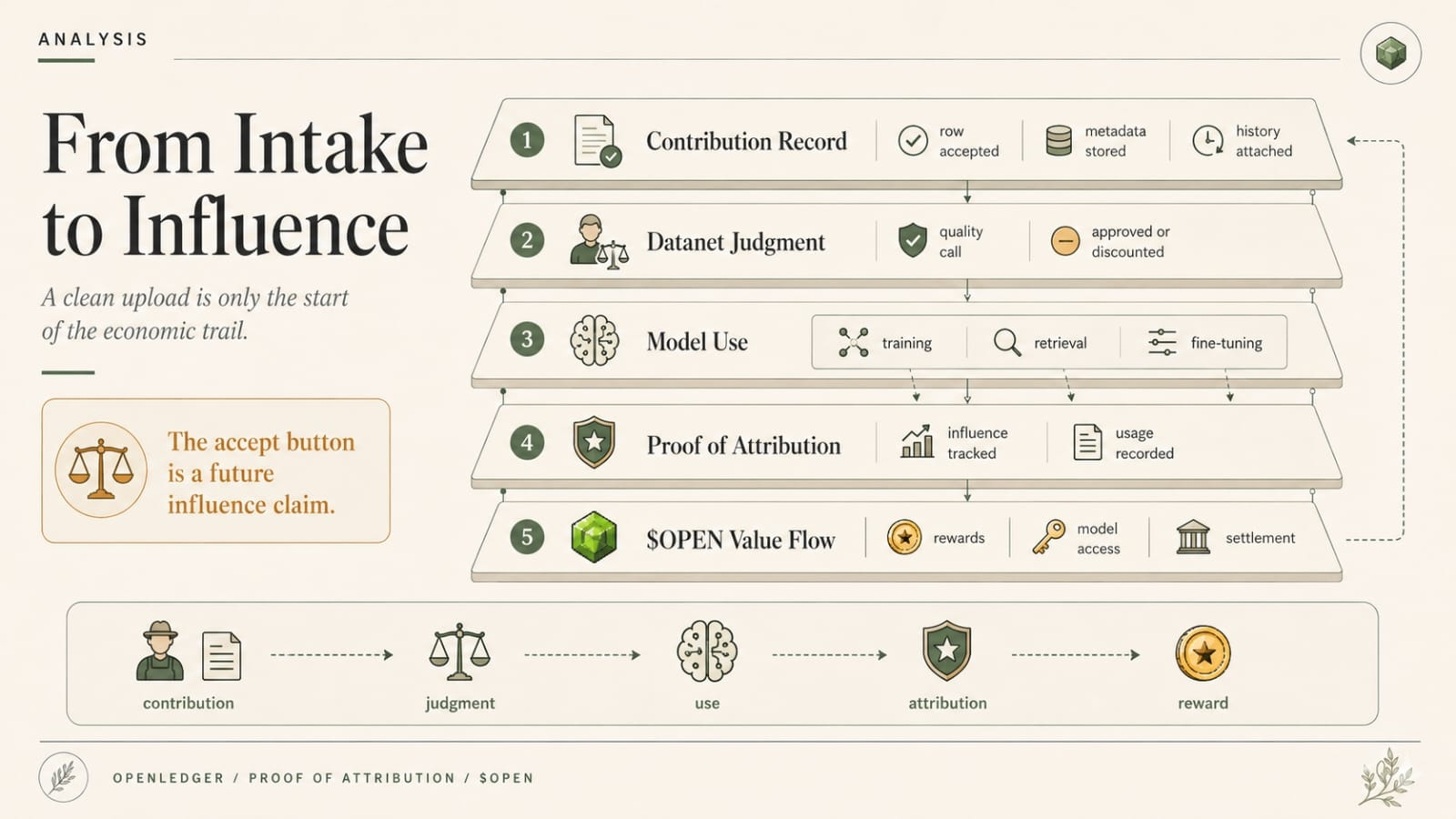
Now add OpenLedger’s attribution layer.
This is where the bruise gets deeper.
Suppose the agent pulls from a Datanet, runs inference through a specialized model, and generates a recommendation that later triggers value. Maybe not direct trade execution yet. Maybe just a treasury action request. Maybe a risk alert that changes collateral posture. Maybe a routing suggestion that moves money after approval.
The output now has a traceable data story. That is the promise. Which data influenced the inference? Which contributor deserves reward? Which model or adapter helped shape the answer? OpenLedger wants that influence path to be visible and payable.
Good.
But my problem starts one layer before the attribution trail.
Who decided the agent could only use that Datanet?
Who picked the model whose inference created the attribution event?
Who allowed that tool path?
Who blocked the second verification call because it cost too much or took too long?
Who set the agent to recommend instead of execute?
Who changed the memory rule last week after one noisy output and forgot to document it because everyone was “moving fast”?
Tiny setup choices.
Then later, rewards move. Fees get spent. Contributor influence gets measured. The model output gets treated as the product of a traceable AI pipeline.
But the pipeline was already narrowed.
That is the wound.
Proof of Attribution can explain what influenced an inference inside the allowed path. It does not automatically tell you why that path was the allowed one.
And in real workflows, that gap matters.
A data contributor may get rewarded because their dataset influenced the output. Fair enough. But what about the dataset that was excluded because the builder did not attach it? What about the model that never got called because the cheaper provider was selected? What about the verification tool that could have caught the stale signal but sat outside the permission list like a locked medicine cabinet?
The agent “decided.”
No.
The agent selected from a menu someone already cut down.
I am not saying that is bad. This is the annoying part. It is necessary.
You cannot run OpenLedger's AI agents near data, models, inference costs, attribution rewards, and possible execution rights without constraints. That is not autonomy. That is a lawsuit generator with a friendly UI. Runtime limits, tool whitelists, model boundaries, approval gates, memory rules, and provider choices exist because open-ended agents are not brave little explorers. They are operational liabilities until proven otherwise.
But constrain them too much and the autonomy becomes performance art.
The agent reads only what it is allowed to read.
It reasons through the model it was handed.
It spends within limits it did not set.
It remembers only what the operator permitted.
It “discovers” only inside a room someone already cleaned.
Very autonomous. Very adorable. Put it on a sticker.
A real team would feel this fast.
The analyst sees the agent’s risk note and asks why it ignored a liquidity signal. The developer says the tool was not attached. The treasury lead asks why the model leaned so hard on one contributor dataset. Someone checks the Datanet path. The data was valid. The attribution was clean. The inference was logged.
Still wrong enough to be expensive.
Not fraudulent.
Not broken.
Just configured into a narrow view.
That is the kind of failure that actually happens. No villain. No big exploit. Just a setup layer that looked boring until it started deciding outcomes.
And OpenLedger makes that failure more interesting because the stack is not only producing outputs. It is trying to make AI work economically legible. Data contributors are not invisible anymore. Models are not just black-box services floating around with invoice fumes. Agents are not just chatbots with gloves. The system wants data, models, agents, inference, and rewards to sit inside one accountable economic rail.
Fine.
Then setup cannot stay invisible.
If the configuration decides which Datanet gets used, which model runs, which tool checks provenance, which memory survives, and which approval gate stands between recommendation and action, then configuration is part of the economic rail too.
Not visually. Not ceremonially. Not in the “governance forum post with twelve paragraphs and two voters” way.
Operationally.
The setup is where policy becomes behavior before anyone votes on anything.
That is why this theme feels more Midnight-coded than normal agent talk. The thing around the thing starts to matter more than the thing. The privacy rule mattered before the private workflow. The attestation schema mattered before the credential got used. The task board mattered before the Pixels player felt the reward route bend under their feet.
Same irritation here.
The agent is the visible moving part.
The setup is the hand on its shoulder.
I keep thinking about the approval window. That little delay before action. Maybe the OpenLedger agent produces a recommendation based on Datanet input and model inference. It sends the request to a human signer or a policy module. Five minutes pass. Market moves. The data is now less fresh. The attribution path is still clean. The model output is still explainable. The recommendation is still logged.
And now the whole workflow is stuck in that ugly gap between correct-when-produced and dangerous-when-approved.
Who owns that?
The agent? The model? The Datanet? The operator? The approval rule? The person who set runtime short because longer runs cost more OPEN? The person who blocked automatic re-check before execution because “we’ll add that later”?
There it is.
The boring setup becomes the liability map.
The setup decided whether the agent could re-query before approval. The setup decided whether stale outputs expire. The setup decided whether attribution was checked once or tied to execution timing. The setup decided whether a second model opinion was allowed when money was involved.
And everyone only noticed after the agent did exactly what it was permitted to do.
That is the most irritating failure class because the system can be working and still be wrong.
OpenLedger’s deeper architecture does not remove that problem. It exposes more of it. That is actually useful, even if it makes the room uglier. Datanets make the data path visible. Attribution makes influence visible. On-chain registries make the assets and agents more legible. Tokenized incentives make contribution and usage economically real.
But the agent’s permission world still needs its own accounting.
Not just what did the agent do.
What was it allowed to do?
Not just which data influenced the inference.
Which data was excluded before inference?
Not just who earned reward.
Who controlled the path that made reward possible?
Not just whether the output has provenance.
Whether the setup that shaped the output has provenance too.
That is where OpenLedger gets serious for me.
Not in the marketing sentence. Not in “AI blockchain.” Spare me, truly. The phrase has been through enough abuse.
The serious part is... if OpenLedger wants data, models, and agents to become monetizable infrastructure, then agent configuration is not a side panel. It is the pre-action governance layer. It decides the agent’s world before the agent can pretend to act inside it.
The agent feels autonomous because motion is easier to see than constraint.
A tool call looks alive.
A model answer looks intelligent.
A logged inference looks accountable.
A reward payout looks fair.
But behind all that, the setup screen sits there with dry little choices that already bent the route.
Provider. Model. Datanet. Memory. Tools. Runtime. Permissions. Approval.
The agent wakes up after the most important decisions have already been made.
That is what keeps sticking.
Not whether OpenLedger agents can act.
They can.
The worse question is whether the setup layer can be made visible enough that “autonomy” does not become a nice word for choices buried upstream, made by someone tired, under budget pressure, trying to ship before the next review call, clicking boxes like they are not writing the operating law of the machine.