

Introduction
OpenLedger is one of those projects that tries to answer a very real problem in the modern AI world, and that problem is simple to say but hard to solve: data, models, and AI systems create enormous value, yet the people who contribute the ingredients often do not get a fair share of the rewards, and the process is usually hidden behind private servers, closed platforms, and centralized control. OpenLedger is built as an AI-focused blockchain that wants to change that by moving important parts of the AI lifecycle on chain, making them verifiable, traceable, and easier to monetize. In simple terms, it is trying to turn AI from something that is mostly closed and controlled into something more open, liquid, and community-powered, and that idea is what makes it stand out. From the material shared across Binance, Phemex, CoinMarketCap, OpenLedger’s own site, and its whitepaper summary, the project is presented as infrastructure for a new kind of AI economy where datasets, models, and agents can be registered, tracked, rewarded, and used more transparently.
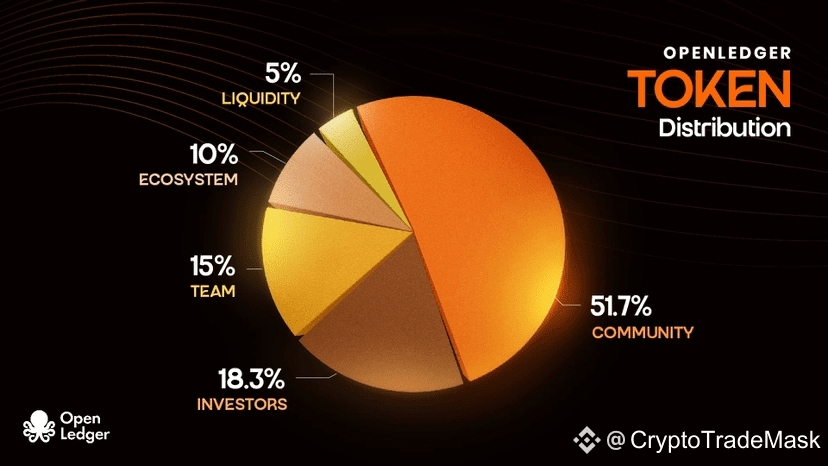
What OpenLedger is trying to solve
The basic reason OpenLedger exists is because the current AI stack has a trust problem and a compensation problem at the same time. Most people can use AI tools, but they cannot easily know what data trained the system, who contributed to that data, how the model was refined, or whether the output can be traced back to a fair reward system. That opacity matters because data is not free in practice; it comes from workers, communities, creators, and organizations, yet the value often gets captured by a small number of companies. OpenLedger is designed to address this by giving AI operations a blockchain layer where attribution can be recorded and incentives can be distributed more fairly. That means the network is not just about storing token transactions, but about making AI itself auditable and economically visible. The project’s own description and third-party summaries repeatedly emphasize the same mission: unlocking liquidity to monetize data, models, applications, and autonomous agents while preserving transparency and accountability.

How the system works, step by step
OpenLedger’s idea becomes easier to understand when you look at the flow of the system from data to model to deployment to reward. First, data providers contribute datasets through community-driven datanets, which are specialized data collections for AI training. Then model developers can use those datasets, often through tooling such as a no-code Model Factory mentioned in some summaries, to train or refine models without needing an overly complex setup. After that, the model can be registered and deployed on chain, which is important because the network is not treating the model like a secret object hidden in a private environment, but like something with an on-chain identity and traceable history. Once the model is used, OpenLedger’s Proof of Attribution system tries to determine which data contributed to the output and then allocates rewards accordingly. In practice, the idea is that if a contributor’s data improves the model’s result, that contribution should not disappear into the background; instead, it should be recognized and compensated. That is a big philosophical shift from the usual AI economy, where contribution is often invisible and value sharing is highly uneven.
Why the blockchain design matters
OpenLedger is not just using blockchain as a buzzword layer, because the technical design is closely tied to the project’s core goals. According to the available materials, OpenLedger is built as an Ethereum Layer-2 solution using the OP Stack, which means it inherits Ethereum’s security model while aiming for lower costs and better scalability for AI-related activity. That matters because AI workloads can involve lots of updates, registry entries, usage records, attribution checks, and incentive events, and all of those would be expensive or inefficient if they were handled directly on a congested base layer. By using an optimistic rollup approach, the chain can batch transactions, keep the system more efficient, and rely on fraud proofs to protect integrity. Another important technical choice is EVM compatibility, because that makes it easier for developers to connect wallets, smart contracts, and existing Ethereum tools without having to rebuild everything from scratch. When a project says it wants to make AI and Web3 work together, compatibility is not a small detail; it is often the difference between something that can grow and something that stays isolated.
The role of data in OpenLedger
Data is really the heart of the OpenLedger story, and that is why the project repeatedly talks about datanets, attribution, and monetization. In the AI industry, data is the raw fuel that shapes model behavior, but most contributors do not know when their data is being used or whether they are being paid fairly for it. OpenLedger tries to make data contributions legible on chain, so that the origin, use, and influence of datasets can be tracked more clearly. The benefit here is not only financial; it is also about trust. If a healthcare dataset, a finance dataset, or a specialized industrial dataset is used in a model, the people who provided that data may want proof of its role and a programmatic way to receive compensation. That is where the idea of native attribution becomes powerful, because it turns data from a silent input into a recognized asset. The project’s messaging on Binance and CoinMarketCap also highlights the large-scale opportunity here, describing a major data problem in which high-value datasets remain siloed and uncompensated. OpenLedger’s answer is to build a market where that value can move more freely.

The role of models and agents
OpenLedger is not stopping at data. It also wants models and autonomous agents to be first-class on-chain assets. This is important because in the AI economy, the model itself is often the commercial product, and agents are increasingly the interface between users and complex systems. If a developer trains a model, OpenLedger’s vision is that the model can be tokenized, sold, rented, shared, or otherwise used in a transparent ecosystem where rights and rewards are clearer. The same logic extends to agents, which may act on behalf of users, automate tasks, or interact with decentralized applications. By putting models and agents into the same economic framework as data, OpenLedger is trying to create a full stack where each layer can be measured and monetized. That is a very different approach from simply launching an AI token and hoping speculation does the rest. It is closer to building a market infrastructure, one where the digital assets are not static but alive, usable, and linked to real activity.
Proof of Attribution and why it is central
One of the most interesting concepts associated with OpenLedger is Proof of Attribution, and it may be the project’s defining feature if it works well at scale. The idea is that when a model produces an output, the system should be able to trace how the data influenced that output and reward the relevant contributors. Some summaries mention gradient-based and suffix-array techniques in the attribution engine, which suggests the project is trying to use computational methods to estimate influence at the inference level rather than relying on guesswork. That is technically ambitious, because attribution in AI is hard, especially when many sources of data contribute to a single result in indirect ways. But if it succeeds, it could solve one of the industry’s biggest fairness issues by making compensation more precise and defensible. It would also make AI behavior more auditable, which is increasingly important as regulators, institutions, and users ask for explainability and provenance. In a sense, Proof of Attribution is not just a feature; it is the bridge between AI performance and economic justice.
Token utility and ecosystem role
The OPEN token is presented across sources as the native asset of the OpenLedger ecosystem, and it serves several different roles at once. It is used for network transactions, gas, staking, governance, model access, inference fees, and participation in datanets. That gives the token a broad functional scope, which matters because utility tokens tend to be more meaningful when they are attached to actual network behavior rather than being isolated from the core product. If a developer wants to train or deploy a model, OPEN may be needed. If a data contributor is rewarded, OPEN is part of the incentive structure. If validators or agents need to secure the network, staking comes into play. If governance decisions are made, holders may vote on upgrades or parameter changes. This combination creates a loop where the token is not just a speculative symbol but a working part of the machine. Of course, whether that utility becomes real at scale depends on adoption, but the design itself is clearly meant to support a living ecosystem.
Supply, circulation, and market structure
Based on the sources provided, OPEN has a maximum supply of 1 billion tokens, and the initial circulating supply at launch was 215.5 million tokens, or 21.55% of the total. That structure gives the market a clear supply ceiling, which some users may find comforting because it sets expectations around token issuance. A fixed max supply can also help frame long-term valuation discussions, although it does not guarantee performance. The token’s market profile is already visible on platforms like Binance and CoinMarketCap, where price, market cap, and circulation data are tracked in real time. For people watching this project, supply metrics matter because they influence liquidity, dilution expectations, and the market’s perception of scarcity. Still, supply numbers are only one part of the story. The real question is how much actual demand OpenLedger creates through model usage, data participation, and developer adoption, because without network activity the token economics can become disconnected from the product vision.
Important metrics people should watch
Anyone following OpenLedger should pay attention to several practical metrics rather than only the token price, because the health of a blockchain AI project depends on network usage as much as on market sentiment. Circulating supply and max supply are important, but so are the number of active datanets, the growth of registered models, the volume of transactions related to training and inference, and the number of contributors receiving attribution rewards. It is also worth watching whether developers are actually deploying models on the network, whether staking participation is growing, and whether governance becomes active or remains dormant. For an AI blockchain, user adoption can show up in many forms, so it helps to look for signs of real usage rather than excitement alone. If OpenLedger’s metrics show more models, more datasets, more deployments, and more rewards being distributed, that would be a much stronger signal than hype on social media. On the technical side, the reliability of the attribution engine and the cost of on-chain operations will also matter a lot.
The risks OpenLedger faces
OpenLedger has a strong narrative, but it also faces serious risks, and it is better to be honest about them. The first risk is technical complexity, because attribution in AI is hard and doing it on chain at useful scale is even harder. If the system cannot reliably trace influence or if the attribution results are disputed, the core promise becomes difficult to maintain. The second risk is adoption, because a blockchain built for AI only matters if developers, data providers, and users actually want to participate. If the ecosystem stays small, the network effect may never fully appear. The third risk is competition, because other projects are also trying to combine AI and blockchain, and some will focus on data provenance, others on decentralized compute, and others on AI agents. The fourth risk is regulatory uncertainty, since token incentives, data usage rights, and AI accountability all sit in a messy policy environment that can change quickly. There is also the usual crypto market risk: price volatility can distract from product development, and speculation can move faster than real utility. So while the project’s vision is exciting, the path forward is not simple.
Why people are interested anyway
Even with those risks, the reason OpenLedger gets attention is that it speaks to a deep frustration in the AI era. People know AI is powerful, but they also know that power is often concentrated. They see datasets being used without clear compensation, model behavior that is hard to inspect, and closed systems that turn users into consumers rather than participants. OpenLedger’s pitch is emotionally appealing because it promises a fairer and more open structure, one where contributors can be rewarded and where AI operations do not have to stay hidden behind corporate walls. It also fits the larger Web3 idea of ownership and transparency, but with a more practical purpose than many older crypto narratives. Instead of simply saying “decentralize everything,” OpenLedger is trying to answer a real industrial problem: how do we create a market for data, models, and agents that is actually trustworthy and programmable?
Future possibilities
If OpenLedger grows successfully, its future could unfold in several interesting directions. It could become a layer where specialized AI models are trained on community data and then licensed through transparent on-chain markets. It could support a large ecosystem of developers building agents for finance, healthcare, gaming, education, and supply chain use cases, as some of the sources suggest. It could also become a place where enterprises and independent creators participate in AI economics without fully surrendering control to centralized platforms. If the attribution system proves reliable, that alone could become a major differentiator, because many companies and organizations want better provenance and fair reward systems but do not have an easy way to implement them. On the other hand, if growth is slower than expected, OpenLedger may still find a role as a specialized infrastructure layer rather than a mainstream consumer platform. Either way, the project sits in a very relevant part of the market, because the demand for verifiable AI is only likely to increase.
Final thoughts
OpenLedger is ambitious, and ambition is exactly what makes it worth watching. It is trying to connect AI and blockchain in a way that is not superficial, but structural, by giving data, models, and agents an economic identity on chain. That means it is aiming not only for transparency, but for a new kind of participation where value can be tracked and shared more fairly. I think that is what gives the project its human side, because behind all the technical language is a simple idea that many people can understand: if your data helps build intelligence, you should not be invisible. If a model creates value, its history should be known. If an agent works in a network, the network should be able to see it. OpenLedger is still facing the real-world test of adoption, execution, and technical reliability, but the vision is clear and the market need is real. If they keep building carefully, we’re likely seeing the early shape of a much larger conversation about what fair AI infrastructure should look like in the years ahead.