Ho partecipato a qualche voto nel mondo crypto con una sensazione molto strana.
Proposta lunga. Ci sono termini tecnici. Ci sono grafici. C'è una sezione che spiega perché questa decisione è vantaggiosa per la comunità. Ne ho letta metà e mi chiedo: capisco davvero abbastanza per votare?
La cosa fastidiosa è che so che molte altre persone potrebbero essere nella mia stessa situazione. Ma alla fine, il sistema riduce tutto a un numero molto semplice: favorevole o contrario.
Da lontano, sembra democrazia. Da vicino, a volte è solo fiducia collettiva confezionata come governance.
Quando leggo di OpenLedger, penso alla governance.
OpenLedger sta costruendo un'economia per modelli AI specializzati: Datanets raccolgono dati specifici, ModelFactory aiuta a fare fine-tuning, OpenLoRA rende i modelli più efficienti, Proof of Attribution riconosce i contributi, mentre la governance partecipa alla decisione su quale modello debba essere sviluppato ulteriormente.
Questa idea ha senso.
Ma qui c'è anche un problema.
Se un modello di trading o contabilità viene presentato alla comunità per decidere se debba progredire, la prima domanda non è 'alla comunità piace?'
La prima domanda deve essere: la comunità è in grado di valutarlo?
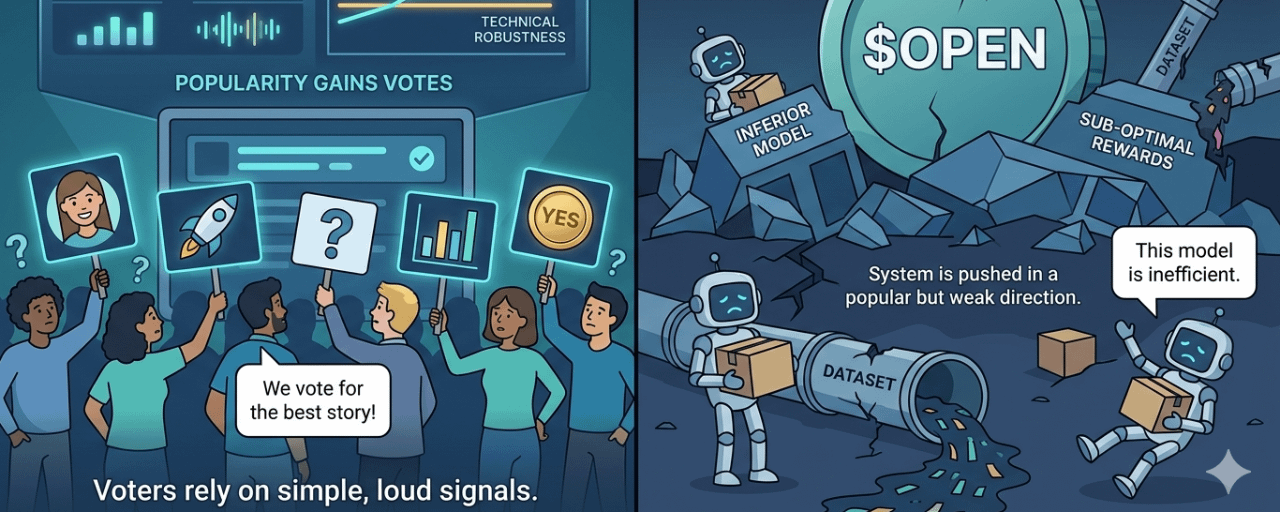
Chiamo questo problema Governance Popularity Bias.
La bias popolare nella governance.
Succede quando una decisione che richiede competenza profonda viene tirata verso segnali più evidenti: chi racconta la storia meglio, quale comunità è più numerosa, quale narrativa è più calda, quale modello ha un dashboard più bello.
Un modello può essere sostenuto non perché sia migliore, ma perché è più comprensibile. Un Datanet può vincere non perché i dati siano più puliti, ma perché la comunità che lo supporta è più rumorosa.
Il Crypto ha affrontato questa situazione molte volte. Il voto DAO non sceglie sempre l'opzione giusta. Spesso sceglie l'opzione con meme più forti. Anche l'open-source è così. Un repo con molti star non è necessariamente il più sicuro. Un paper citato frequentemente non è sempre il più affidabile.
Con OpenLedger, questo rischio è maggiore, perché il modello non è solo un post da leggere e dimenticare. Il modello può essere usato per inferenze. Può ricevere ricompense. Può diventare parte del workflow di un agente. Può coinvolgere contribuenti di dati, validator, staker, utenti e la filiera $OPEN dietro.
Se la governance sceglie male, il costo non è solo una cattiva decisione.
È un intero ecosistema tirato verso una direzione che sembra piacere alla massa ma è debole in competenza.
Quindi, penso che OpenLedger abbia bisogno di uno strato aggiuntivo: Governance Ponderata per Competenza.
Governance con peso di competenza.
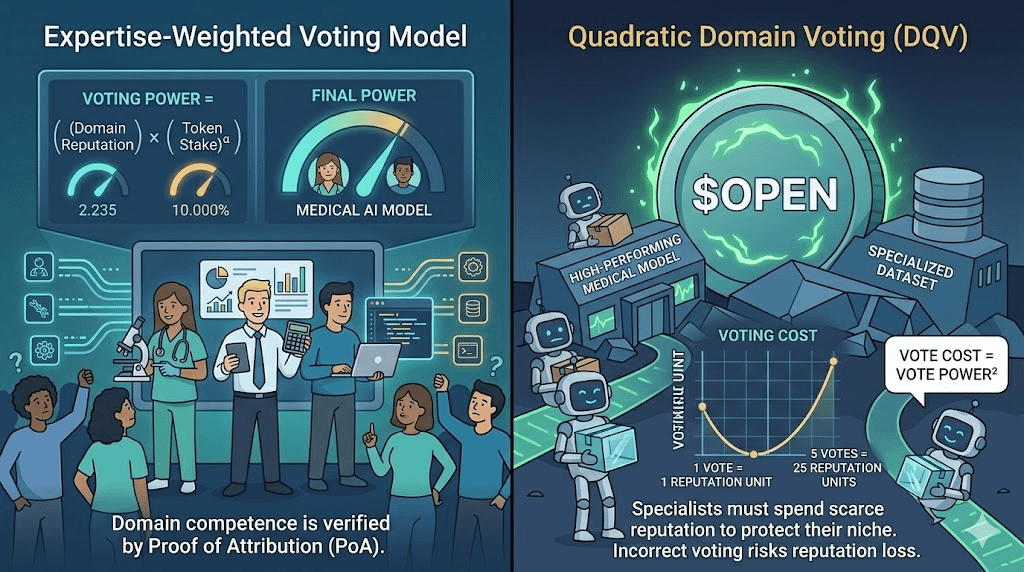
Ma questo peso non dovrebbe essere inteso in modo generico come 'ascoltare di più gli esperti'. Così sarebbe ancora troppo debole. Dovrebbe essere progettato come un meccanismo più specifico: Domain-Specific Attenuated Voting, cioè il diritto di voto è ridotto o amplificato in base al reale contributo in quel specifico campo di conoscenza.
Un wallet che detiene molti $OPEN non dovrebbe automaticamente avere una voce forte in ogni modello. Se qualcuno possiede 1 milione di token ma non ha mai avuto un byte di dati riconosciuti da Proof of Attribution in un Datanet sanitario, il peso del loro voto per un modello medico dovrebbe essere significativamente ridotto. Al contrario, un medico con pochi token, ma che ha contribuito con dati per migliorare il modello in casi difficili, dovrebbe avere una voce più forte in quel campo.
La formula può essere molto semplice:
Voting Power(domain) = OPEN Stake × Reputation(domain)^α
In cui, OPEN Stake è la quantità di token partecipanti al voto, Reputation(domain) è il punteggio di reputazione accumulato dai contributi riconosciuti da PoA nel corretto Datanet o dominio pertinente, mentre α è il coefficiente di amplificazione della competenza. Più alto è α, più il sistema privilegia chi ha effettivamente una storia di contributi in quel campo.
In parole semplici: il diritto di voto non deriva solo da quanto possiedi, ma da quanto hai dimostrato di capire nel campo specifico su cui si vota.
Ma così non è ancora sufficiente.
Se un esperto ha un peso elevato, non dovrebbe essere votato a casaccio senza pagare un prezzo. Pertanto, OpenLedger potrebbe utilizzare anche il Domain Quadratic Voting, o DQV.
Invece di votare con un punto reputazione per ogni voto, concentrare molti voti su un modello deve avere un costo che cresce secondo il quadrato. Un esperto può usare tutta la sua reputazione per difendere un modello minoritario ma eccezionale, ma deve pagare il prezzo della reputazione accumulata dalle precedenti contribuzioni a Datanet.
Questo costringe sia gli esperti che la comunità a essere più seri.
Concentri i voti solo su ciò che comprendi veramente. Perché se voti male, voti per fazione, o voti per narrativa, ciò che perdi non è solo un voto. Quello che perdi è la reputazione professionale accumulata nel tempo.
Certo, questa soluzione non è pulita.
Chi stabilisce se la reputazione è affidabile? Gli esperti possono diventare una nuova classe di gatekeeper? I nuovi arrivati con buone idee possono essere schiacciati dai veterani? Un sistema di governance troppo popolare può essere facilmente influenzato dalla folla. Ma un sistema di governance troppo esperto può anche trasformarsi in un club esclusivo.
È questo il punto difficile.
Ma penso ancora che OpenLedger debba affrontarlo presto.
Perché l'AI specializzata non è come votare per il colore dell'interfaccia. Tocca dati, modelli, inferenze, ricompense e a volte anche le decisioni automatiche degli agenti. Se un modello errato viene promosso dalla comunità solo perché è popolare, nemmeno la trasparenza on-chain salverà la qualità. Ciò serve solo a mostrarci chiaramente come una cattiva decisione venga legittimata.
Non voglio un'AI blockchain dove tutto è 'supportato dalla comunità', ma nessuno ha il coraggio di chiedere se quella comunità capisce davvero ciò che sostiene.
L'ultima domanda è piuttosto diretta.
Se OpenLedger deve scegliere tra un modello amato dalla massa e un modello che è stato dimostrato migliore da un numero ridotto di esperti, quale opzione chiameranno vera decentralizzazione?
E ancora più difficile: vuoi che il futuro dell'AI sia governato da quante più persone possibile, o da chi sa realmente cosa sta votando?