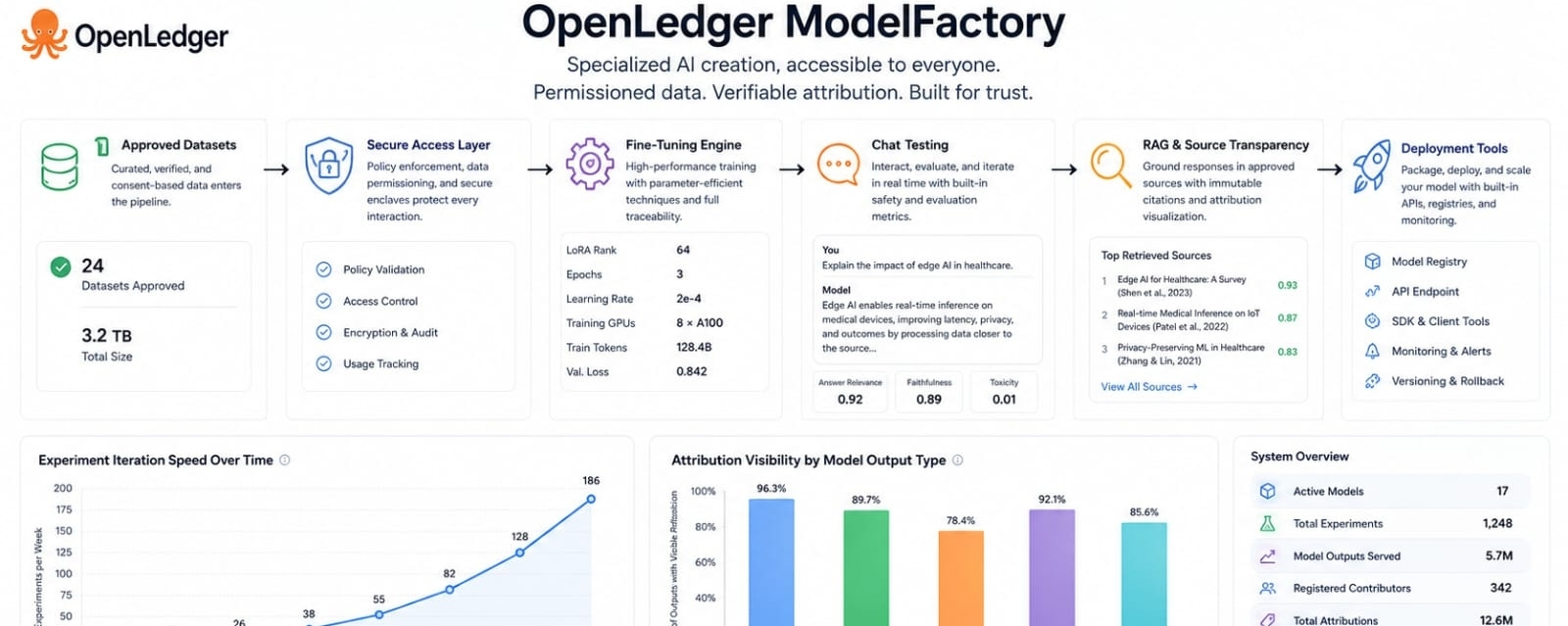
I used to think the hardest part of building a useful AI model was the model itself. My view has shifted because the harder question is often whether a person with the right data and the right problem can reach the tools without being blocked by setup. That is where ModelFactory becomes practical inside OpenLedger. It is presented as a fine tuning platform for large language models with a GUI only experience and datasets that are permissioned and approved through OpenLedger.
I find this important because no code tools are easy to misunderstand. They can sound like shortcuts. The better version is not about pretending complex work is simple. It is about removing the wrong kind of complexity. A domain team may understand the data better than a general developer. Yet setup can block early testing. ModelFactory is trying to make that first door easier to open while keeping the workflow tied to controlled dataset access and model training.
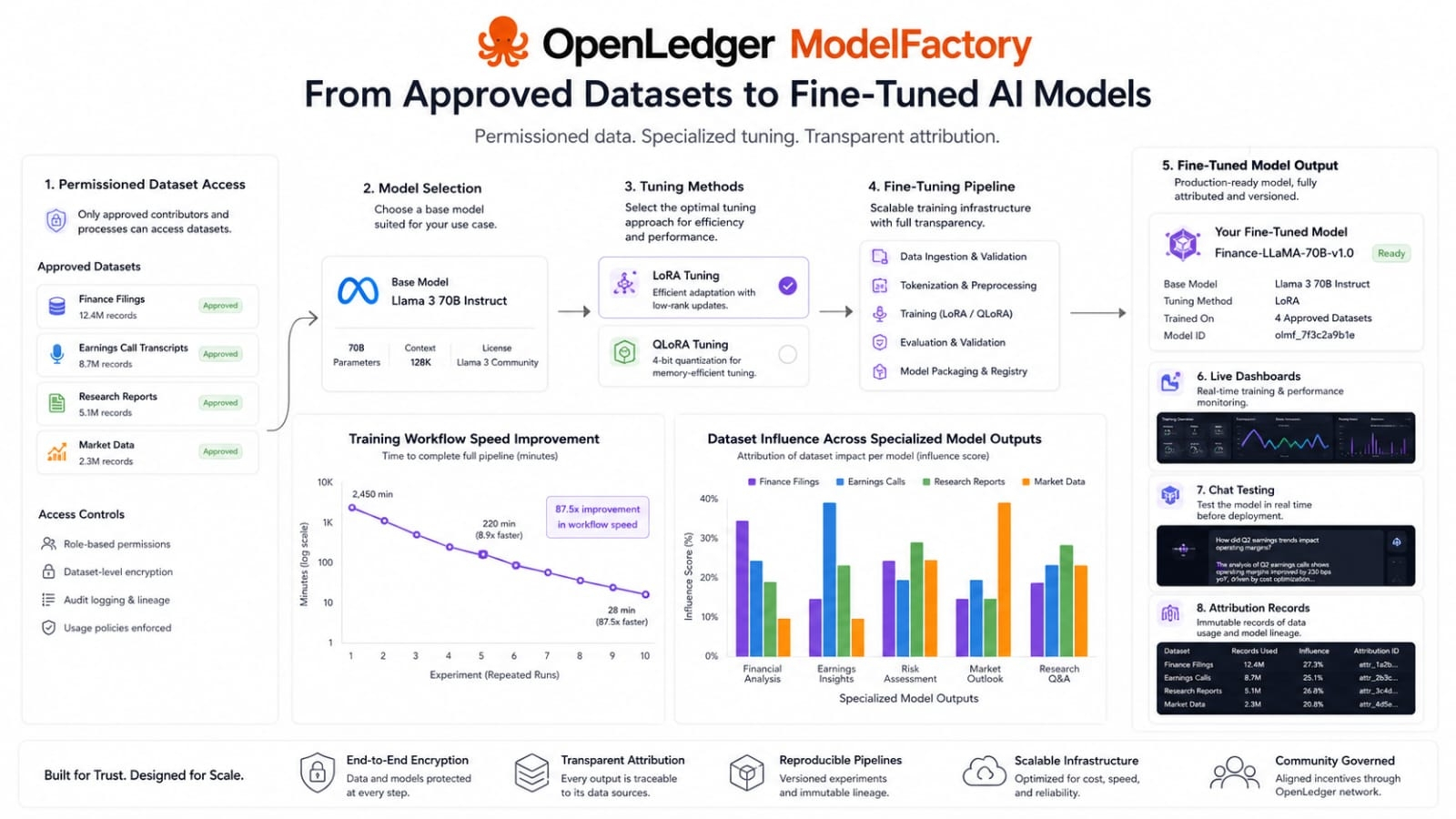
The official design points toward a clear path. A user can select from large language models such as LLaMA Mistral DeepSeek and others. Training settings like learning rate batch size and epochs can be configured through the interface. The fine tuning engine supports methods like LoRA and QLoRA. Training progress can be watched through live dashboards. After that the user can test or interact with the fine tuned model through a chat interface. I read this as OpenLedger trying to make specialized model creation less dependent on a narrow technical class and more available to people who understand the data itself.
The deeper thesis is that AI value may move closer to domain ownership. General models are useful but they often struggle when the task depends on narrow context verified records or specialized language. OpenLedger frames specialized data as important for accuracy interpretability efficiency and explainability. ModelFactory takes that idea further by giving those datasets a path into working models. The project is not just saying that data matters. It is asking what happens when the people around the data can help shape models without a full engineering pipeline.
What I like about this approach is that it connects usability with control. A simple interface on its own would not be enough. If anyone could upload anything and train anything then the result might be easy but not trustworthy. ModelFactory sits inside a broader OpenLedger structure where dataset permissions ownership integrity and attribution are treated as core ideas. Its architecture includes user management dataset access control a fine tuning engine a chat interface a RAG attribution module and evaluation and deployment tools. That matters because the no code layer is part of a system that tries to track where model inputs come from and how outputs remain connected to sources.
There is also a practical market angle but I would keep it sober. For builders the short term appeal is speed. They can move from dataset to experiment faster. They can test whether a focused model gives better answers for a specific task. For data contributors and dataset owners the question is different. They may care about whether their approved datasets can become active ingredients in models rather than passive files. For people watching the project from a market perspective the real signal would be evidence that useful datasets are entering ModelFactory and that builders are creating models people actually use.
The long term question is harder. A GUI can reduce friction but it cannot create quality by itself. Fine tuning still depends on clean data correct permissions sensible settings and serious evaluation. A model can be easy to train and still be weak. A dashboard can show progress and still not prove real world usefulness. This is the part I would not smooth over. ModelFactory makes the process more accessible but accessibility can become noise unless the ecosystem keeps pushing toward useful domain data and careful model testing.
The performance claims in the official material are worth noting but they should be handled carefully. OpenLedger says ModelFactory LoRA tuning reaches up to 3.7 times faster training speeds than traditional P Tuning in the referenced benchmark context and that QLoRA improves GPU memory efficiency through advanced 4 bit quantization. Speed and resource efficiency matter when teams are experimenting. Still I would not reduce the story to faster training. The more interesting point is whether faster training leads to more attempts and better specialized models.
My personal take is that ModelFactory is most meaningful as a bridge. On one side there are Datanets and permissioned domain datasets. On the other side there are models that need focused training before they can become useful in narrow tasks. Between them sits the builder experience. If that bridge is hard to cross then OpenLedger remains more theory than workflow. If the bridge works then the project has a stronger chance of turning verified data into actual AI utility.
I would watch whether the interface stays simple enough for non technical users while still giving serious builders enough control. I would also watch whether attribution and source transparency remain visible inside model testing and retrieval based outputs. Short term ModelFactory lowers the barrier to experimentation. Long term it has to prove that easier model creation can still produce trustworthy specialized AI. For me that is the real thesis. AI building may belong to people who can bring verified knowledge into a system that respects access provenance testing and attribution.
